


Basic Data Types
- Integral
| intel | GNU assembler | bytes | c |
| byte | b | 1 | [unsigned] char |
| word | w | 2 | [unsigned] short |
| double word | l | 4 | [unsigned] int |
| quad word | q | 8 (컴퓨터마다 다름 4 or 8) | [unsigned] long int (x86-64) |
- Floating point
| intel | GNU assembler | bytes | c |
| single | s | 4 | float |
| double | l | 8 | double |
| extended | t | 10/12/16(system, os, complier 마다 다름) | long double |
배열의 할당
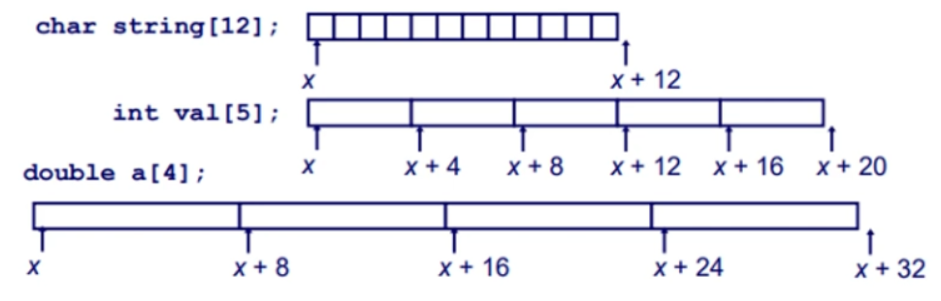
