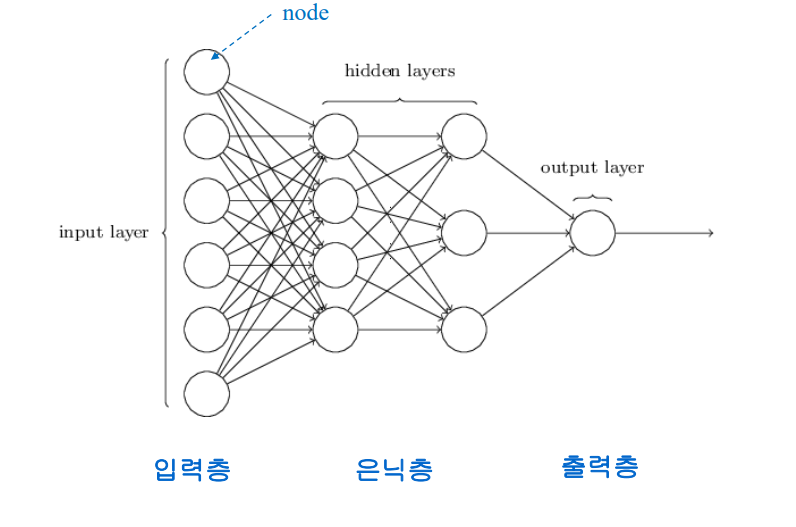
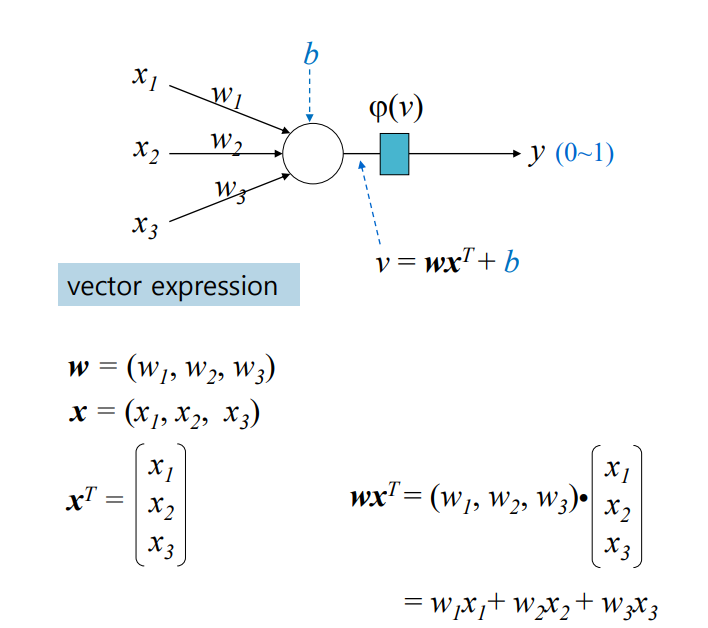
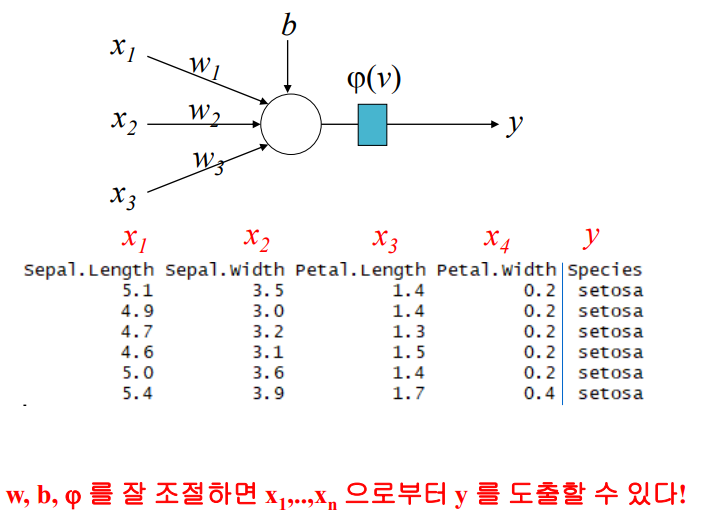
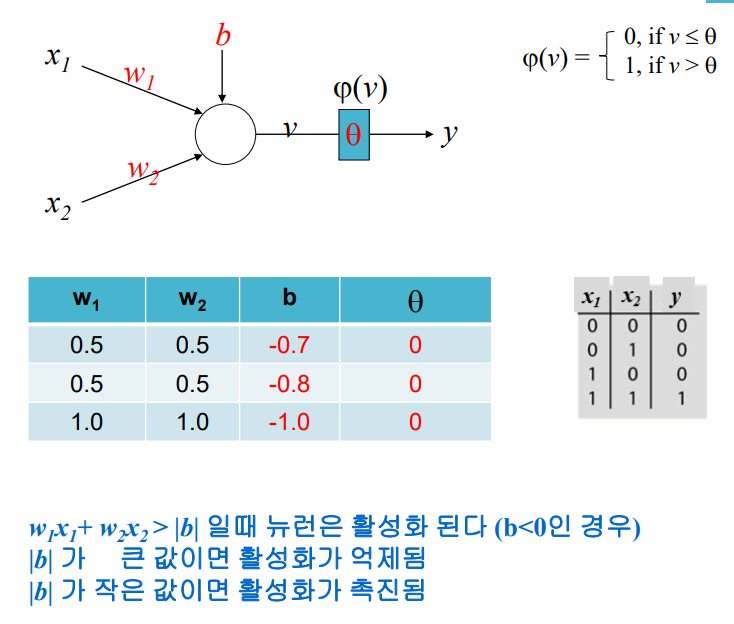
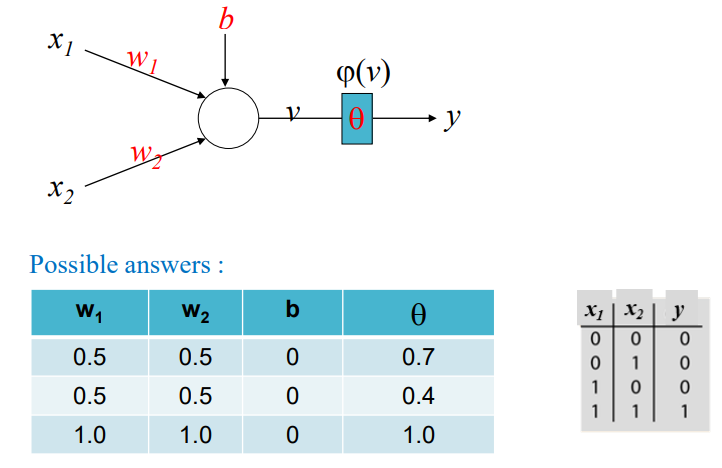
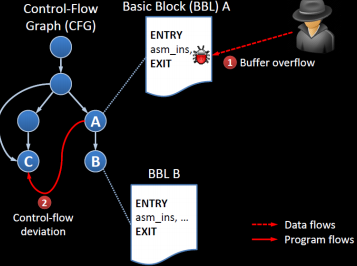
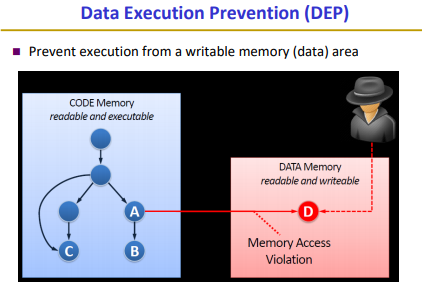
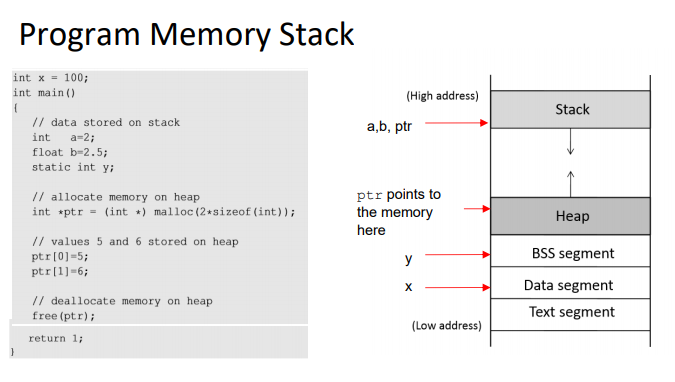
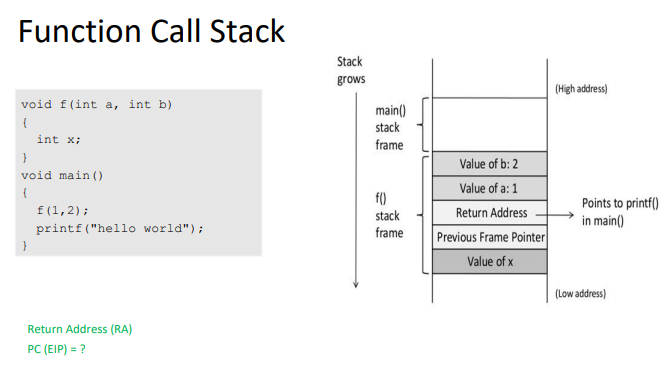
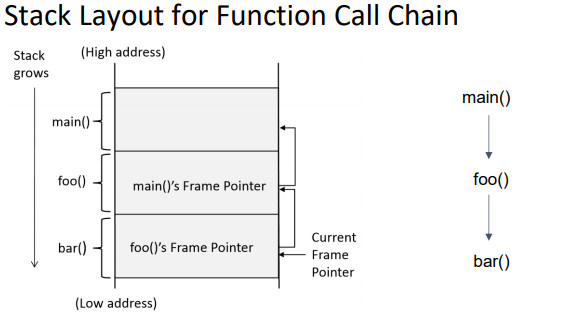
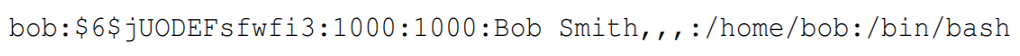control flow 프로그램이 여러개의 문장 또는 명령어로 되어있는데, 프로그램에 있는 문장, 명령어, 함수 호출들이 실행되는 순서를 의미한다.
