


요구사항
- train set 으로 학습, validation 은 val set 이용, test set 으로 테스트 accuracy 도출
- 자신만의 deep neural network을 설계하여 문제를 해결 할 것
(전이학습 모델 이용하면 안됨)
모델 개선 과정
----------------------------------------------------------------------------------------------------
먼저 데이터를 X_train/y_train, X_test/y_test, X_val, y_val로 나누어 학습을 진행하였습니다.
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import Flatten
from keras.layers.convolutional import Convolution2D
from keras.layers.convolutional import MaxPooling2D
from keras.utils import np_utils
import numpy as np
import matplotlib.pyplot as plt
import os
import cv2
from tensorflow.python.keras.preprocessing.image import ImageDataGenerator
from tensorflow.python.keras.preprocessing.image import load_img, img_to_array
import numpy as np
from pathlib import Path
import glob
import pandas as pd
from skimage.io import imread # reading image as data
data_dir = Path('chest_xray')
train_dir = data_dir / 'train'
val_dir = data_dir / 'val'
test_dir = data_dir / 'test'
normal_cases_dir = train_dir / 'NORMAL'
pneumonia_cases_dir = train_dir / 'PNEUMONIA'
normal_cases_t = normal_cases_dir.glob('*.jpeg')
pneumonia_cases_t = pneumonia_cases_dir.glob('*.jpeg')
# Training data as a list
X_train = []
y_train = []
# Normal cases
for img in normal_cases_t:
img = cv2.imread(str(img))
img = cv2.resize(img, (224,224))
# Convert grayscale image
if img.shape[2] ==1:
img = np.dstack([img, img, img])
# CV2 uses BGR format, so we need to convert it to RGB
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# Normalizing the pixel values by dividing by its maximum
img = img.astype(np.float32)/255.
X_train.append(img)
y_train.append(0)
# Pneumonia cases
for img in pneumonia_cases_t:
img = cv2.imread(str(img))
img = cv2.resize(img, (224,224))
if img.shape[2] ==1:
img = np.dstack([img, img, img])
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = img.astype(np.float32)/255.
X_train.append(img)
y_train.append(1)
X_train = np.array(X_train)
y_train = np.array(y_train)
normal_cases_dir = val_dir / 'NORMAL'
pneumonia_cases_dir = val_dir / 'PNEUMONIA'
normal_cases_v = normal_cases_dir.glob('*.jpeg')
pneumonia_cases_v = pneumonia_cases_dir.glob('*.jpeg')
# Training data as a list
X_val = []
y_val = []
# Normal cases
for img in normal_cases_v:
img = cv2.imread(str(img))
img = cv2.resize(img, (224,224))
# Convert grayscale image
if img.shape[2] ==1:
img = np.dstack([img, img, img])
# CV2 uses BGR format, so we need to convert it to RGB
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# Normalizing the pixel values by dividing by its maximum
img = img.astype(np.float32)/255.
X_val.append(img)
y_val.append(0)
# Pneumonia cases
for img in pneumonia_cases_v:
img = cv2.imread(str(img))
img = cv2.resize(img, (224,224))
if img.shape[2] ==1:
img = np.dstack([img, img, img])
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = img.astype(np.float32)/255.
X_val.append(img)
y_val.append(1)
X_val = np.array(X_val)
y_val = np.array(y_val)
normal_cases_dir = test_dir / 'NORMAL'
pneumonia_cases_dir = test_dir / 'PNEUMONIA'
normal_cases_test = normal_cases_dir.glob('*.jpeg')
pneumonia_cases_test = pneumonia_cases_dir.glob('*.jpeg')
# Training data as a list
X_test = []
y_test = []
# Normal cases
for img in normal_cases_test:
img = cv2.imread(str(img))
img = cv2.resize(img, (224,224))
# Convert grayscale image
if img.shape[2] ==1:
img = np.dstack([img, img, img])
# CV2 uses BGR format, so we need to convert it to RGB
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# Normalizing the pixel values by dividing by its maximum
img = img.astype(np.float32)/255.
