


반응형
Clustering
- Grouping target data into some category(class)
- 성격이나 가진 정보가 비슷한 데이터들을 묶음
- 비지도 학습임(정답이 없고 알아서 묶음)
- 어떻게 컴퓨터가 그룹을 나누느냐? => 거리가 가까운것 끼리 묵음 따라서 거리 계산이 중요함.

Classification
- 데이터들이 그룹이 나누어져있고 알고 있음
- 새로운 데이터가 들어왔을때, 어디에 속할지 판단함
- 예측, 의료에서 진단 분야에서 사용됨.
- 주로 많이 사용함.
- 범주데이터를 주므로 지도학습임.
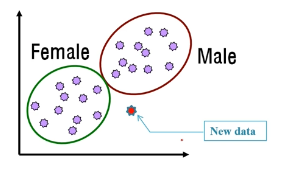
예시 : clustering
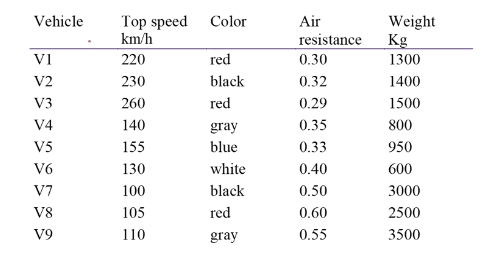
- 차량의 특성을 가지고 grouping
- 산점도를 그림
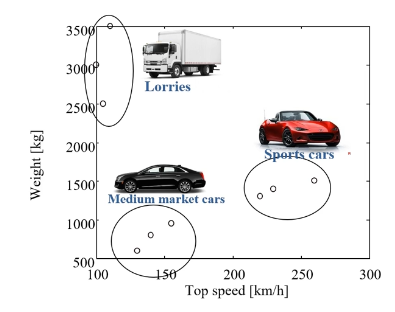
- 점이 모이는 것을 확인할 수 있음
- 그룹이 지어지면 해석이 가능해짐, 그룹의 특징을 해석해서 활용함
- 혹은 비정상 거래 판단시, 주류범주에 속하지 않으면 비정상 거래로 탐지
예시 : classification
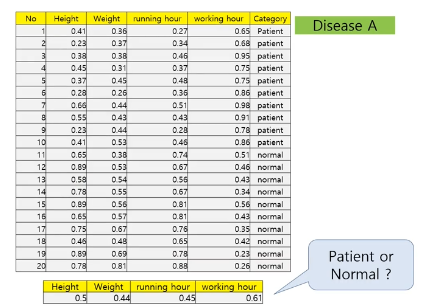
- 이미 그룹이 만들어져 있음
- ex) 병원 새로운 사람이 왔을때 환자인지 정상인지 판단
- 어떤 class에 속하는지 찾아봄
Binary vs multiple classfication
