


병행 수행
- 여러 사용자가 DB를 동시 공유할 수 있게 여러개의 트랜잭션을 동시에 수행하는 것
- 여러 트랜잭션이 차례로 번갈아 수행되는 인터리빙 방식으로 진행
(단위 시간에 많은 트랜잭션을 처리하기 위해)
(트랜잭션 제각각 처리 시간이 다르므로, 처리시간이 긴 연산 수행 동안 다른 연산 수행)
병행제어
- 병행 수행시, 같은 데이터에 접근하여 연산을 실행해도 문제가 발생하지 않고 정확한 수행 결과를 얻을 수 있게 트랜잭션 수행을 제어하는 것.
- 정확한 수행 결과가 아닌 경우가 발생하지 않게 병행제어를 잘 해야한다.
병행 수행 시 발생할 수 있는 문제점
1. 갱신 분실
- 하나의 트랜잭션이 수행한 데이터변경 연산의 결과를 다른 트랜잭션이 덮어서 변경연산 무효화됨
- 여러 트랜잭션이 동시에 수행되더라도 순차적으로 수행한것과 같은 결과값을 얻을 수 있어야된다.
=> T1에 대해 갱신 분실이 발생한다.

트랜잭션을 순차적으로 수행하면 해결된다.
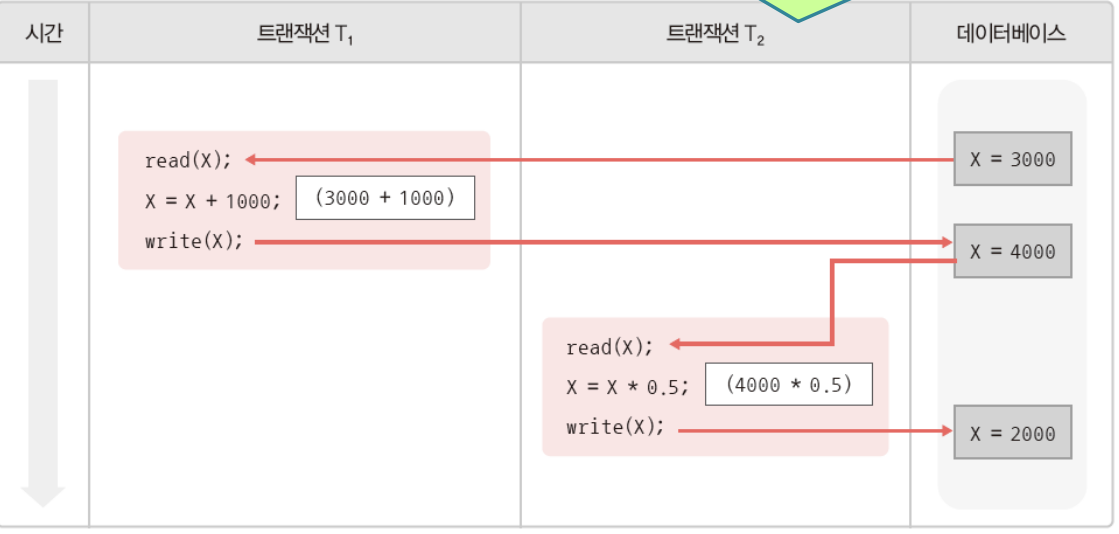
2. 모순성
- 하나의 트랜잭션이 여러 개 데이터 변경 연산을 실행할때, 일관성 없는 상태의 데이터베이스에서 데이터를 가져와 연산 => 모순된 결과가 발생
