


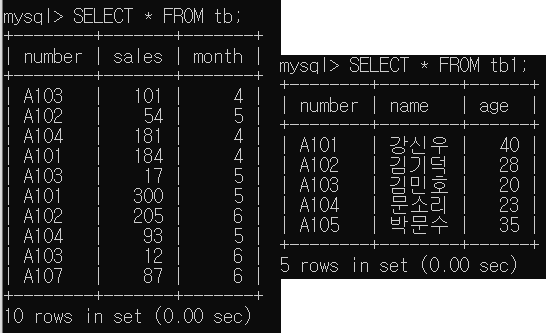
- 두개의 테이블 결합
SELECT 칼럼이름
FROM 테이블1
JOIN 결합할테이블2
ON 테이블1의 칼럼 = 테이블2의 칼럼
EX) tb의 sales 와 tb1의 name(두 테이블은 공통으로 number를 가짐)
SELECT * FROM tb
JOIN tb1 ON tb.number = tb1.number;
(number가 공통값이므로 공통키가됨)
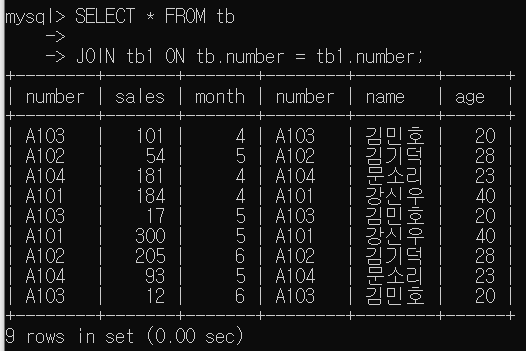
- 내부조인
일치하는 레코드만 가져오는 결합
EX)
SELECT * FROM tb
INNER JOIN tb1
ON tb.number=tb1.number;
(내부조인을 명시적으로 표시하려면 INNER JOIN으로 사용)

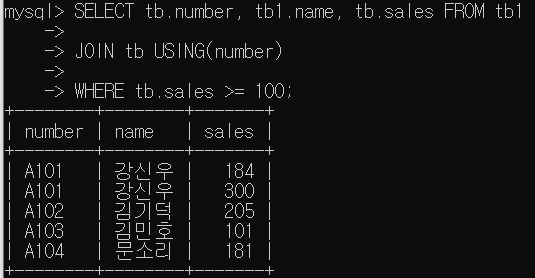
- 칼럼을 선택해서 표시
EX)
SELECT tb.number, tb1.name, tb.sales FROM tb
JOIN tb1 ON tb.number=tb1.number;

- 테이블 이름이 복잡할 경우 별명을 붙이고 사용
테이블 이름 AS 별명
EX)
SELECT x.number, y.name, x.sales FROM tb AS x
JOIN tb1 AS y
ON x.number = y.number;

- USING을 사용하여 ON 부분을 알기쉽게 표현
USING(키가 되는 칼럼 이름)을 이요하면 간단하게 표현가능
SELECT tb.number, tb1.name, tb.sales FROM tb
JOIN tb1ON tb.number=tb1.number;
||
SELECT tb.number, tb1.name, tb.sales FROM tb
JOIN USING (number);
- 결합한 테이블에 WHERE 조건 설정
WEHRE 조건을 설정하기 위해선 어느 테이블의 어떤 칼럼인지 명시해야한다.
EX) WHERE 테이블.칼럼 > 100
EX)tb에서 sales가 100이상 것에 한하여 tb1에서 name을 가져와 표시
SELECT tb.number, tb1.name, tb.sales FROM tb1
JOIN tb USING(number)
WHERE tb.sales >= 100;
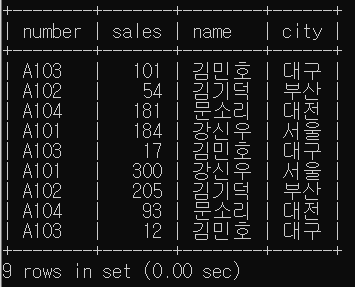
- 여러 테이블에서 데이터 추출
JOIN할 테이블 수에 제한이 없다.
SELECT ~ FROM 테이블이름1
JOIN 테이블이름2 결합조건
JOIN 테이블이름3 결합조건
JOIN 테이블이름4 결합조건
.......
EX)

