


- Software Security가 중요한 이유?
Software는 종류가 다양하고,
----------------------------------------------------------------------------------
Systems software : OS, compiler, loader
Business software : Payroll, accounting
Scientific and engineering software
Computer-aided design, simulation, weather prediction, …
Internet software: B2C: business-to-customer (e.g., amazon.com)
Facebook, Google Chrome, …
PC software : Spreadsheets, word processing, games, …
Embedded software
Cars, microwave ovens, cable boxes, light switches,
“smart dust”, …
Mobile applications
----------------------------------------------------------------------------------
컴퓨터 보안의 많은 것들은 SW로 구현이 된다.
알고리즘, access control 등 대부분이 SW로 구현되기 때문에 Software Security가 중요하다.
따라서 구현할 때 쓰는 sw가 취약하면 의미가 없으므로, SW가 취약하면 보안은 무조건 깨진다.
만약, 강력한 암호 알고리즘을 도입한다해도 구현하는 SW가 문제 있다면 그 보안은 의미가 없을 것이다.
따라서 SW는 빈약한 보안의 기초가 될 수 있다.
(SW가 빈약하면 보안 자체의 기초가 흔들린다.)
* Software 위기의 원인
- 예산 초과
- 시간 초과
- 비효율적인 SW
- 저품질의 SW
- 때때로 요구사항을 만족 못함
- 관리불가(유지보수가 힘듬 (코드가 복잡하므로))
- 원하는 결과를 내놓지 않음 or 소스코드를 넘겨주지 않음(문제 확인이 어려움)
이러한 문제를 해결하기 위해 Software Engineering이 나오게 되었다.
* Software
Software는 실행가능한 프로그램이고, 소스코드, 라이브러리, 문서(유저 요구사항, 실제 명세서, 가이드/메뉴얼 등)이다.
그 중 핵심 기능은
데이터를 처리, 전송, 저장하는것이고
정보를 생산, 관리, 드러내는 것이다.
* Bugs, Defects, Weaknesses, and Vulnerabilities
----------------------------------------------------------------------------------
Improper initialization
Side effects
Scoping
Operator precedence
Divide-by Zero
Infinite loop
Type confusion (illegal downcasts)
Deadlock
Integer Overflow / Underflow
Memory leak
Use-after-free
Buffer overflow = Buffer overrun
Time-of-check-to-time-of-use flaw
Format string bug
----------------------------------------------------------------------------------
위와 같이 다양한 종류가 있다.
취약점 보단 덜 위험하지만 문제를 일으킬 수 있다.
- bug와 취약점의 차이
bug : 의도치 않은 방향으로 잘못 행동하는 프로그램 내의 결함이다.
취약점 : bug 중에서도 공격자에 의해서 악용될 수 있는 것, 공격자가 접근할 수 있어야하고 공격자가 공격할 능력이 있어야하고 시스템 내에서 결함이 있어야한다.
SW Bugs 예시)
-------------------------------------------------------------
(초기값)
typedef unsigned int uint;
int getmin(int *arr, uint len){
int min;
for(int i=0;i<len;i++)
min = (min < arr[i]) ? min : arr[i];
return min;
}min에 대한 초기값이 설정되어 있지않아 정상적으로 실행되지 않을 수 있다.
inn min = 0과 같이 초기 값을 설정해주면 된다.
(side effects)
if(foo == 12 || (bar = 13))
baz == 12;bar = 13은 항상 참이다.
foo와 baz의 값이 선언되어있지 않고 비교되고 있다.
(범위)
int a;
void calc(int b){
int a = b*12;
if(b+24 == 96)
a = b;
}
printf("a=%d\n", a);=> 전역변수, 지역변수 둘다 a로 선언하여 모호하다.
=> calc함수내의 a는 함수가 종료되면 없어지므로 전역변수 a의 값이 출력된다.