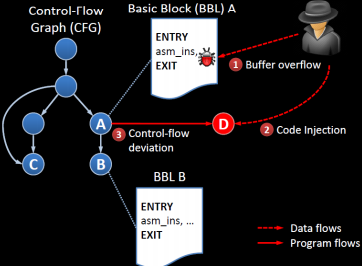
Control Hijacking Attacks 프로그램의 에러를 활용한다. 메모리조작 취약점을 사용한다.(메모리를 깨뜨리는 취약점) runtime때 의도된 제어프름을 덮어쓴다.
control Hijacking Attacks = Control-flow hijacking attacks control flow을 바꾼다. code pointer의 위치가 바뀌어진다. => PC(program counter)에 영향을 주는 값이 code pointer이다. 따라서 다음에 실행될 명령어가 달라진다. 접근하지 못하는 메모리 영역을 바꾼다. => 변조되지 않아야할 영역까지도 달라질 수 있다.
주로
code injection attack
code reuser attack 이 있다.
Control Flow Graphs
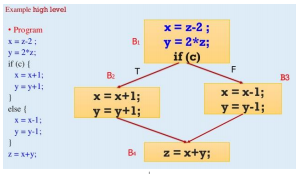
프로그램들은 basic block들로 구성되어 있다. CFG는 basic block들이 어떤 순서대로 흘러가는지 보여준다.