X_test.append(img)
y_test.append(0)
# Pneumonia cases
for img in pneumonia_cases_test:
img = cv2.imread(str(img))
img = cv2.resize(img, (224,224))
if img.shape[2] ==1:
img = np.dstack([img, img, img])
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = img.astype(np.float32)/255.
X_test.append(img)
y_test.append(1)
X_test = np.array(X_test)
y_test = np.array(y_test)
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import Flatten
from keras.layers.convolutional import Convolution2D
from keras.layers.convolutional import MaxPooling2D
seed = 100
np.random.seed(seed)
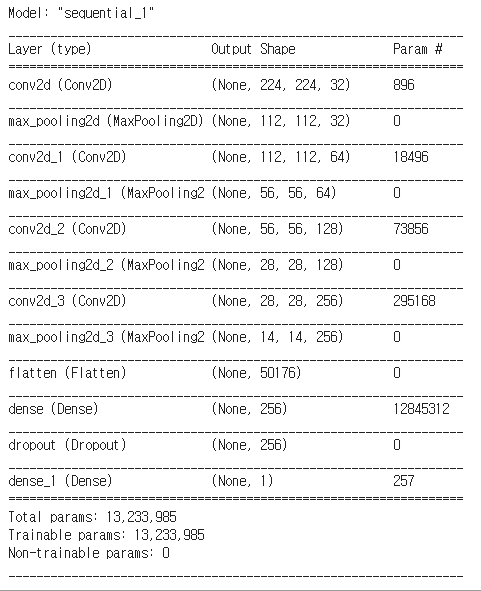
model=Sequential()
a=3
model.add(Convolution2D(32, kernel_size=(a, a), padding='same', strides=(1, 1), input_shape=(image_size, image_size, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Convolution2D(64, kernel_size=(a, a), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Convolution2D(128, kernel_size=(a, a), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Convolution2D(256, kernel_size=(a, a), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(256,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1,activation='sigmoid'))
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
# Final evaluation of the model
scores = model.evaluate(X_test, y_test, verbose=0)
print("loss: %.2f" % scores[0])
print("acc: %.2f" % scores[1])
'''
loss: 2.00
acc: 0.75
'''
관련 자료를 찾던 중 ImageDataGenerator을 알게되었습니다.
CNN은 영상의 2차원 변환인 회전(Rotation), 크기(Scale), 밀림(Shearing), 반사(Reflection), 이동(Translation)와 같은 2차원 변환인 Affine Transform에 취약합니다.
즉, Affine Tranform으로 변환된 영상은 다른 영상으로 인식하므로, Data Generator를 사용하여 이미지에 변화를 주면서 컴퓨터의 학습자료로 이용하여 더욱 효과적이고 과적합을 방지하는 방식인, ImageDataGenerator으로 학습하도록 하였습니다.
ImageDataGenerator 사용
from tensorflow.python.keras.preprocessing.image import ImageDataGenerator
from keras.applications.mobilenet import preprocess_input
image_size = 224
batch_size = 32
seed = 100
datagen = ImageDataGenerator (
rescale = 1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
)
# load the data using data generators
train_generator = datagen.flow_from_directory(
train_dir,
seed=seed,
target_size = (image_size,image_size),
batch_size =batch_size ,
class_mode = 'binary',
)
test_generator = datagen.flow_from_directory(
val_dir,
seed=seed,
target_size = (image_size,image_size),
batch_size = batch_size ,
class_mode = 'binary',
)
validation_generator = datagen.flow_from_directory(
test_dir,
seed=seed,
target_size = (image_size,image_size),
batch_size = batch_size ,
class_mode = 'binary',
)
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import Flatten
from keras.layers.convolutional import Convolution2D
from keras.layers.convolutional import MaxPooling2D
seed = 100
np.random.seed(seed)
model=Sequential()
a=3
model.add(Convolution2D(32, kernel_size=(a, a), padding='same', strides=(1, 1), input_shape=(image_size, image_size, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Convolution2D(64, kernel_size=(a, a), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Convolution2D(128, kernel_size=(a, a), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Convolution2D(256, kernel_size=(a, a), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(256,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1,activation='sigmoid'))
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
# Final evaluation of the model
scores = model.evaluate(test_generator, verbose=0)
print("loss: %.2f" % scores[0])
print("acc: %.2f" % scores[1])
'''
loss: 1.12
acc: 0.69
'''
Epoch을 10으로 하였을 때, ImageDataGenerator를 사용하지 않았을 때, acc = 0.75, 사용하였을때 acc =0.69로 사용하지 않았을 경우가 더 높게 나왔습니다.