tb, tb1, tb3는 공통 칼럼 number가 있다.
number를 키로 사용하여 number, sales, name, city 를 표시하면
SELECT tb.number, tb.sales, tb1.name, tb3.city FROM tb
JOIN tb1 USING(number)
JOIN tb3 USING(number);
혹은
SELECT tb.number, tb.sales, tb1.name, tb3.city FROM tb
JOIN tb1 ON tb.number=tb1.number
JOIN tb3 ON tb.number=tb3.number;
- 외부조인
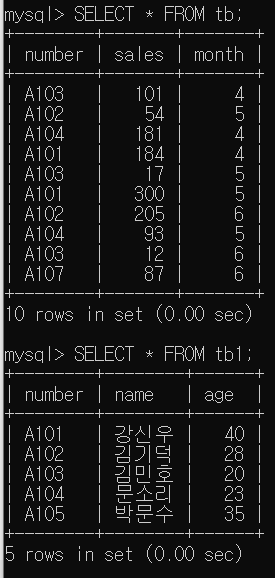
tb에는 tb1에 존재하지 않는 number 'A107'이 있다. 그리고 tb1에는 tb에 존재하지 않는 'A105'가 있다. 따라서
SELECT x.number, y.name, x.sales FROM tb as X
JOIN tb1 as y ON x.number=y.number;
할 경우 'A107'과 'A105' 레코드는 표시되지 않는다.
경우에 따라 모든 레코드를 표시해야할 경우에는 외부조인을 사용한다.
* 외부 조인의 종류
결합하는 레코드 중 어느 쪽의 레코드를 모두 표시할 것인가에 따라 LEFT JOIN, RIGHT JOIN으로 구분된다.
LEFT JOIN : 일치하는 레코드와 왼쪽 테이블의 모든 레코드를 표시
RIGHT JOIN : 일치하는 레코드와 결합할 오른쪽 테이블의 모든 레코드를 표시
- LEFT JOIN
SELECT 칼럼이름 FROM 테이블1
LEFT JOIN 결합할_테이블2 ON 테이블1의 칼럼 = 테이블2의 칼럼;
EX)
tb에는 있지만 tb1에는 존재하지 않는 number 'A107' 레코드 표함 표시
(tb, tb1을 number를 키로 LEFT JOIN해서 서로 일치하는 레코드와 tb의 모든 레코드를 표시)
(number와 name 만)
SELECT tb.number, tb1.name FROM tb