basic block 프로그램의 일부로, 실행되는 코드영역이다. 차례차례 실행되는 프로그램 영역이다.
하나의 진입점이 있으면 진출점도 하나밖에 없다.
basic block 안에서는 모든 명령들이 순차적으로 실행된다.
control flow graph 방향이 있으며 노드는 basic block을 가리키고 엣지는 control flow path를 가리킨다.
Code Injection Attack & Code Reuse Attack
Code injection attack 일반적인 방식
공격자는 새로운 basic block을 추가하고 취약한 노드의 제어흐름을 조작한다.
Code reuse attack 일반적인 방식
공격자가 새로 추가하는 노드는 없다. 노드의 취약점으로 본래의 다른 노드로 가게 흐름을 바꾼다.
Code Injection Attack
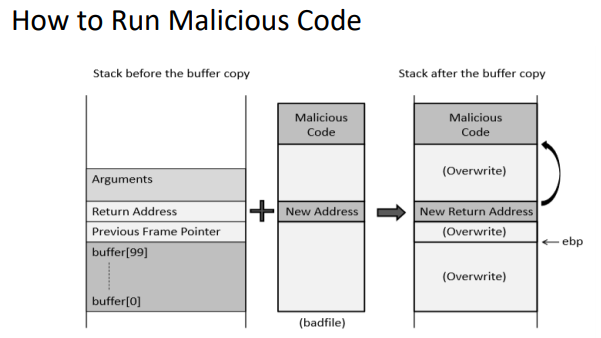
control hijacking 중 하나이며 흐름이 주입된 코드로 덮여쓰여진다.