- Binary classification
- class 의 수가 2개인 경우
- 좀 더 쉬움 = 모델의 정확도가 높음
- multifple classfication
- class의 수가 3개 이상인 경우
K-means clustering
- 예시 : 금이간 타일과 정상 타일 군집화
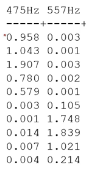
- 크랙이 있는 것과 없는 것은 소리(주파수)가 다름
- clustering을 하였을때, 금이 간 것과 안 간것끼리 class가 나뉘어야 사용할 수 있음
- 주의) log값을 취하여 사용함. 왜냐하면 scale을 맞추어 왜곡값을 줄이기 위하여임(그러지 않을 경우 값들이 x, y축에 붙음)
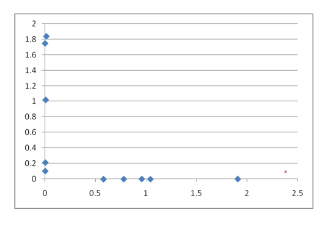
- 두개의 그룹으로 확연하게 분리됨

- k = 클러스터의 수 => 따라서 2개(금간것, 안간것)
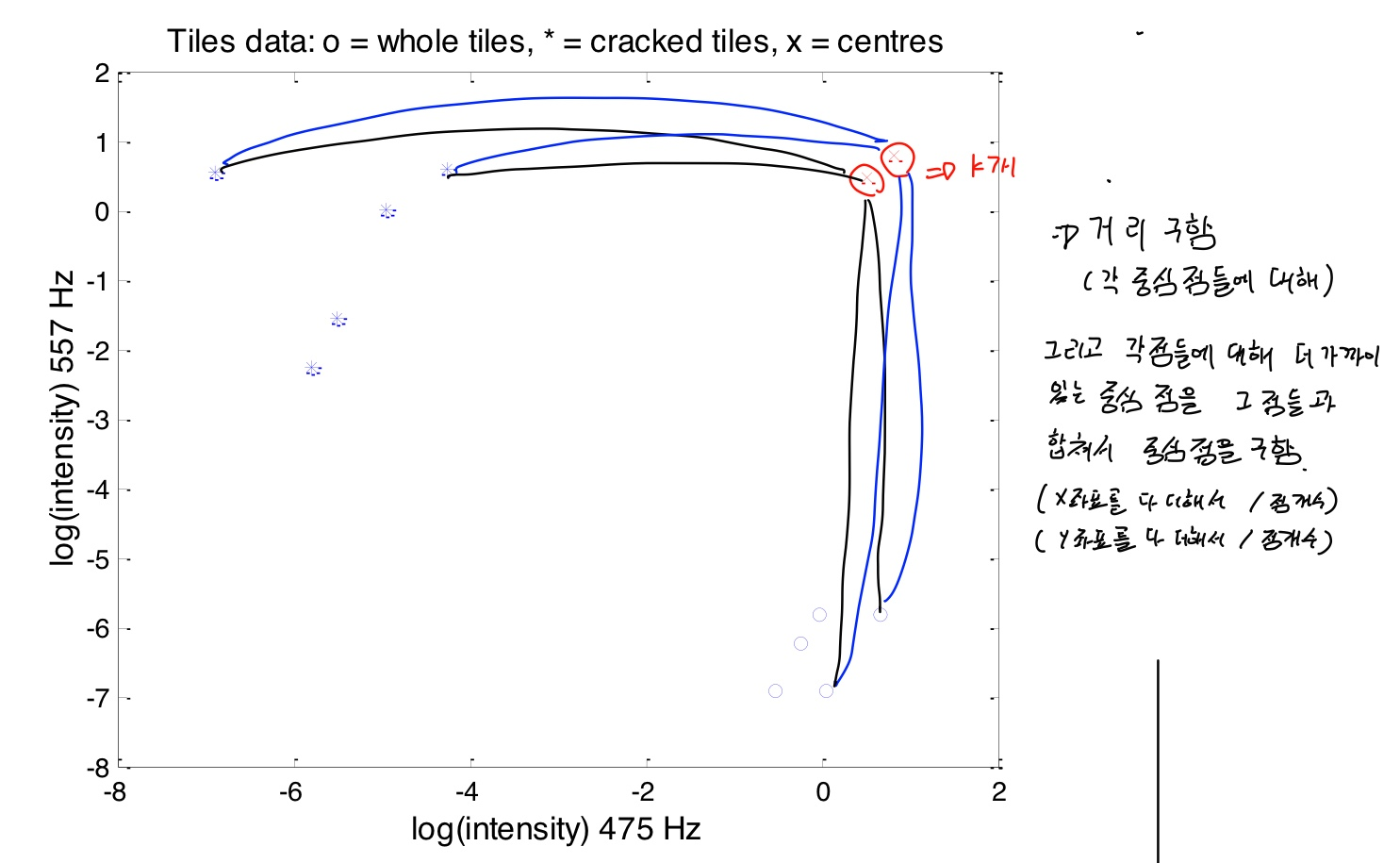
- 임의로 점 두개를 찍음( k 개수 만큼)
- 이 점이 각 클러스터의 중심점이 됨
- 중심점과 점들의 거리를 구함
- 각 점들에 대해 더 가까이 있는 중심점을 그 점들과 합쳐서 중심점을 구함(x 좌표 평균, y 좌표 평균이 새로운 중심점)
- 반복하여 계산함
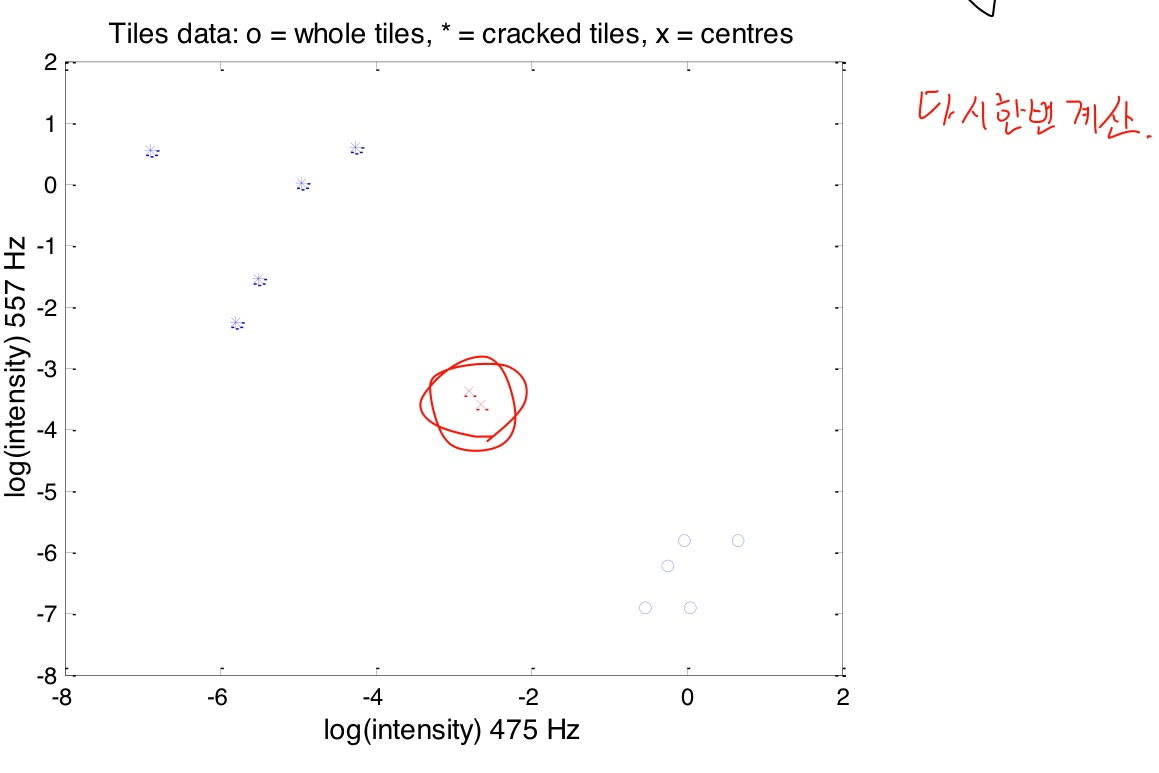
- 더 이상 안움직이는 때(움직임이 작을 때)가 오면 그룹의 중심을 찾았다는 뜻이다. 그러면 중심점들과 점 사이 거리를 계산하여 그룹을 찾는다.
- 두 그룹이 금간 것, 안간 것으로 구분이 되면, 이것으로 새로운 것이 들어왔을때 판단을 한다(중심점으로)

- 거리계산법

import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
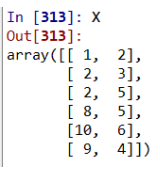
X = np.array([[1,2], [4,3], [2,5],
[8,5], [10,6], [9,4]])
kmeans = KMeans(n_clusters=2, random_state=0).fit(X)- n_clusters : 클러스터의 개수
- random_state : seed for reproducability => 클러스터 중심점 위치를 랜덤하게 찍기위해
# cluster label
kmeans.labels_ #클러스터 번호 알려줌
# bind data & cluster label
np.hstack((X, kmeans.labels_.reshape(-1, 1))) #lable을 포함하여 X를 보여줌, 세로로 바꾸어 합침
# center of clusters
kmeans.cluster_centers_ #중심점의 좌표값을 보여줌
# predict new data
kmeans.predict([[0, 0], [12, 3]]) #예측
KNN classifier
- 분류(classification)
- 어느 카테고리에 속할것인가?