좀 더 확실히 비교하기 위해 epoch을 20으로 늘려 테스트해보았습니다.
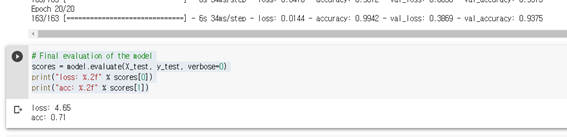
ImageDataGenerator 사용 X
Acc :0.71
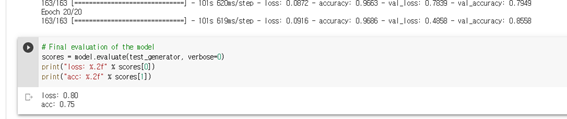
ImageDataGenerator 사용 O
Acc :0.75
여러 차례 수행하였을 때 비슷하게 결과가 나왔습니다.
ImageDataGenerator를 쓰지 않은 경우가 속도가 더 빠르므로 ImageDataGenerator를 쓰지 않고 가장 좋은 결과가 나왔을 때, 그 경우로 ImageDataGenerator를 사용하여 비교해보기로 하였습니다.
Layer 수
먼저 flatten 전까지의 layer의 개수(feature 수(32) 동일,batch_size = 200)를 점차 늘려 보았습니다.
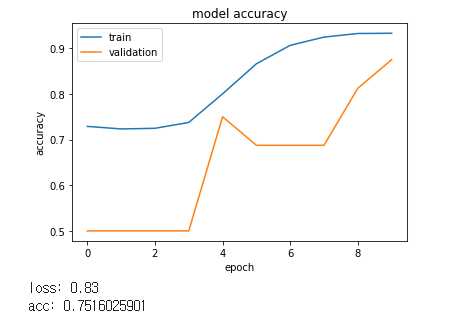
[Layer가 4개 일 때]
[Layer가 5개 일 때 ]
[Layer가 6개 일 때]
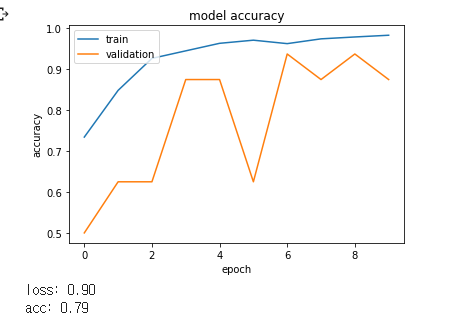
[Layer가 7개일 때]
점점 loss와 acc가 안좋아지므로 layer 수는 5개가 가장 좋은 것으로 확인되었습니다.
그리고 feature의 수를 조절하려 하였습니다. Feature 갯수가 이렇게 많아지게 되면 컴퓨팅 속도가 저하되고 오버피팅의 위험이 생길 수 있으므로 적절한 feature 수가 무엇일지 생각하였습니다.
“http://www.hellot.net/new_hellot/magazine/magazine_read.html?code=202&sub=&idx=42517”의 글을 참조하여 Krizhevsky - ‘ImageNet classification with deep convolution neural network’논문의 내용을 참고하여 feature수를 layer가 깊어질수록 증가시켰습니다.