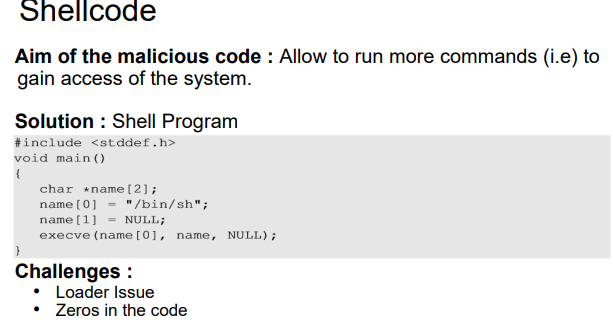
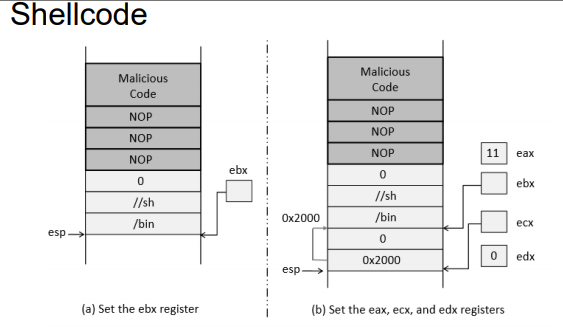
일반적으로 shell code를 주입한다.
shell code는 주로 버퍼에 저장되며 제어 흐름을 shell로 이동시켜주는 역할을 한다.(새로운 shell이 만들어짐)
shell code는 기계어로써, 프로세서와 운영체제에 따라 다르게 작성되어야한다.
Code Reuse Attack
원래 프로그램 코드를 의도하지 않은 방향으로 조작한다.
일반적으로 실행가능한 코드는 code segment와 library에 존재한다.
예시로 Ret2Libc, Rop, Jop가 있다.
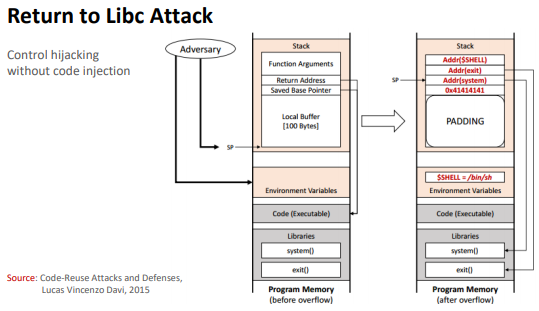
Return-to-libc Attacks
Non executable Stack 우회 가능
const char code는 전역변수이다. 전역변수는 Data segment에 위치한다.
((void(*)()))buffer)()로 함수포인터로 cast한다.
지역변수 buffer의 주소로 함수를 호출한다.
buffer가 지역변수이기 때문에 실행되진 않는다.(non executable stack)
하지만 code를 직접실행하면 된다.
** 함수포인터?
어떻게 non executable stack을 우회할 것인가?
libc => c는 common으로 모든 프로그램에 연결되는 공통 라이브러리를 뜻한다.
libc 안의 "system" 함수의 취약점을 사용한다.
system함수는 인자로 들어오는 명령어들을 실행해준다.
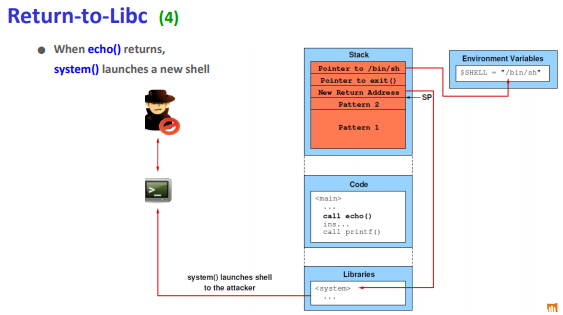
return address를 system함수가 있는 위치로 가게하고 인자로 원하는 명령어를 준다면 공격이 성공할 것이다.