(control flow)
int x,y;
for(x=0;x<xlen;x++)
for(y=0;y<ylen;y++);
pix[y*xlen + x] = x*y;
두번째 for문에 ;처리하여 원하는 결과가 출력되지 않는다.
if (isbad(cert))
goto fail;
if (invalid(cert))
goto fail;
goto fail;
L10 : printf("Hello, world\n");
goto L10goto fail;
goto fail;
을 하면 if문을 통과하고 두번째 goto fail이 항상 실행된다.
goto를 잘 못 사용하면 무한루프(L10으로 계속 이동)에 걸릴 수 있다.
(control flow - loop)
float x = 0.1;
while(x!=1.1){
x=x+0.1;
printf("X=%f\n", x);
}부동 소수점은 ==으로 비교하면 안된다.
실수는 무한히 많은데 이 실수를 유한 개의 비트로 표현하기 위해서는 근삿값으로 표현해야 하기 때문이다. =>부동소수점 반올림 오차
#include <stdio.h>
#include <float.h> // float의 머신 엡실론 값 FLT_EPSILON이 정의된 헤더 파일
#include <math.h> // float의 절댓값을 구하는 fabsf 함수를 위한 헤더 파일
int main()
{
float num1 = 0.0f;
float num2 = 0.1f;
// 0.1을 10번 더함
for (int i = 0; i < 10; i++)
{
num1 = num1 + num2;
}
// num1: 1.000000119209290
if (fabsf(num1 - 1.0f) <= FLT_EPSILON) // 연산한 값과 비교할 값의 차이를 구하고 절댓값으로
// 만든 뒤 FLT_EPSILON보다 작거나 같은지 판단
// 오차가 머신 엡실론 이하라면 같은 값으로 봄
printf("true\n"); // 값의 차이가 머신 엡실론보다 작거나 같으므로 true
else
printf("false\n");
return 0;
}FLT_EPSILON(머신 엡실론)을 사용해서 오차를 감안하여 실수를 비교해야한다.
어떤 실수를 가장 가까운 부동소수점 실수로 반올림하였을 때 상대 오차는 항상 머신 엡실론 이하이다.
머신 엡실론은 반올림 오차의 상한값이며 연산한 값과 비교할 값의 차이가 머신 엡실론보다 작거나 같다면 두 실수는 같은 값이라 할 수 있다.
double, long double을 사용한다면 머신 엡실론은 DBL_EPSILON, LDBL_EPSILON을 사용한다.
1. 연산한 값과 비교할 값의 차이를 구한다.
(값의 차이는 math.h 헤더 파일의 fabsf 함수를 사용하여 절댓값으로 만드므로 차이가 음수여도 상관없다.)
2. FLT_EPSILON 보다 작거나 같은지 판단
3.연산한 값과 비교할 값의 차이가 머신 엡실론보다 작거나 같다면 두 실수는 같은 값이라 판단
(control flow - loop)
int k = 1
int val = 0;
while (k = 10) {
val++;
k++;
}
printf (“k = %d, val = %d \n”, k, val);while(k=10)
k=10은 항상 참이므로 무한 루프가 된다.
(Null pointer 역참조)
int *ptr = NULL;
printf(“Value of ptr: %d\n”, ptr);
int *p = 0; //NULL 대입
*p = 1; //NULL 포안터 역참조, 주소 0에 접근하는 포인터생성후 값 할당 시도함
/* -------------------------------------*/
int length;
char *buff;
scanf (“%d”, &length);
buff = (char *) malloc(length+1); // always Not NULL?
strcpy(buff, “Hello World! Welcome!”);첫번째 코드는 포인터 변수 P에 NULL을 대입하고 주소가 0인 포인터에 값을 할당하려하였다.
따라서 세그멘테이션 결함이 발생한다.
if(p==NULL){
exit(1);
}
과 같이 NULL 포인터를 체크해주어야한다.
두 번째 코드는
malloc시 시스템에 메모리가 부족하거나 메모리 할당 조건이 맞지않아 메모리 할당을 하지 못하면 null을 반환하게 된다. 따라서 buff에 null 포인터가 들어가게된다. 따라서 malloc이 null을 반환하였는지 체크하여야한다.
void Pointer(int *ptr) {
*ptr = *ptr + 5;
}
main(void) {
int num = 10;
Pointer(&num);
Pointer(NULL);
}
Pointer(NULL)
null을 인자로 넘겨주면 Pointer함수에서 null에 값을 대입하려하여 null 포인터 역참조 에러가 발생한다.