LEFT JOIN tb1 USING(number);
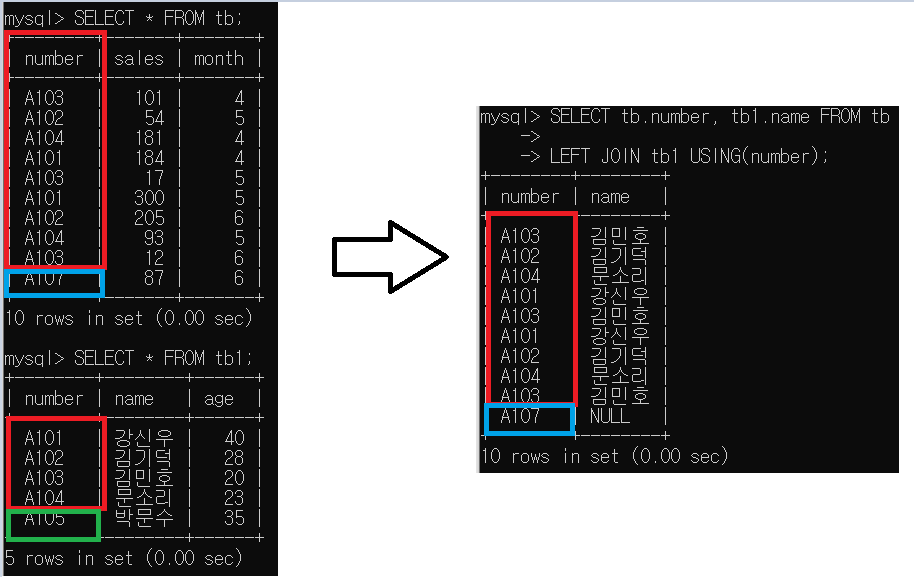
=> 'A105'는 표시되지 않는다. A107의 name 데이터가 존재하지 않기 때문에 NULL로 표시된다.
- RIGHT JOIN
일치하는 레코드와 결합할 오른쪽의 모든 데이터 표시
SELECT 칼럼이름 FROM 테이블1
RIGHT JOIN 테이블2(결합할) ON 테이블 1의 칼럼 = 테이블2의 칼럼;
혹은 (USING 칼럼이름)
EX)
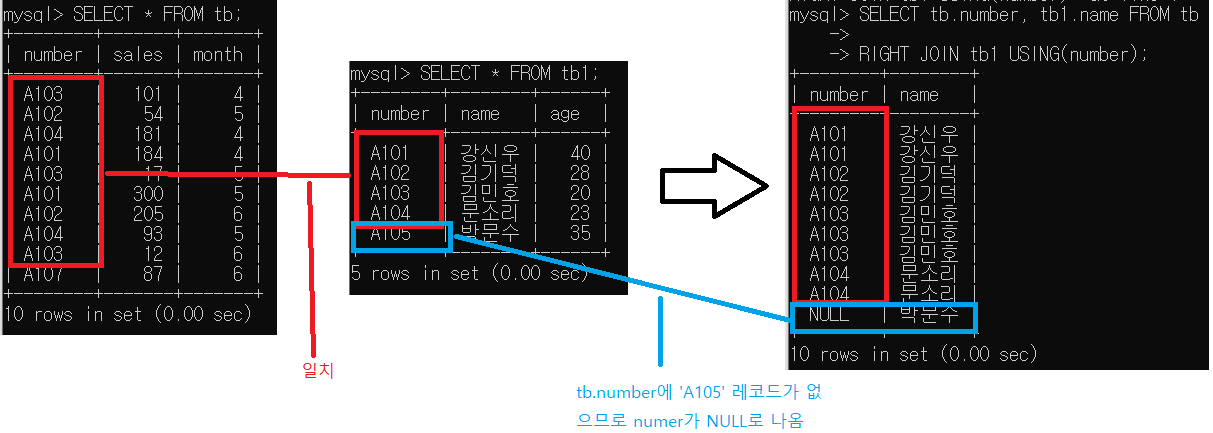
tb1에는 있지만 tb에는 없는 레코드 표시
tb의 number와 tb1의 name 표시
SELECT tb.number, tb1.name FROM tb
RIGHT JOIN tb1 USING(number);
- 셀프 조인
자기자신, 같은 이름의 테이블을 결합
같은 이름의 테이블을 결합하므로 같은 칼럼 이름이 2개씩 표시됨
SELECT 칼럼이름 FROM 테이블이름 AS 별명1 JOIN 테이블이름 AS 별명2;
EX) tb1을 셀프조인하고 모든 칼럼 표시
SELECT * FROM tb1 AS a JOIN tb1 AS b;
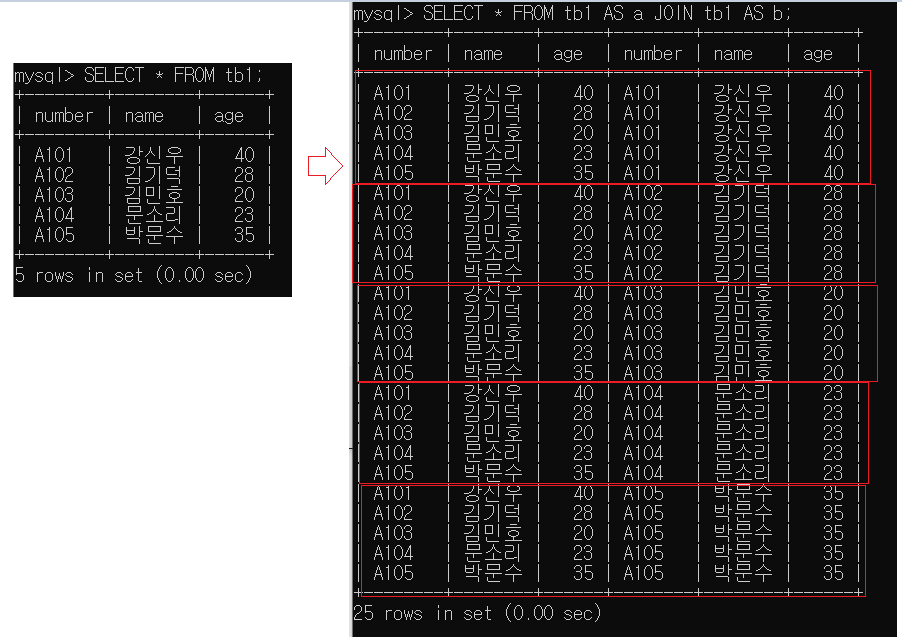
=> 모든 조합이 생김
모든 조합이 생기기때문에 조건을 설정하여 원하는 것만 선택하면된다.
EX) 순위 정하기
RANK와 같은 함수가 없으므로 ORDER나 GROUP 등의 조합으로 처리해야한다.
age 순으로 순위를 매긴다면
SELECT a.name, a.age, COUNT(*) AS 'RANK' FROM tb1 AS a
JOIN tb1 AS b
WHERE a.age <= b.age GROUP BY a.number;
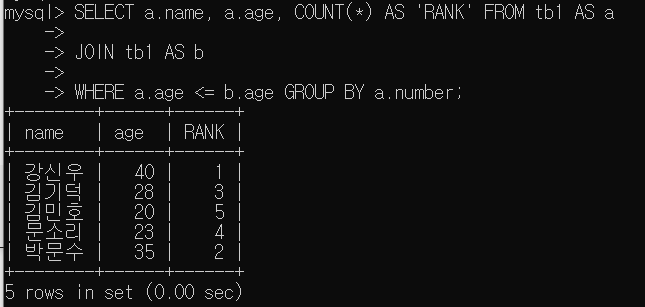
WHERE a.age <= b.age GROUP BY a.number => b.age가 a.age 이상인 레코드가 추출된다. 이렇게 추출된 레코드의 개수를 count하면 순위가 된다.