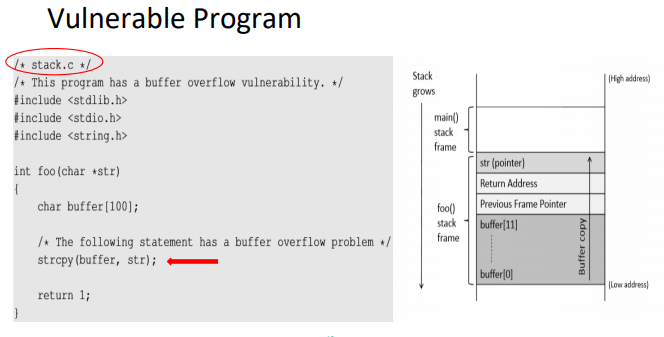
그림의 경우 버퍼의 크기는 100바이트 이다.
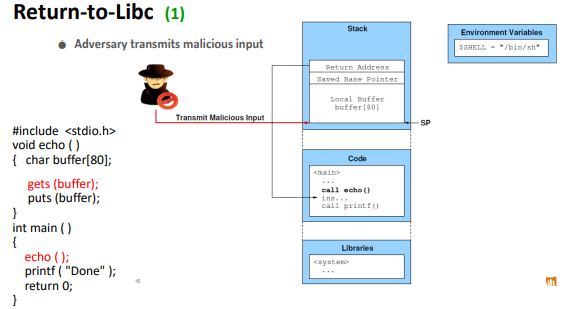
정상적이라면 왼쪽 그림과 같은 상황인데, 여기서 버퍼를 넘치게하여 리턴 주소와 함수 인자를 조작하여야한다.
일반적으로 함수가 호출될때 리턴 주소위에 인자가 있다.
따라서 이점을 이용한다면 system함수를 호출하고 인자로 원하는 명령어를 넣을 수 있다.
1. return address에 system의 주소를 가리키게한다.
2. saved ebp는 아무값이나 주어도된다.
3. system함수의 인자로 /bin/sh의 주소를 준다. => /bin/sh이 있는 환경변수의 위치가 주소일것이다.
4. crash가 나지 않게하기위해 exit를 넣어준다. => 왜냐하면 인자 밑이 리턴주소인데, system 함수 인자인 /bin/sh의 주소 밑이 return address가 되므로 exit가 return address가 된다.
일종의 system 이라는 것이 call 되는 것이고, 시스템 함수가 call 되면 arg가 쌓이고 return address가 쌓인다.
따라서 exit가 return address가 된다.
-------------------
| arg = bin/sh |
-------------------
| ret = exit |
-------------------
| addr(system) |
-------------------
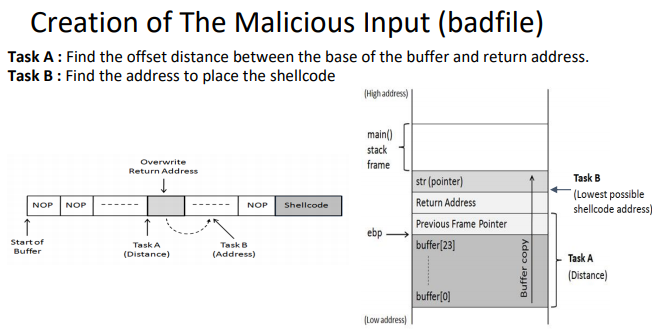
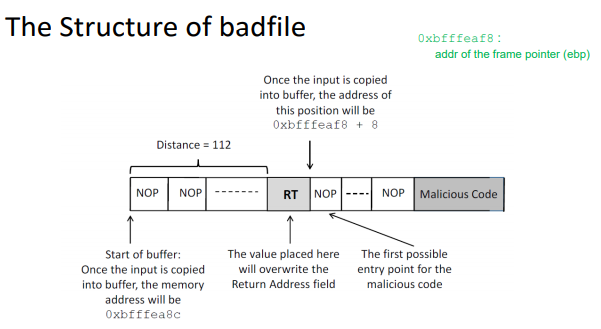
따라서 여기서 버퍼의 크기는 80바이트이다. 공격을 위해선 saved ebp, ret(addr(system)), exit, addr(shellcode) 4가지가 필요하므로
32bit 컴퓨터라 가정시 버퍼에 총 96바이트가 들어가야한다.
따라서 원래 버퍼에 80바이트 만큼 A를 넣어준다. 그리고 saved ebp에 4바이트의 B를 넣고, system이 있는 곳 0x40058ae0을, 위의 예시에선 exit를 넣어주지 않고 아무값이나 넣었다. addr(shellcode) = system함수의 인자에는 /bin/sh이 있는 곳 환경변수의 주소를 넣었다.