char 배열의 주소 크기는 1 byte
int 배열의 주소 크기는 4byte (한 원소당 4byte를 차지하므로)
double 배열의 주소 크기는 8byte
-포인터 배열
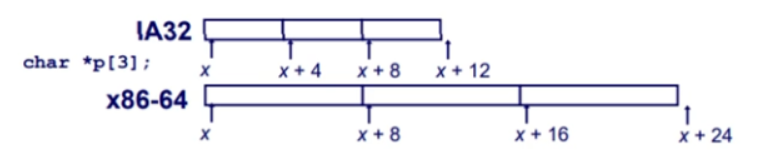
32bit 구조는 address bus가 4byte이므로 주소도 4byte
64bit 구조는 address bus가 8byte가 가능하다. 하지만 8byte는 큰 공간이므로 메모리 낭비라고 생각하여 6byte씩 표현하는 경우도 있다.
Array operations
예시
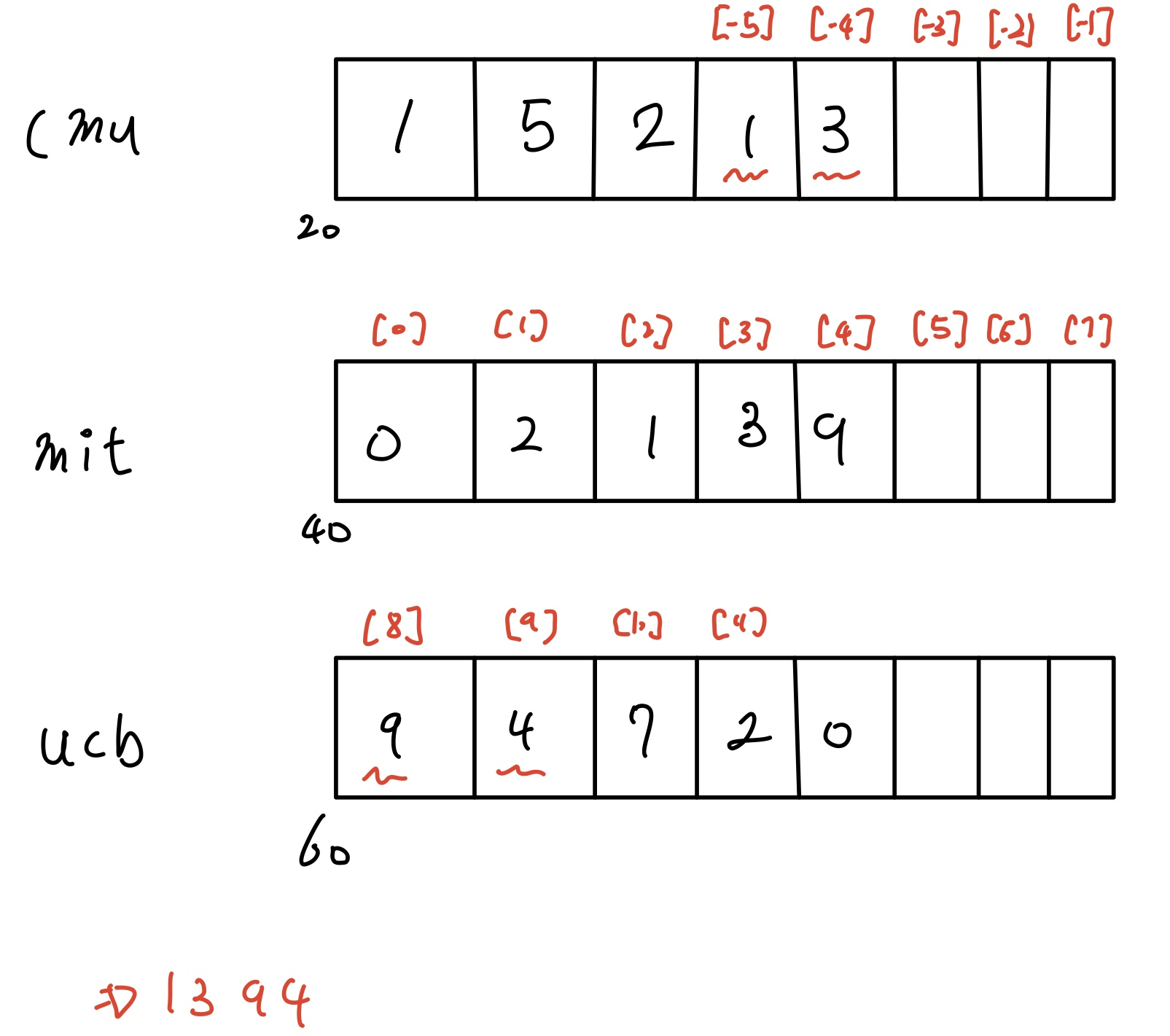
int val[5];
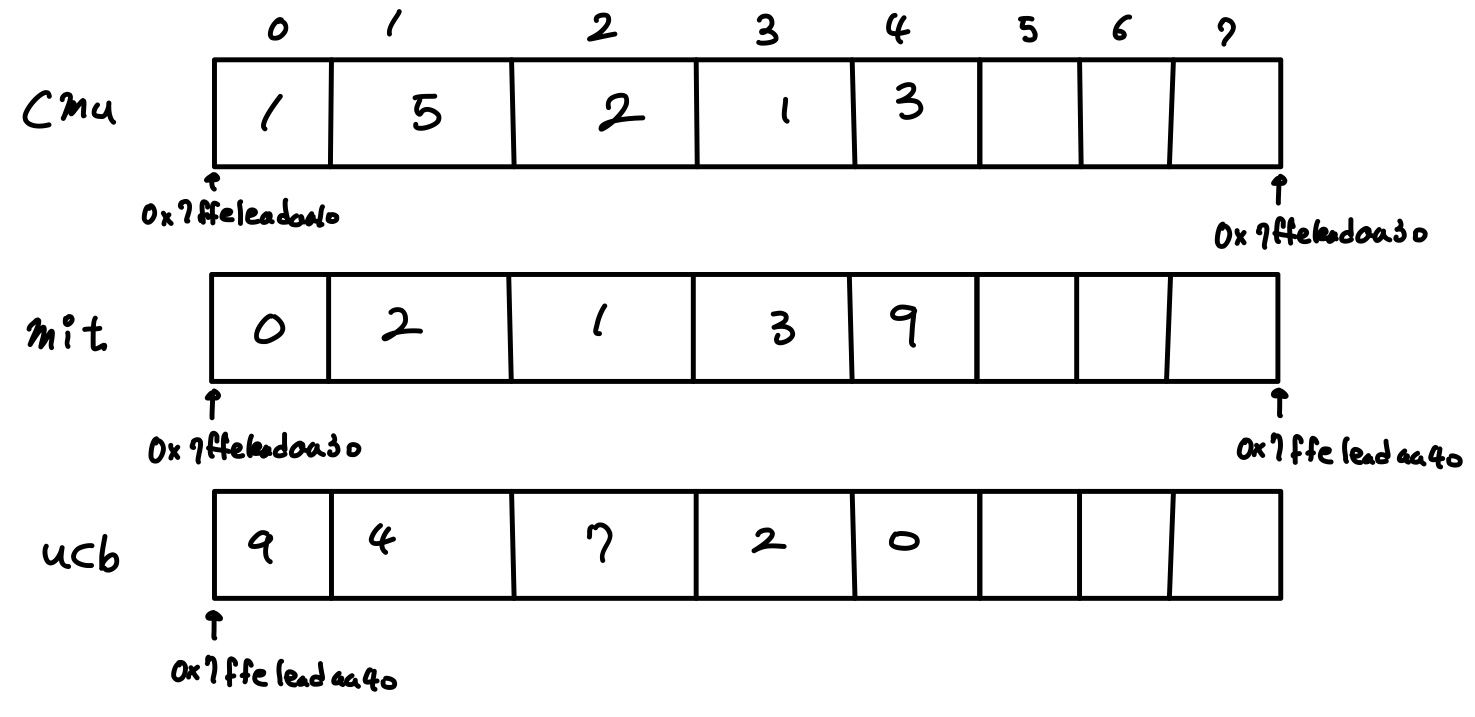
| 1 | 5 | 2 | 1 | 3 |
주소 : x -> x+4 ->x+8 ->x+12->x+16
val[4] = 3