GROUP BY a.number를 하였으므로 A101, A102 ... 모두 비교한다.
A101의 경우 a.age<=b.age가 되는 경우는 첫줄의 경우 밖에 없으므로 count가 1이 된다.
- 하위 질의 = 서브쿼리
질의를 실행해서 추출한 데이터를 이용해서 다시 질의를 한다.
하위 질의를 사용하는 처리 대부분은 내부조인등으로 대체 할 수 있다. 하지만 단계별로 처리하는 하위질의를 사용하는것이 더 효율적이다.
EX 1)
tb테이블에서 칼럼 sales의 최대값이 잇는 레코드를 표시
SELECT * FROM tb WHERE sales IN (SELECT MAX(sales) FROM tb);
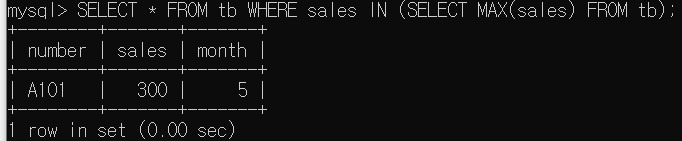

=> MAX(sales)인 sales가 있는 레코드를 SELECT 함
EX 2)
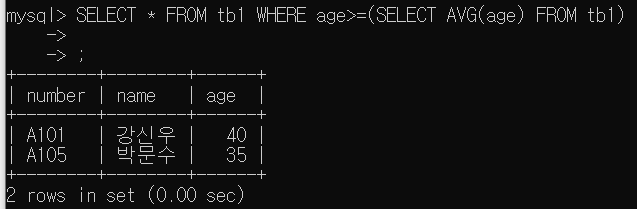
tb1에서 age 평균값을 계산하고 age가 평균값 이상인 레코드 표시
SELECT * FROM tb1 WHERE age>=(SELECT AVG(age) FROM tb1);
- 칼럼을 반환하는 하위 질의
SELECT 표시할 칼럼 FROM 테이블 이름
WHERE 칼럼이름 IN (SELECT 이용 하위 질의로 추출한 칼럼)
EX)
sales가 200 이상인 name을 표시
SELECT name FROM tb1 WHERE number IN (SELECT number FROM tb WHERE sales>=200);

- 하위 질의와 내부 조인의 실행 결과 비교
SELECT number, name FROM tb1
WHERE number IN (SELECT number FROM tb);