Feature 수
[논문의 모델과 동일하게 구성]
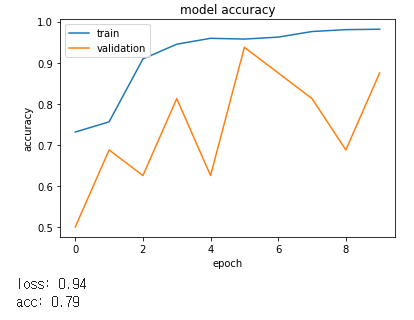
[32->32->64->64->128]
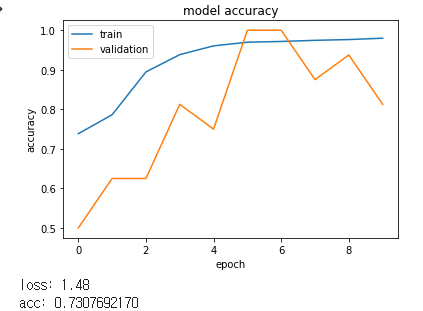
[32->64->128->256->256]
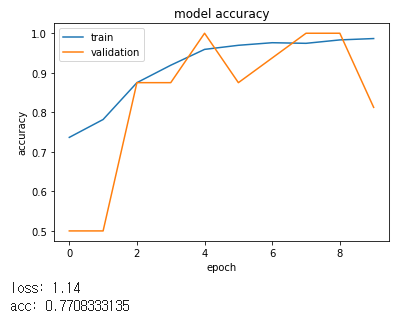
[64->64->128->128->256]
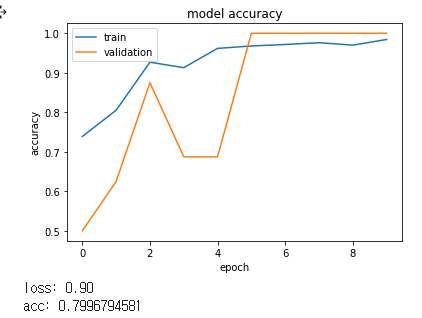
점진적으로 증가되는 것이 좋은 결과를 보여주었습니다.
Batch_size
다음으로는 batch size를 늘려보았습니다.
[32]
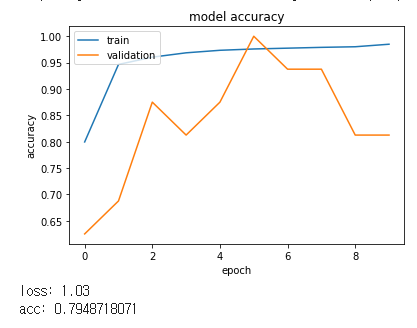
[64]
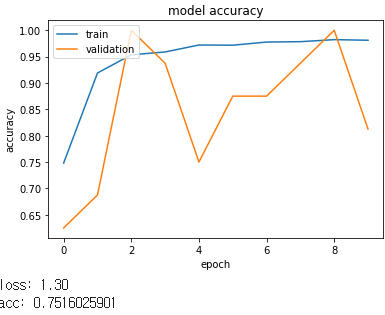
[128]
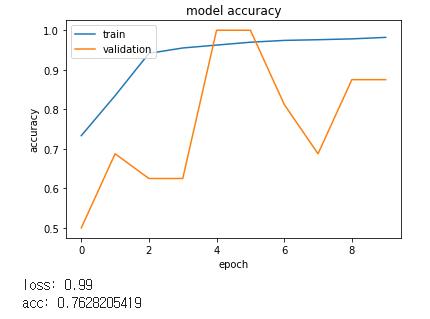
[256]

[512]
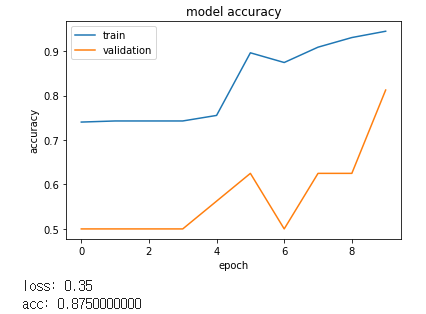
[1024]
Batch size가 커질수록 좋아지는 것을 알 수 있었습니다.
하지만 일정 크기 이상으로 커질 경우
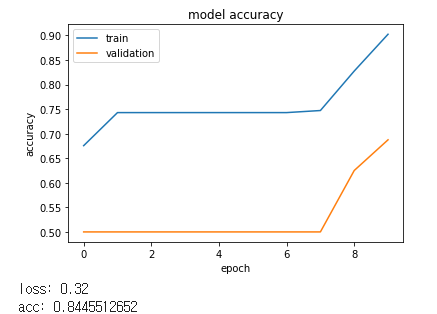
[2048]

좋지 않은 것을 알 수 있었습니다.