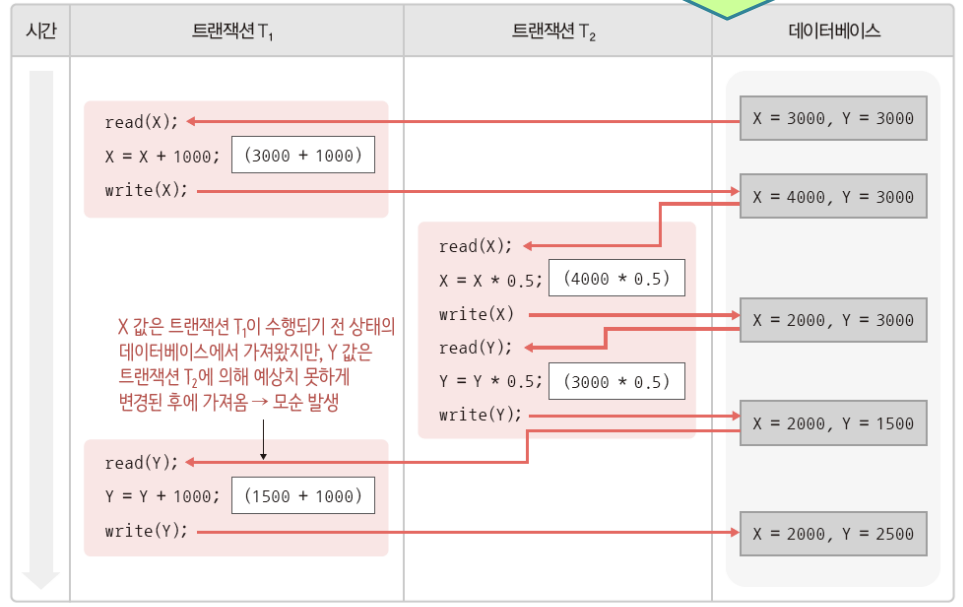
T1이 X, Y를 다른 상태의 데이터베이스에서 가져와
트랜잭션 T1의 결과가 X= 4000, Y = 4000이 아닌 X=2000, Y=2500의 잘못된 결과가 나온다.
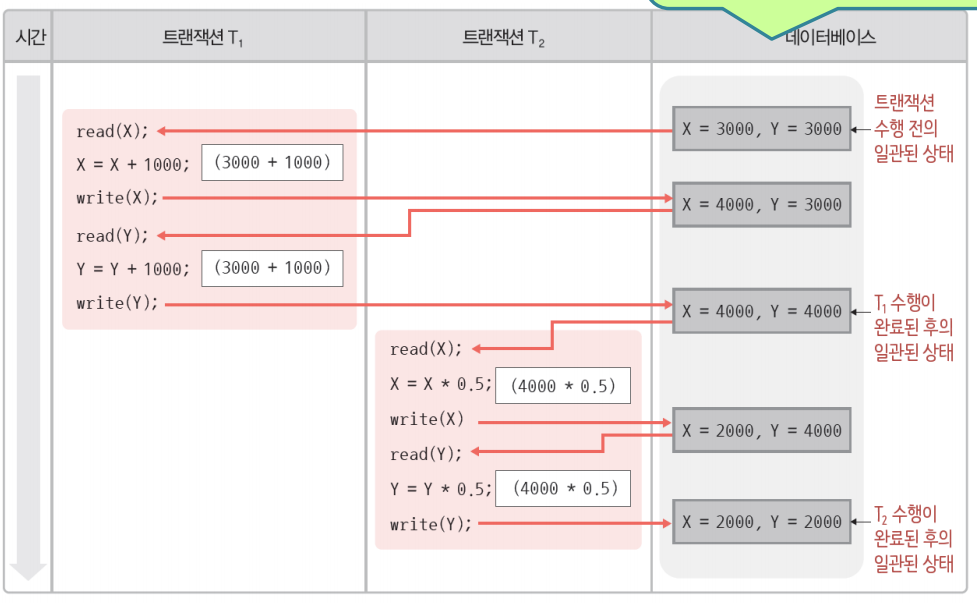
T1이 완료된후 T2가 실행되면 모순성 문제가 발생하지 않는다.
3. 연쇄복귀
- 트랜잭션이 완료되기전, 장애가 발생하여 rollback연산을 수행 => 장애 발생 전에 트랜잭션이 변경한 데이터를 가져가 변경연산을 실행한 다른 트랜잭션도 연쇄적으로 rollback연산을 해야함
==> 장애로 잘못된 결과가 나오고 그 잘못된 결과를 가져가 다른 트랜잭션이 연산을 수행했으므로
(T1 -> 결과(문제발생) -> T2 -> 결과(문제발생!, 잘못된 결과로 연산하였으므로)
T2는 T1이 변경한 X를 가져가 연산을 수행한다.
T1 트랜잭션 완료 전 장애가 발생한다.
T1을 rollback해야하지만, T2는 연산이 이미 끝나 rollback이 불가하다.