- idea of KNN
- 모르는 데이터와 알려진 데이터 중 모르는 데이터에 가까운 것들을 추림
- K-NN : K는 몇개를 추릴 것인지
- 그러면 K개 중 많은 것을 따름(다수를 따라감)
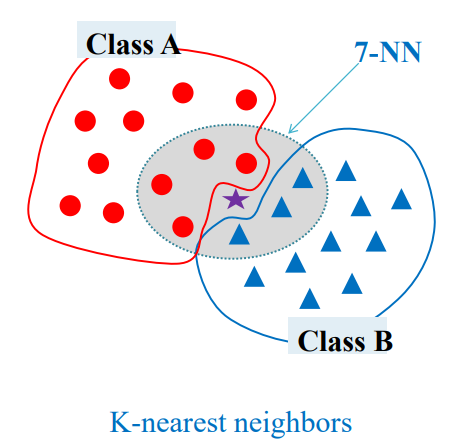
- 가까운 이웃을 판단하기 위해선 거리를 다 계산함(모르는 데이터와 알려진 데이터들 사이의 거리)
- K는 홀수로 하여야 모르는 데이터가 어디에 속할 지 정하기 쉬움

- 계산
- K의 값은 데이터의 수가 N이라 할 때, K < sqrt(N)을 권장
- K가 클때와 작을때 각각 장단점이 있음

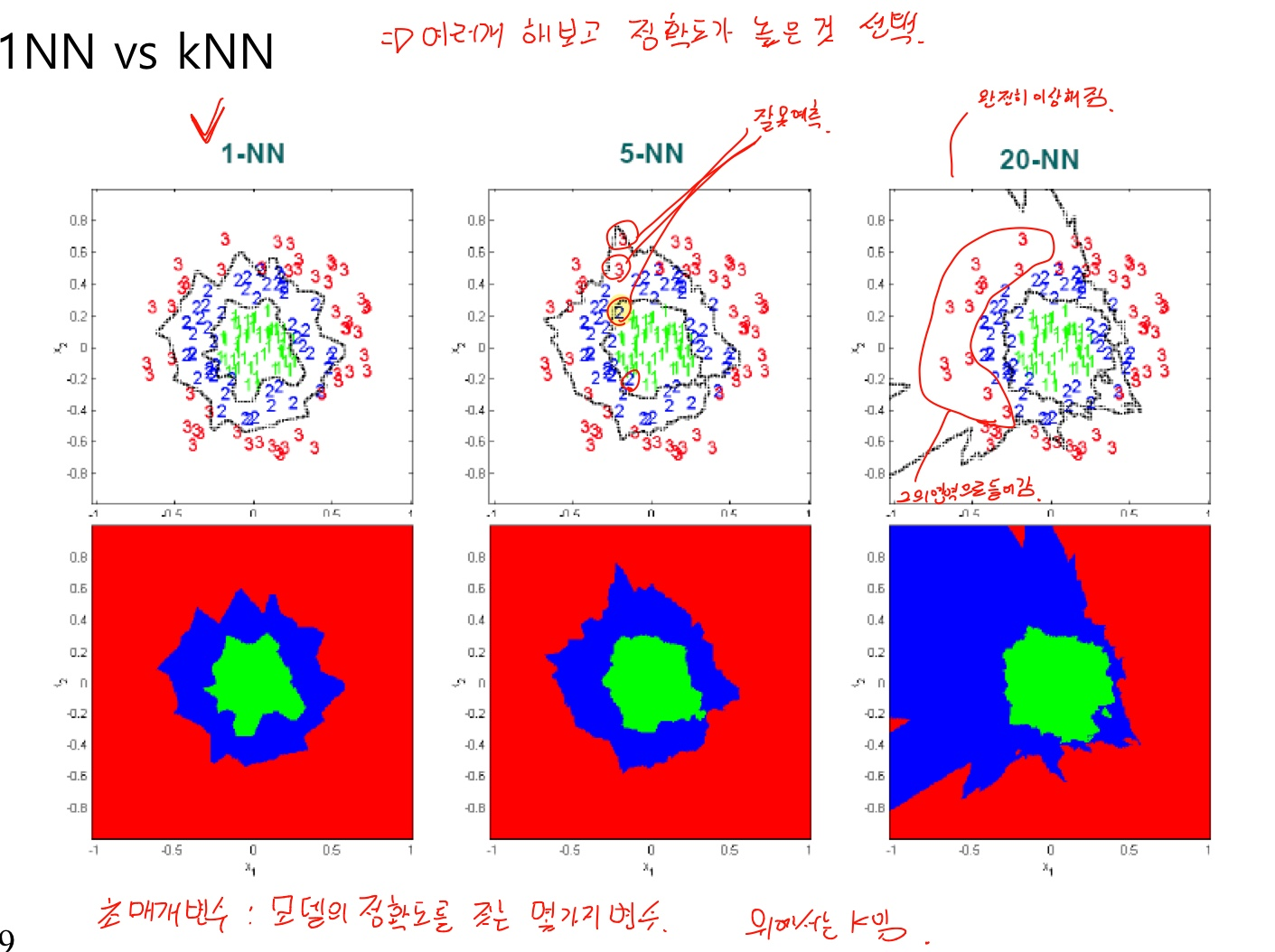
- K개수에 따라 정확도가 달라지므로 여러개를 해보고 그중 정확도가 높은 것을 선택해야한다.
- 이러한 모델의 정확도에 영향을 미치는 변수를 초매개변수라 한다. 정확도가 높은 초매개변수를 찾는 것이 중요함
- 장점
- 통계적 가정 불필요(머신러닝 초기 모델들은 통계에 기반하여, 데이터는 정규분포를 따른다는 가정을 했다. 따라서 가정을 벗어난 데이터는 예측이 불가능했다)
- 단순하다
- 성능이 좋다
- 모델을 훈련하는 시간이 필요없다 (모델을 만드는 과정이 없음, 데이터를 바로 찾아서 결과를 냄 )
- 단점
- 데이터가 커질수록 많은 메모리가 필요하다
- 데이터가 커질수록 처리시간(분류시간)이 증가한다.
- 모르는 값이 있을 때, class를 구하려면 거리계산을 다 해주어야한다. 따라서 메인메모리에 모든 값이 있어야한다. 그리고 모두 거리계산을 해주어야한다.
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Load the iris dataset
iris_X, iris_y = datasets.load_iris(return_X_y=True)
print(iris_X.shape) # (150, 4)
# Split the data into training/testing sets
train_X, test_X, train_y, test_y = \
train_test_split(iris_X, iris_y, test_size=0.3,\