val = x
val+1 =x+4
&val[2] = x+8
val[5] = ?
*(val+1) = 5
val +i = x+4i
예시1)
#include <stdio.h>
typedef int zip_dig[5];
int main() {
zip_dig cmu = {1, 5, 2, 1, 3};
zip_dig mit = {0, 2, 1, 3, 9};
zip_dig ucb = {9, 4, 7, 2, 0};
printf("%p \n", cmu);
printf("%p \n", mit);
printf("%p \n", ucb);
/*-----------------------------------*/
printf(“%d, ”, cmu[8]);
printf(“%d, ”, cmu[11]);
printf(“%d, ”, ucb[-5]);
printf(“%d\n”, ucb[-15]);
}
(32bit로 컴파일)

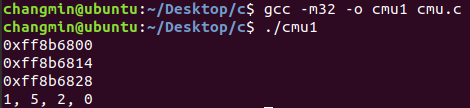
stack protector가 설정되어있으므로 낮은 주소부터 할당이 된다.
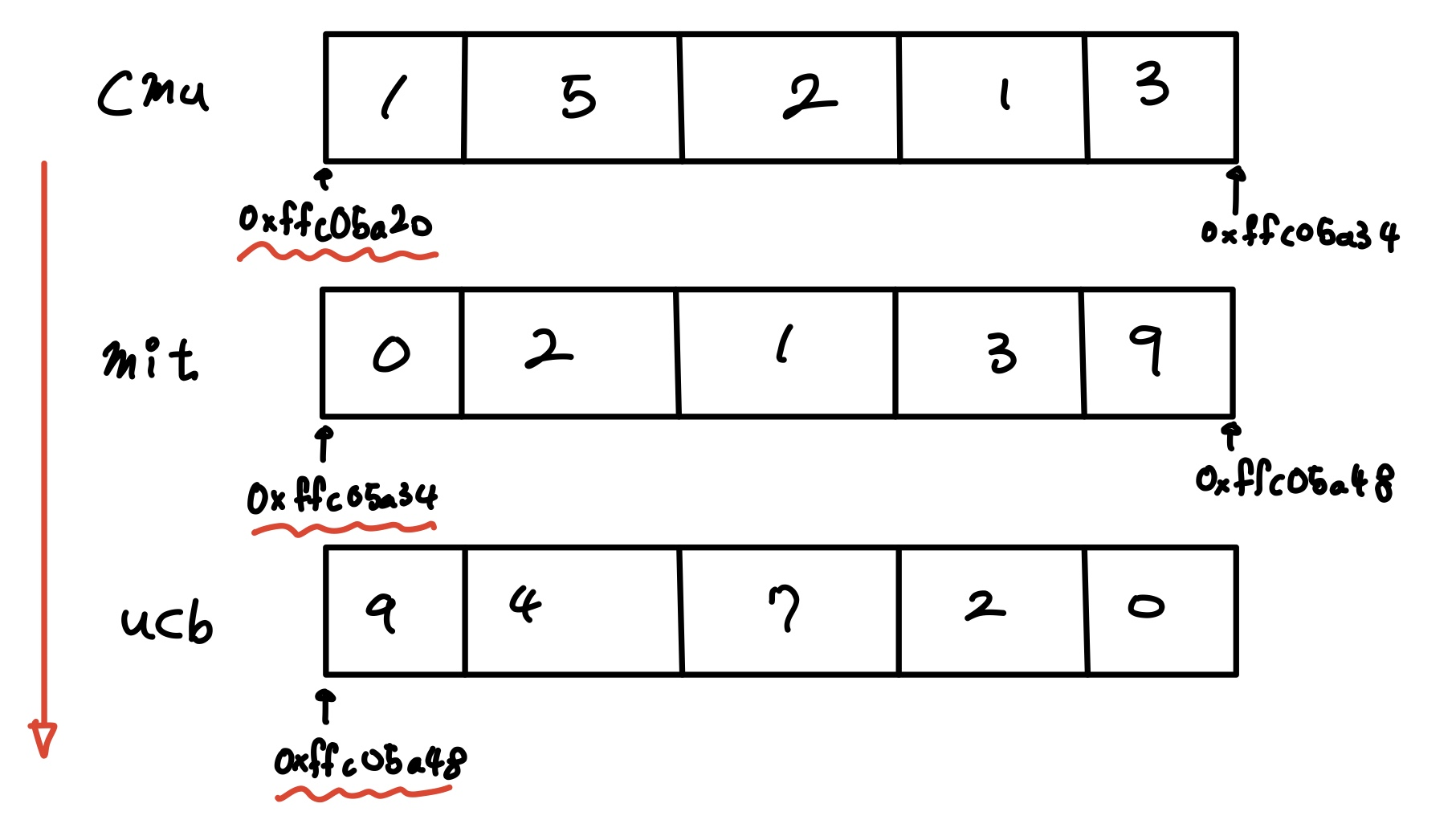
연속으로 배열이 할당이되고 낮은 주소부터 할당이 되는 것을 알 수 있다.
0x14 =>20byte 만큼 주소가 차이난다.
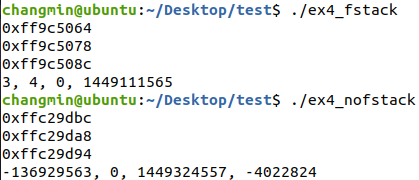
-fstack-protector을 하면 64->78->8c로 스택이 자라고
-fno-stack-protector을 하면 bc -> a8 -> 94로 낮은주소로 스택이 자란다.
(64bit로 컴파일)
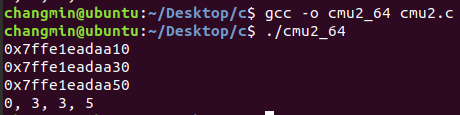
주소체계도 다르고, 0x20만큼 주소가 차이나는 것을 알 수 있다. 32byte만큼 주소차이가 난다.
(오타, 0x7ffe1eadaa40이 아니라50이다....)