순차적으로 수행 (T1완료후 -> T2수행)하면 연쇄 복귀 문제가 발생하지 않는다.

트랜잭션 스케줄
1. 직렬 스케줄 => 인터리빙이 아닌, 각 트랜잭션별로 연산을 순차적으로 실행 => 시간이 길어짐
2. 비직렬 스케줄 => 인터리빙 방식으로 트랜잭션 병행해서 수행 => 병행성 문제 발생
3. 직렬 가능 스케줄 => 직렬스케줄처럼 정확한 결과를 생성하는 비직렬 스케줄 => 시간을 줄이고 병행성 문제 해결
1. 직렬 스케줄
- 다른 트랜잭션의 방해를 받지 않고 독립적으로 수행 => 항상 모순 없는 결과
- 병행 수행이 아님 => 시간이 오래걸림
- 다양한 직렬 스케줄을 만들 수 있음
T1 -> T2

T2 -> T1

2. 비직렬 스케줄
- 트랜잭션이 번갈아 연산 실행 => 하나의 트랜잭션 완료전 다른 트랜잭션 연산 실행가능
- 갱신분실, 모순성, 연쇄복귀 문제 발생하여 결과의 정확성 보장 X
- 다양한 비직렬 스케줄 생성가능 (그중엔 잘못된 결과를 생성하기도함)
비직렬 스케줄이지만 병행 수행에 성공하여 정확한 트랜잭션 수행 결과를 생성한다. => 직렬가능 스케줄
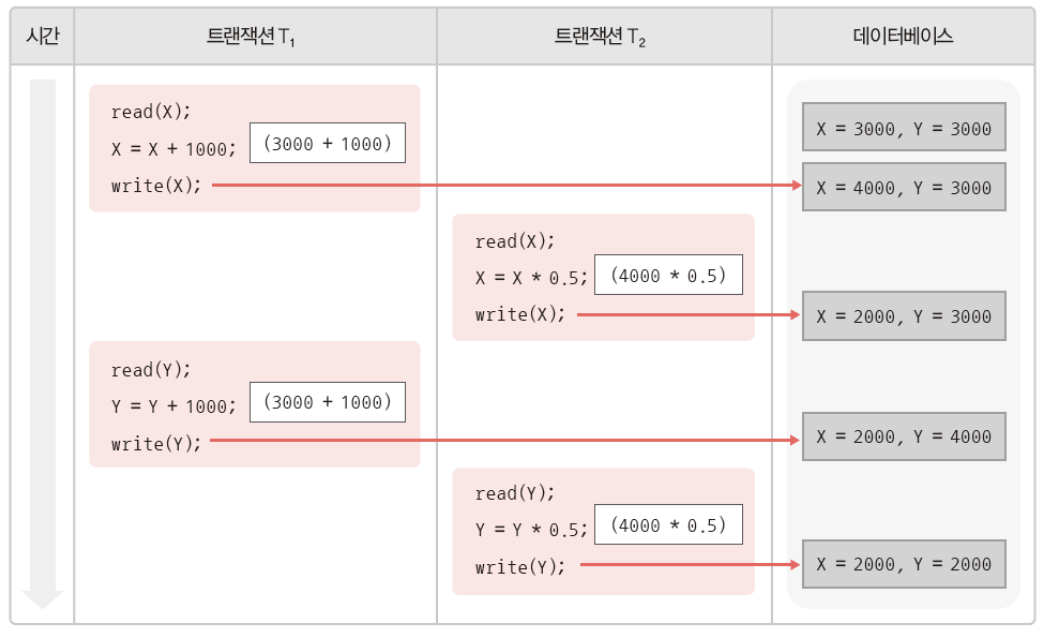
병생 수행에 실패하여 잘못된 결과를 생성한다.