random_state=1234) # Define learning model
model = KNeighborsClassifier(n_neighbors=3) #K값은 3임, 초매개변수 K = 3 (default값은 5임)
# Train the model using the training sets
model.fit(train_X, train_y)
# Make predictions using the testing set
pred_y = model.predict(test_X)
print(pred_y)
# model evaluation: accuracy #############
acc = accuracy_score(test_y, pred_y)
print('Accuracy : {0:3f}'.format(acc))- Dataset scaling
- 거리기반 학습방법을 적용할 때는 scaling이 필요
- 예로 키, 시력을 비교시 (170, 0.8) 두 값간의 차이가 커서 시력의 거리 의미가 없어짐
- 따라서 두 크기의 스케일을 바꾸어 동등한 영향력을 가지게해야함.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler() # 정의
scaler.fit(X) # X : input data # 실행
X_scaled = scaler.transform(X) # 결과 얻음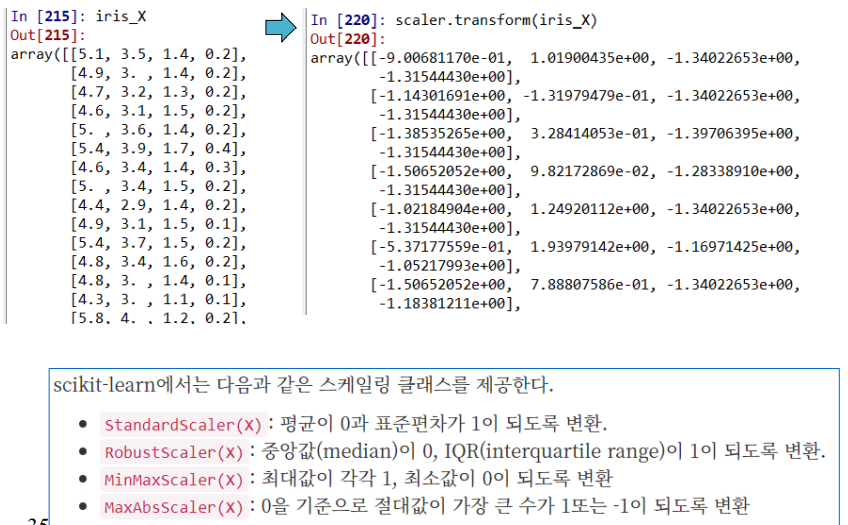
Performance metric : 모델 성능 평가 척도
For Binary classification model only
- Sensitivity
- Specificity
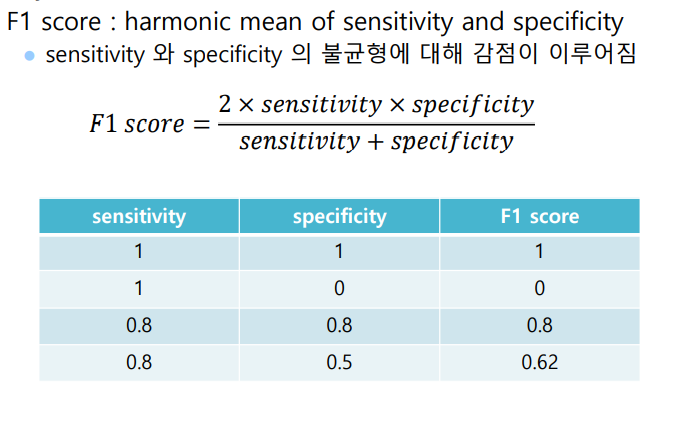
- precision
- F1 score
- ROC, AUC
For All classification model
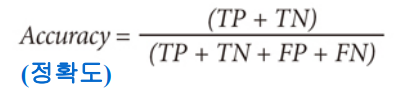
- Accuracy
=> 평가 척도가 다양한 이유는 응용을 어디에 하느냐에 따라 모델 평가 척도가 달라지기때문
- Binary classification metric