예시 2)
#include <stdio.h>
typedef int zip_dig[5];
int main() {
zip_dig cmu = {1, 5, 2, 1, 3};
zip_dig mit = {0, 2, 1, 3, 9};
zip_dig ucb = {9, 4, 7, 2, 0};
printf("%p \n", cmu);
printf("%p \n", mit);
printf("%p \n", ucb);
printf("%d, %d, %d, %d\n",mit[-5], mit[-4], mit[8], mit[9]);
}
(stack proctector)
=>
0x20만큼 주소가 차이남 (5개의 원소)
(no stack protector)

=>
-fno-stack-protector(스택 보호기법 해제) -> 높은위치에서 낮은 위치로 성장
5c -> 48 ->34
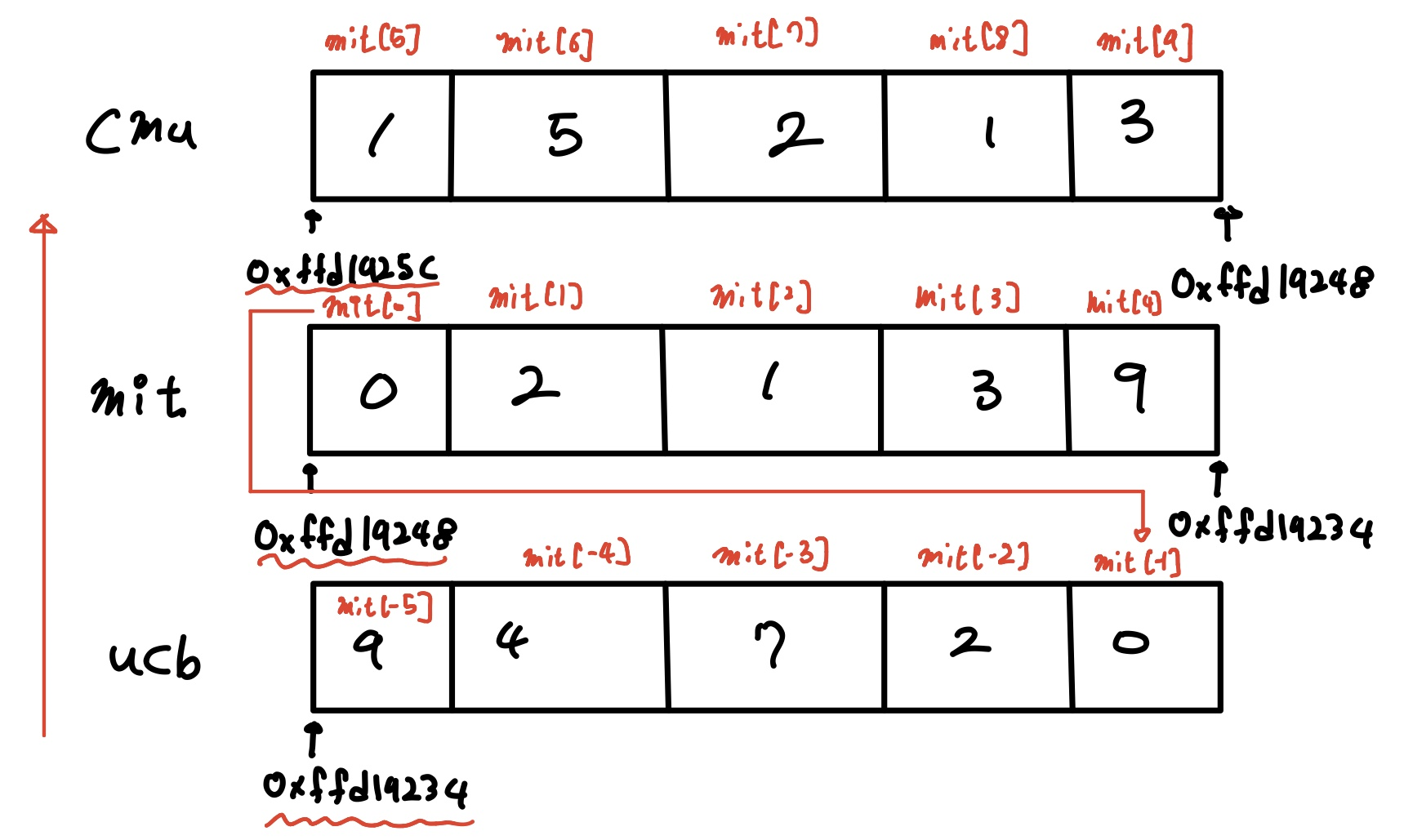
주소체계와 접근하는 방식이 달라짐!