또한 “https://blog.naver.com/qbxlvnf11/221449595336” 사이트의 글을 참조하여 batch size를 상대적으로 높이지만 너무 커지면 일반화 성능이 감소하므로, 적절히 값을 다른 데이터들을 바탕으로 종합적으로 모델을 만든 후 값을 바꾸어 가며 테스트를 하기로 하였습니다.
그 다음으로 kernel size를 조절하였습니다.
Kernel size는 작은 것을 여러 개 쓰는 방법이 좋으므로 5부터 1까지 테스트하였습니다
Kernel size
[5]

[4]
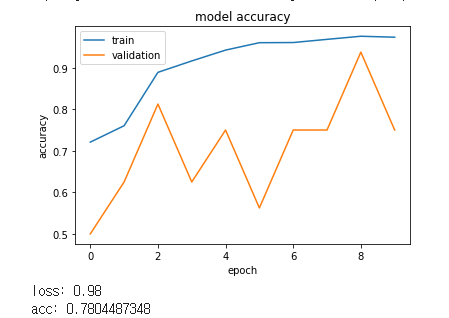
[3]
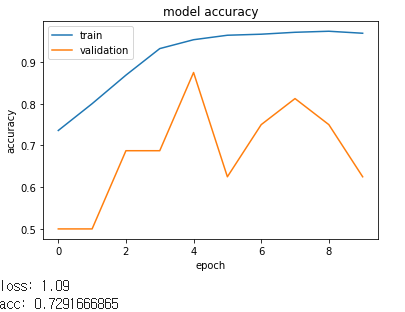
[2]
[1]

Kernel size가 1일 때 가장 좋은 결과를 보여주었습니다.
위 결과들을 바탕으로 layer를 구성하여 테스트하였습니다.
위 요소들을 섞어가며 테스트 중 batch size가 300이 넘어갈 경우 colab에서 ResourceExhaustedError 에러가 나 더 크게 하지 못하였습니다.
또한 세션이 다운되는 문제를 겪었습니다.

다른 요소로 정확도를 향상시키기 위해“https://teddylee777.github.io/tensorflow/keras-%EC%BD%9C%EB%B0%B1%ED%95%A8%EC%88%98-vol-01”를 참고하여 ReduceLROnPlateau를 사용하여 학습률을 동적으로 조정하였습니다.
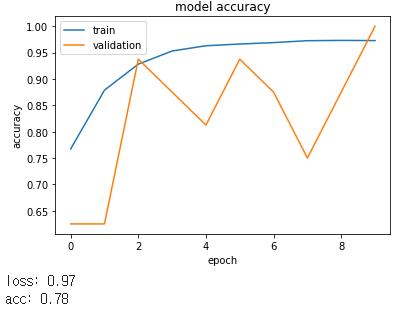
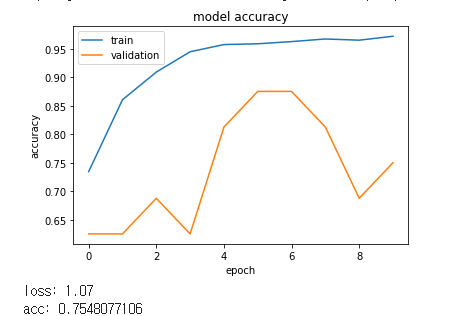
여러 요소들을 조절해가며 테스트하였을 때 밑의 모델이 가장 좋은 예측력을 보여주었습니다.
결과
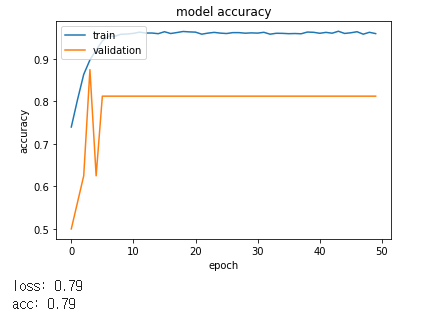
그리고 이 모델을 ImageDataGenerator를 사용하여 테스트하였습니다.