의료일 경우 FP인 경우, 음성을 양성으로 잘못 판단한 것이므로 정상을 비정상으로 진단한 경우다.
FN인 경우 양성을 음성으로 잘못 판단한 것이다. 실제로 감염이 된 것인데 안되었다고 판단하므로 FN의 경우가 더 심각하다
- 민감도
- Sensitivity = TP/(TP+FN) => (실제 양성인데) 양성 판단 / 실제 양성
- 특이도
- Specifity = TN/(TN+FP) => (실제 음성인데) 음성 판단 / 실제 음성
- 정밀도
- Precision = TP/(TP+FP) => (실제 양성인데) 양성 판단 / 양성 판단
- F1 ScoreBinary가 아닌 경우
- class A, B, C가 있을경우
- For class A : A는 Postive, B,C는 Negative
- For class B : B는 Postive, A,C는 Negative
- For class C : C는 Postive, A,B는 Negatvie
=> table을 만드는 경우 복잡하고 의미를 찾기 힘들다.
from sklearn.metrics import accuracy_score
test_y = [2, 0, 2, 2, 0, 1]
pred_y = [0, 0, 2, 2, 0, 2]
acc = accuracy_score(test_y, pred_y)
print(acc)aac = 0.6666666666666
- Confusion matrix
from sklearn.metrics import confusion_matrix test_y = [2, 0, 2, 2, 0, 1] pred_y = [0, 0, 2, 2, 0, 2] confusion_matrix(test_y, pred_y)

- 정답이 0이고 예측도 0인 경우가 2개 있고, 1,1인 경우가 0개 2,2개인 경우가 2개이다 나머지는 예측이 틀린 경우이다
# binary classification
test_y = [1, 0, 0, 1, 0, 1]
pred_y = [0, 0, 0, 1, 0, 1]
tn, fp, fn, tp = confusion_matrix(test_y, pred_y).ravel()
(tn, fp, fn, tp)tn, fp, fn, tp
3, 0, 1, 2
=> tn, fp, fn, tp 순이다.