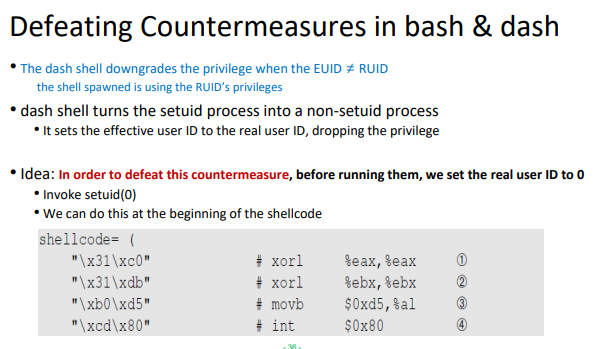
하지만 일반 유저들이 그들의 비밀번호를 바꿀때 어떻게 바꿀 수 있을까? 특권 프로그램을 이용해서 바꾼다
일반적으로 운영체제 내에서 세부적으로 접근 제어를 하는 것은 굉장히 복잡하다. rwx 3가지 권한을 세부적으로 할 경우 write를 1. 앞에 2. 중간에 3. 뒤에 와 같이 3가지로 나눌 수 있다. 하지만 복잡해진다.
따라서 rwx + 3bits 총 12비트로 permission을 나타낸다. (확장, fine-grained access control을 위해 3bits를 추가한다.)
일반적으로 OS가 제공하는 접근제어를 바로 사용가능하지만 (e.g system call) 특별한 경우(e.g root가 가진 파일 수정)는 특권 프로그램이 필요하다! => setUID가 설정된 프로그램이 필요하다! 혹은 daemons (관리자(super user)를 믿는다고 가정한다. 일반 사용자들은 특권 프로그램을 이용해서 바꿀 수 있다)
Different Type of Privileged Programs
Daemons in Linux (MS Windows 에서는 services) 백그라운드에서 계속 수행된다. 따라서 키보드로 부터 입력을 받을 수 없다. root나 특권을 가진 유저의 권한으로 실행해야한다.
만약 daemon에게 요청을 하고 요청이 타당하면 daemon이 수행한다. (특히 Network는 Service를 위해 daemon들을 많이 사용한다. ps - af, ef, af 등을 통하여 모든 프로세스들을 보면 d로 끝나는 것들이 있다. Network daemon을 뜻한다. => 중요한 일을 하므로 root의 권한을 주던지 어떤 특권이 있는 사용자의 권한으로 돌아간다. 중요한 일을 하므로 daemon을 임의로 만들지 못한다.
Set-UID Programs Unix 시스템에서 사용된다. 특정한 비트가 표시되어있는 프로그램이다.
Set-UID Concept
superman story
Power suit 1.0 Super man은 자신의 모든 권한을 superpeople 준다. 문제점 : superpeople중 나쁜 사람이 있을 수 있다.
Power Suit 2.0 주어진 일만 가능하게 한다. 특정한 일을 위한 컴퓨터 칩을 같이 내장한다. => chip에서 시킨 일만 함 미리 프로그래밍이 되어 있어 프로그래밍된 일만 한다.
일반 프로그램이 실행되었을때 RUID와 EUID는 같지만, setUID 가 실행되었을때는 다르다.