(64bit의 경우)

(64bit no stack protector)


예시 3)
#include <stdio.h>
typedef int zip_dig[5];
int main() {
zip_dig cmu = {1, 5, 2, 1, 3};
zip_dig mit = {0, 2, 1, 3, 9};
zip_dig ucb = {9, 4, 7, 2, 0};
printf("%p \n", cmu);
printf("%p \n", mit);
printf("%p \n", ucb);
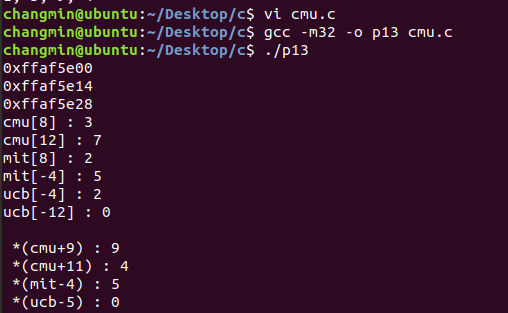
printf("cmu[8] : %d \n", cmu[8]);
printf("cmu[12] : %d \n", cmu[12]);
printf("mit[8] : %d \n", mit[8]);
printf("mit[-4] : %d \n", mit[-4]);
printf("ucb[-4] : %d \n", ucb[-4]);
printf("ucb[-12] : %d \n", ucb[-12]);
printf("\n");
printf(" *(cmu+9) : %d \n", *(cmu+9));
printf(" *(cmu+11) : %d \n", *(cmu+11));
printf(" *(mit-4) : %d \n", *(mit-4));
printf(" *(ucb-5) : %d \n", *(ucb-5));
}
예시 4)
#include <stdio.h>
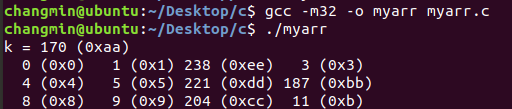
void main() {
int k = 100;
int a[4] = {0, 1, 2, 3};
int b[4] = {4, 5, 6, 7};
int c[4] = {8, 9, 10, 11};
a[-1] = 0xAA;