K-fold Cross Validation
---------------------------------------------------------------------------------------------------
- 데이터를 Training과 Test로 나누었을때 나온 accuracy를 믿어야하는가?
- Test 데이터 셋을 다르게 만든다면 accuracy는 달라질 것임
- Test 데이터 셋이 어떻게 구성되었느냐에 따라 accuracy가 원래 성능보다 높거나 낮게 나올 수도 있음
- K-fold Cross Validation을 사용함

- k가 4인 경우 4등분하여 각 모델별로 Test와 Train을 다르게 한다.
- 그리고 각 모델의 정확도의 평균을 구한다
복잡한 방법 : 하지만 for문 사이에 테스트 코드를 추가할 수 있다.
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import KFold
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import numpy as np
# Load the iris dataset
iris\_X, iris\_y = datasets.load\_iris(return\_X\_y=True)
# Define fold (5 fold)
kf = KFold(n\_splits=5, random\_state=123, shuffle=True) # shuffle => 섞음(섞어서 나눔)
# Define learning model
model = KNeighborsClassifier(n\_neighbors=3)
acc = np.zeros(5) # 5 fold 저장할 배열
i = 0 # fold no
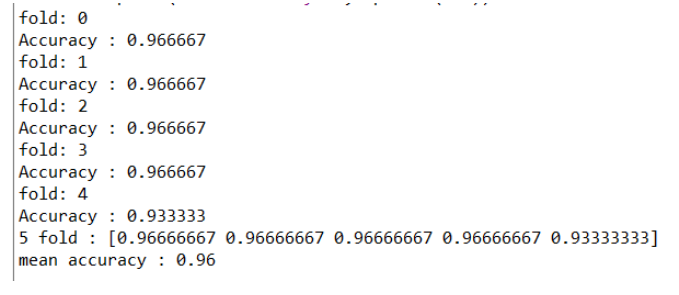
for train\_index, test\_index in kf.split(iris\_X):
print("fold:", i)
train\_X, test\_X = iris\_X\[train\_index\], iris\_X\[test\_index\]
train\_y, test\_y = iris\_y\[train\_index\], iris\_y\[test\_index\]
model.fit(train\_X, train\_y)
pred\_y = model.predict(test\_X)
# model evaluation: accuracy
acc\[i\] = accuracy\_score(test\_y, pred\_y)
print('Accuracy : {0:3f}'.format(acc\[i\]))
i += 1
print("5 fold :", acc)
print("mean accuracy :", np.mean(acc))
심플한 방법
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import numpy as np
# Load the iris dataset
iris\_X, iris\_y = datasets.load\_iris(return\_X\_y=True)
# Define learning model
model = KNeighborsClassifier(n\_neighbors=3)
# Define fold (model, train, target, cross validation)
scores = cross\_val\_score(model, iris\_X, iris\_y, cv=5) # cv=5는 fold가 5개임
print("fold acc", scores)
print("mean acc", np.mean(scores))

- K-fold cross validation이 원하는 모델을 도출하진 않음 (k=5일 경우 모델은 5개가됨)
- 주어진 데이터 셋으로 모델 개발시 미래의 정확도를 추정 ( k=1, 3, 5 일경우 최적의 경우를 찾음)
- 최종 모델 개발을 위한 hyper parameter 튜닝에 사용
- 전처리시 feature selection에 사용 => 모델을 만드는데 도움이되는 변수를 골라냄
728x90
반응형
'공부 > 딥러닝' 카테고리의 다른 글
| CIFAR-10 의 레이블중 하나를 예측 (0) | 2021.05.09 |
|---|---|
| classification 경진대회 (0) | 2021.05.03 |
| 딥러닝 4 (0) | 2020.10.29 |
| 딥러닝 3 (0) | 2020.10.09 |
| 딥러닝 1 (0) | 2020.09.25 |

아상관없어