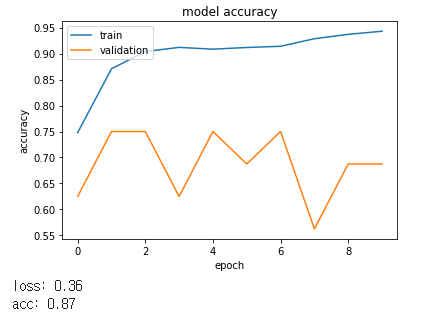
시간은 더 오래 걸리지만 확실히 더 좋은 성능을 보여주었습니다.
그 후 다시 한번 batch size와 feature, image_size, epoch를 조절해보았습니다.
하지만 0.87의 정확도를 넘어서지 않았습니다.
----------------------------------------------------------------------------------------------------
<최종>
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import Flatten
from keras.layers.convolutional import Convolution2D
from keras.layers.convolutional import MaxPooling2D
from keras.utils import np_utils
import numpy as np
import matplotlib.pyplot as plt
import os
import cv2
from tensorflow.python.keras.preprocessing.image import ImageDataGenerator
from tensorflow.python.keras.preprocessing.image import load_img, img_to_array
import numpy as np
from pathlib import Path
import glob
import pandas as pd
from skimage.io import imread # reading image as data
data_dir = Path('chest_xray')
train_dir = data_dir / 'train'
val_dir = data_dir / 'val'
test_dir = data_dir / 'test'
normal_cases_dir = train_dir / 'NORMAL'
pneumonia_cases_dir = train_dir / 'PNEUMONIA'
'''
======================================================================================================================
'''
from tensorflow.python.keras.preprocessing.image import ImageDataGenerator
from keras.applications.mobilenet import preprocess_input
image_size = 224
batch_size = 256
seed = 100
datagen = ImageDataGenerator (
rescale = 1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
)
# load the data using data generators
train_generator = datagen.flow_from_directory(
train_dir,
seed=seed,
target_size = (image_size,image_size),
batch_size =batch_size ,
class_mode = 'binary',
)
validation_generator = datagen.flow_from_directory(
val_dir,
seed=seed,
target_size = (image_size,image_size),
batch_size = batch_size ,
class_mode = 'binary',
)
test_generator = datagen.flow_from_directory(
test_dir,
seed=seed,
target_size = (image_size,image_size),
batch_size = batch_size ,
class_mode = 'binary',
)
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import Flatten
from keras.layers.convolutional import Convolution2D
from keras.layers.convolutional import MaxPooling2D
model=Sequential()
a=3
model.add(Convolution2D(32, kernel_size=(a, a), padding='same', strides=(1, 1), input_shape=(image_size, image_size, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Convolution2D(64, kernel_size=(a, a), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Convolution2D(128, kernel_size=(a, a), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Convolution2D(256, kernel_size=(a, a), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(256,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1,activation='sigmoid'))
from keras.callbacks import ReduceLROnPlateau
learning_rate_reduction = ReduceLROnPlateau(monitor='val_loss', factor=0.3, patience=2, verbose=2, mode='auto')
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
history = model.fit_generator(train_generator, epochs = 10, validation_data = validation_generator, callbacks = [learning_rate_reduction])
# summarize history for accuracy
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.show()
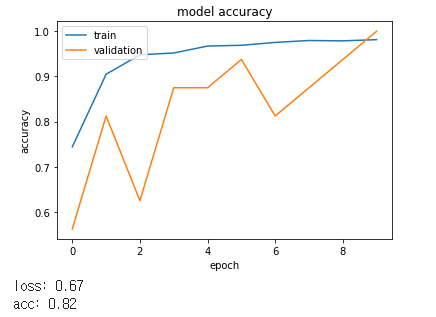
# Final evaluation of the model
scores = model.evaluate(test_generator, verbose=0)
print("loss: %.2f" % scores[0])
print("acc: %.2f" % scores[1])
<그래프>

<model>
<epoch>

'공부 > 딥러닝' 카테고리의 다른 글
| CIFAR-10 의 레이블중 하나를 예측 (0) | 2021.05.09 |
|---|---|
| classification 경진대회 (0) | 2021.05.03 |
| 딥러닝 4 (0) | 2020.10.29 |
| 딥러닝 3 (0) | 2020.10.09 |
| 딥러닝 2 (0) | 2020.09.29 |

아상관없어