3. 직렬 가능 스케줄
- 비직렬 스케줄 중에서 수행 결과가 동일한 직렬 스케줄이 있는 것.
- 인터리빙 방식으로 병행수행하면서 정확한 결과 얻음
- 직렬 가능 스케줄인지 판단한는것은 복잡한 작업
- 따라서 직렬가능성을 보장하는 병행제어 기법 사용

병행 제어 기법
- 병행 수행하면서 직렬 가능성도 보장
- 모든 트랜잭션이 준수하면 직렬가능성이 보장되는 rule 정의
- lock 기법이 있음
lock기법 - 상호배제
- 병행 수행되는 트랜잭션들이 같은 데이터에 동시에 접근하지 못하게 lock/unlock연산
lock - 트랜잭션이 데이터에 대한 독점권 요청
unlock - 트랜잭션이 데이터에 대한 독점권 반환
- 데이터에 접근하기 전 lock하여 독점권을 획득 (read/write 전 lock)
- 다른 트랜잭션에 의해 이미 lock이 걸린 데이터는 lock 불가& 실행 불가
- 연산 수행 끝나면 unlock
lock 단위가 커지면 병행성은 낮아지지만 제어가 쉬워지고
단위가 작아지면 제어가 어렵지만 병행성은 높아진다.
lock 효율 향상 => 동시성이 높아짐
공용 lock => read만 가능
- read연산 수행가능 ,write 불가
- 다른 트랜잭션도 동시에 공용 lock 가능
- 데이터 사용권을 여러 트랜잭션이 함께 가지는 것 가능
전용 lock => write하기 위해
- read/write 둘다 가능
- 다른 트랜잭션은 어떠한 lock 연산도 실행 불가
- 데이터에 대한 독점권 가짐
T1이 X에 대해 빨리 unlock을 해버려 T2가 일관성 없는 데이터에 접근하여 잘못된 결과가 나온다.
(T1이 끝날때까지 lock을 해야한다.)

2단계 lock rule = 축소, 확장
- 위와 같은 기본 lock rule의 문제 해결
- 직렬 가능성 보장 위해 lock/unlock연산 수행 시점에대한 새로운 rule 추가
- 트랜 잭션이 처음수행되면 확장단계 => lock만 가능 (lock을 검)
- unlock 연산을 실행하면, 축소단계 => unlock만 가능
- 트랜잭션은 첫번째 unlock 연산전, 필요한 lock 연산을 실행해야한다.
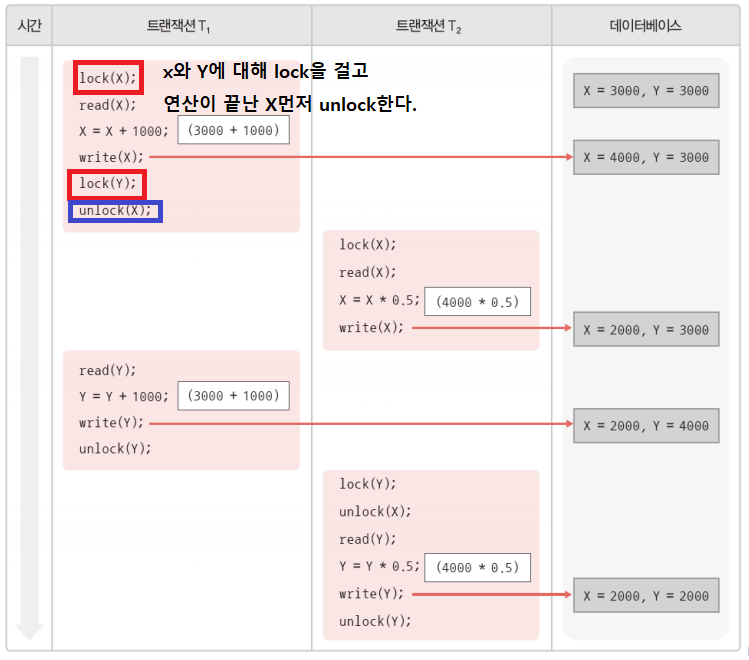
하지만 이러한 방법도
T1 -> X (lock) ====> Y가 unlock 되길 기다림
T2 -> Y (lock) =====> X가 unlock 되길 기다림
과 같은 경우 데드락이 발생 할 수 있다.
따라서 교착 상태가 발생되지 않게 예방하거나 빨리 탐지하여 조치를 해야한다.
'공부 > 데이터베이스' 카테고리의 다른 글
| 회복과 병행제어 - 회복 (0) | 2021.06.03 |
|---|---|
| 관계 대수 (0) | 2021.06.03 |
| 파이썬 연동 예제 (0) | 2021.06.02 |
| index (0) | 2021.06.02 |
| 데이터 베이스 보안 (0) | 2021.06.02 |

아상관없어