SELECT tb1.number, tb1.name FROM tb1
JOIN tb ON tb1.number=tb.number;
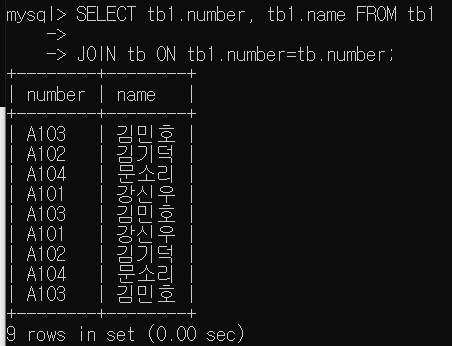
=> 내부 조인은 tb에 있는 모든 레코드를 표시함
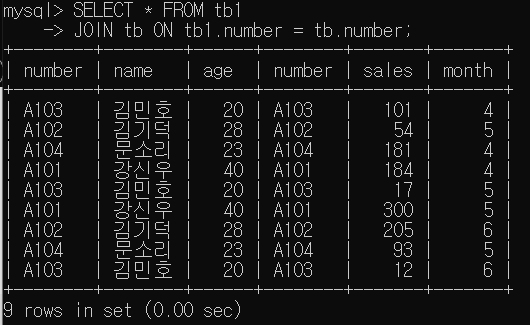
=> 모든 레코드를 표시함
* IN 대신에 등호를 사용하면 오류가 발생한다.
SELECT * FROM tb1 WHERE number = (SELECT number FROM tb WHERE sales>=200);

-> 하위 질의가 1건 이상 검색되었다라는 오류가 뜸
-> 해당 레코드가 1건 밖에 없을 때에는 등호를 사용해도 오류가 발생하진 않음
-> number가 xx와 정확하게 일치한다라는 조건이면 상관이 없지만, 위 예시는 여러 레코드가 추출되므로 ~중에 어느것 이라는 IN을 사용해야한다.
SELECT * FROM tb WHERE number = (SELECT number FROM tb1 WHERE sales>=200 LIMIT 1);
이렇게 하면 오류는 뜨진 않지만 A101이 나올지 A102가 나올지 알 수 없어서 결국 LIMIT도 도움이 되진 않는다.
LIMIT로 1건만 추출하기 때문에 오류가 발생하지 않는다.
- EXISTS = 존재하는 레코드를 대상으로 검색
EX) tb1에는 tb에 존재하지 않는 number를 가진 레코드도 포함되어있음.
SELECT * FROM tb1 WHERE
EXISTS (SELECT * FROM tb WHERE tb.number = tb1.number);

tb에는 A105의 number가 존재하지 않으므로 표시되지 않음
- NOT EXISTS
하위 질의로 추출되지 않는 레코드를 대상으로 함
EX)
tb 테이블에 존재하지 않는 레코드의 number만 추출하고 테이블 tb1에서 해당하는 레코드 표시
SELECT * FROM tb1
WHERE NOT EXISTS (SELECT* FROM tb WHERE tb.number=tb1.number);

- 순위 정하기(하위 질의 이용)
1. 연속 번호 기능을 설정한 테이블에 sales의 순서대로 정렬한 레코들 삽입한다.
2. 자동으로 입력되는 연속 번호가 순위가 된다.
구체적으로 적으면
1. 테이블 tb와 같은 구조의 테이블 tb_rank를 생성한다.
2. 테이블 tb_rank에 연속번호 기능을 설정한 칼럼 rank를 추가
3. 테이블 tb를 대상으로 sales의 순서대로 SELECT 하는 하위질의를 실행
4. 하위 질의의 결과를 tb_rank에 INSERT
1. CREATE TABLE tb_rank LIKE tb;
(tb의 칼럼 구조만 복사하여 tb_rank생성)
2. ALTER TABLE tb_rank ADD rank INT AUTO_INCREMENT PRIMARY KEY;
(tb_rank에 연속번호기능을 설정한 rank 칼럼 추가)
3. INSERT INTO tb_rank (number, sales, month) (SELECT number, sales, month FROM tb ORDER BY sales DESC);
(tb를 sales의 내림차순으로 정렬하고 number, saels, month를 tb_rank에 추가한다.)
'공부 > 데이터베이스' 카테고리의 다른 글
| 데이터베이스 예제 2 (0) | 2021.04.20 |
|---|---|
| 데이터베이스 예제 1 (0) | 2021.04.19 |
| 정리 (0) | 2021.04.19 |
| 파일 사용 (0) | 2021.04.14 |
| 트랜젝션 (0) | 2021.04.14 |

아상관없어