a[7] = 0xBB, a[10] = 0xCC;
c[-2] = 0xDD, c[-6] = 0xEE;
printf("k = %d (0x%x)\n", k, k);
for(int i=0; i<12; i++) {
printf ("%3d (0x%x) ", a[i], a[i]);
if ((i+1) % 4 == 0) printf ("\n");
}
}
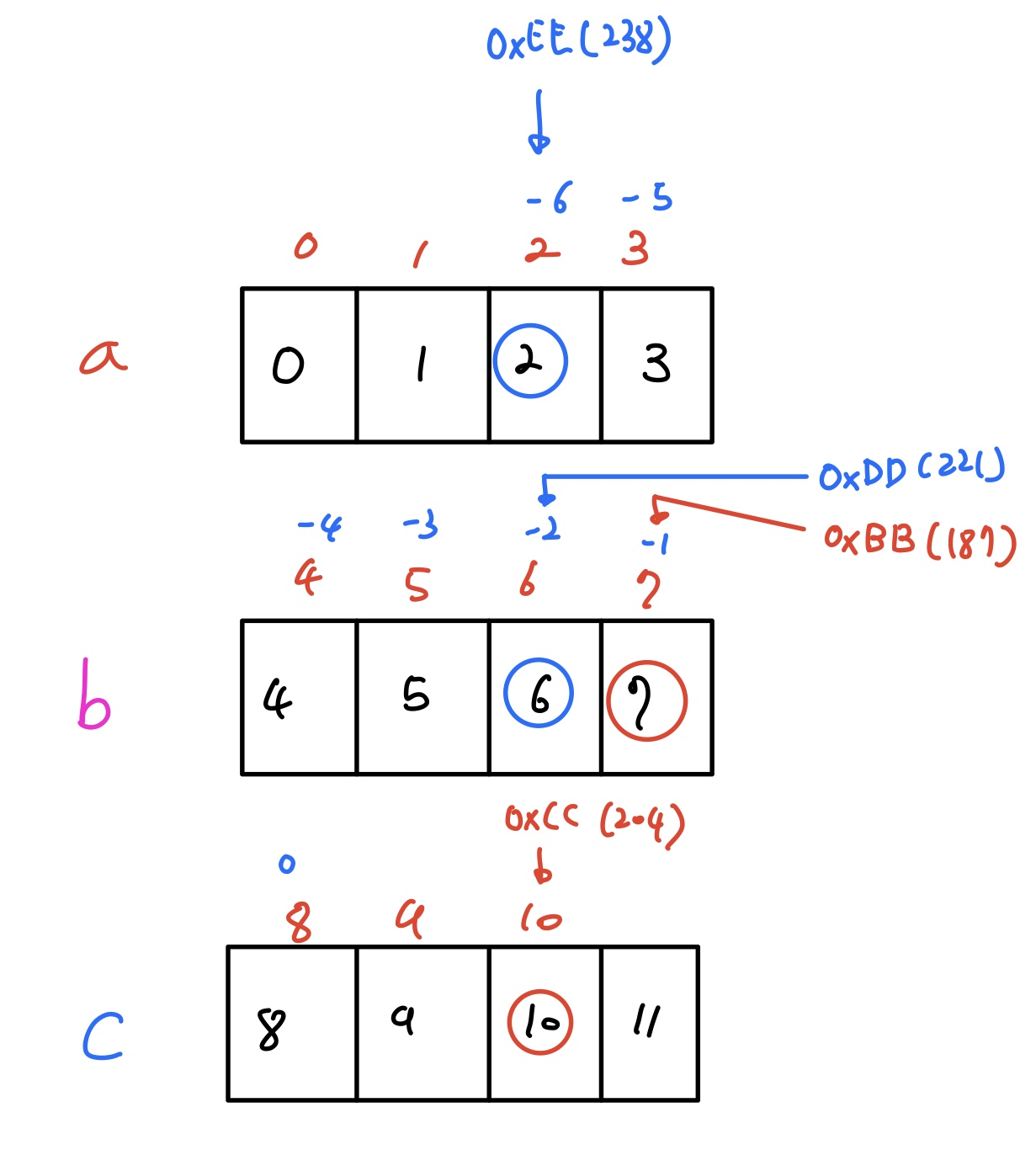
=> 인덱스에 음수가 가능
=> 인덱스가 본래 의미한 것보다 더 큰 값도 가능(다른 위치도 배열의 인덱스로 접근가능)
따라서 c는 메모리 관련 취약점이 많음
(64bit)

(64bit stack보호 기법해제)

Byte ordering
=> 취약점을 분석할때 컴퓨터 구조에 맞는 데이터를 투입해야하므로 알아야함
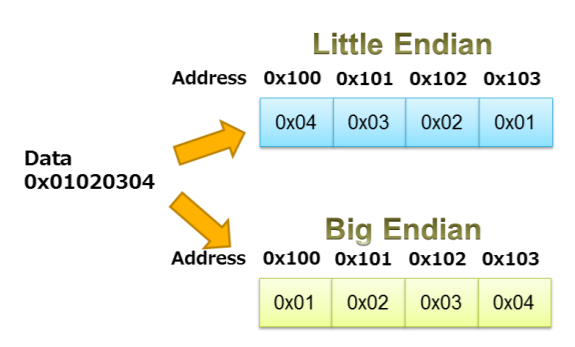
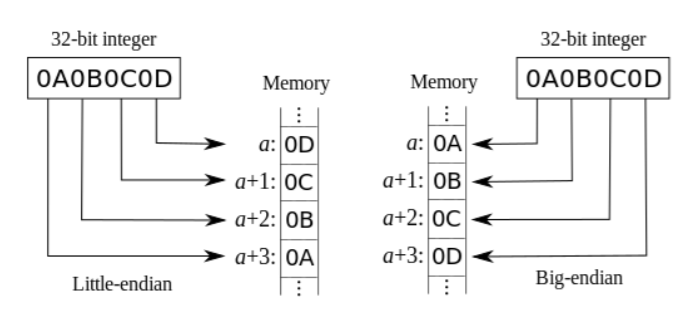
little endian은 최소 유효 byte가 낮은 주소를 차지한다.
big endian은 최소 유효 byte가 높은 주소를 차지한다.
type별 크기

=> big/little endian에 따라 c[0]이 낮은주소/높은주소 일 수 있다.
'공부 > 보안' 카테고리의 다른 글
| BOF 원정대 level 18 (0) | 2021.05.03 |
|---|---|
| 간단한 버퍼 오버플로우 (0) | 2021.04.28 |
| MyEtherWallet 해킹사건 분석 (0) | 2021.04.18 |
| 보안개론 정리(2) - software 취약점 (0) | 2021.04.16 |
| INT OVERFLOW/UNDERFLOW (2) - 부호버그(Signedness Bugs) (0) | 2021.04.15 |

아상관없어