(연산자 우선순위)
node *find(node **curr, val){
while(*curr != NULL)
if(*curr->val == val) return *curr;
else
*curr = *curr->next;
}
(*curr)->val로 하여야한다.
#include<stdio.h>
void main(){
int x,a,b,c,d,e,f;
a=7;b=6;c=5;d=4;e=3;f=2;
x = a&b+c*d&&e^f==7;
printf("X = %d\n", x);
}
x = 1
연산자 우선순위는
(*) -> (+) -> (==) -> (&) -> (^) -> (&&)
이다.
따라서
(a&(b+(c*d)))&&(e^(f==7))가 된다.
(a&(b+(c*d))) => 7&(6+(5*4)) = 20&7 (10100 & 00111) => 100(2) = 4
(e^(f==7)) => 3^(2==7) => 11 xor 00 = 11(2) => 3
3&&4는 참이므로 1이된다 (3과 4는 참이므로)
따라서 x에는 1이 들어가게된다.
(Integer Security)
char cresult, c1, c2, c3;
c1 = 100; c2 = 90; c3= -120
cresult = c1 + c2 + c3;
printf(“%c, %d, %c, %d\n”, cresult, cresult, c3, c3);changmin@ubuntu:~/Desktop/c$ ./d
F, 70, �, -120
char형은 8비트이다.
c1+c2=190에서 char범위를 벗어난다.
임시적인 정수 승격으로 c1, c2, c3는 int형으로 변환되고
(임시적인 정수승격 : 일반적으로 CPU가 처리하기에 가장 적합한 크기의 정수 자료형은 int형이다. 즉, int형 연산의 속도가 다른 자료형의 연산속도에 비해서 동일하거나 더 빠르다. 따라서, int보다 작은 크기의 정수형 데이터는 int형 데이터로 형 변환이 되어서 연산된다.)
계산이 끝난뒤에 값이 잘리게 된다.
따라서 c1+c2+c3는 70이된다.
char 범위는 -128~127이므로 70이 출력된다.

short s1 = 32000;
short s2 =1500;
s1 = s1 + s2;
printf("%h, %d\n", s1, s1);changmin@ubuntu:~/Desktop/c$ ./e
%, -32036
(%h =>short 형으로 출력, invalid conversion specifier -Wformat-invalid-specifier 라고 되는데 %h 형식을 지원하지 않는듯 하다..... short형은 %hd를 사용해야하는 것 같다.)
32000+1500은 short범위를 벗어나므로 오버플로우가 발생한다.
(out-of-bounds write)
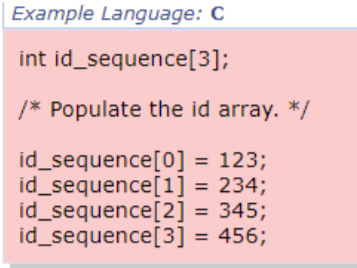
배열의 크기를 벗어나거나

memcpy시 마지막 인자가 unsigned int형으로 변환되면서 언더플로우가 발생될 수 있다.
(returnChunckSize(desBuf)의 반환값이 -1일때 -1-1은 -2가 되고 unsigned int로 변환시 언더플로우발생으로 매우 큰수가 된다.)
'공부 > 보안' 카테고리의 다른 글
| Data type, Array operations, Byte ordering (0) | 2021.04.28 |
|---|---|
| MyEtherWallet 해킹사건 분석 (0) | 2021.04.18 |
| INT OVERFLOW/UNDERFLOW (2) - 부호버그(Signedness Bugs) (0) | 2021.04.15 |
| Int Overflow/Underflow(1) - 예시, 예방법 (0) | 2021.04.15 |
| 보안개론 정리(1) (0) | 2021.04.13 |

아상관없어