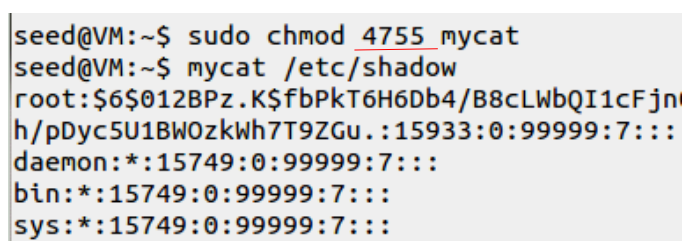
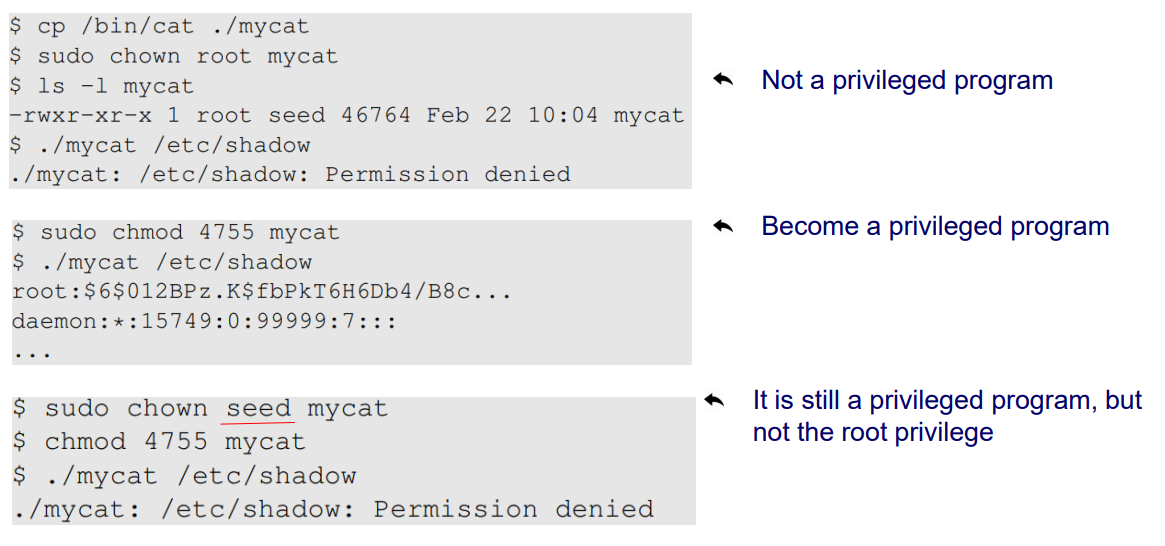
mycat의 owner를 root로 변경하였다.
mycat으로 /etc/shadow를 보려하면 권한이 없는 것을 볼 수 있다.
chmod로 "4"775로 setUID를 설정하였다. (setUID bit 설정)
그러자 /etc/shadow를 볼 수 있다.
setUID bit를 설정하였을 때, euid가 root가 됨을 알 수 있다.
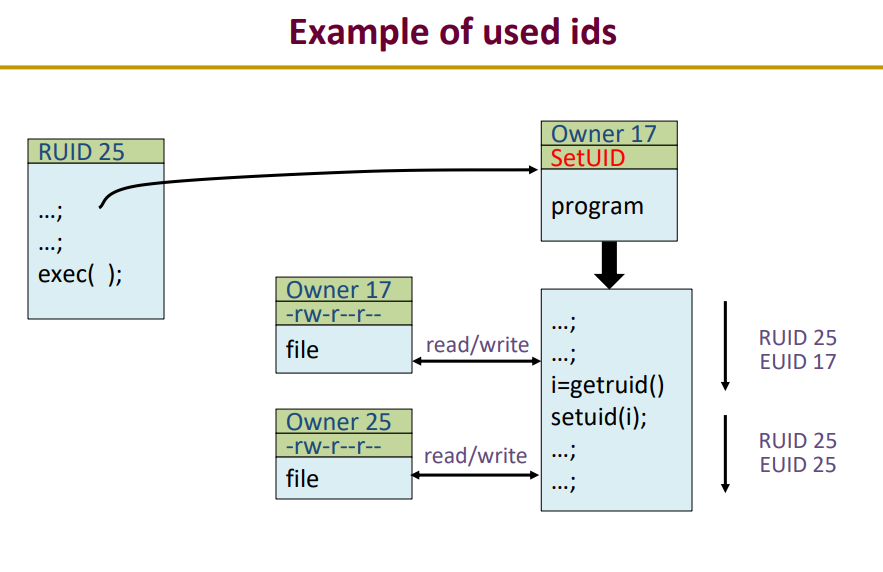
exec전에는 RUID=EUID=25
exec을 하면서 owner가 17이고 setUID가 설정된 program을 실행함.
그러면 EUID가 17로 변경이 됨
i=getruid => ruid를 가져와서
setuidI(i) => euid를 이전의 상태로 돌림
Unix setuid그림을 보면
setuid bit가 0, 1일때 각각 euid를 보면 201, 100인 것을 볼 수있다.
pid1 = 모든 사용자 프로세스의 조상 (처음에 만들어지고 1번으로 계속 남아있음)
pid 523 ruid 0 euid 0 => pid 523 ruid 42 euid 42
setgroups, setgid, setuid를 실행하면 변경됨을 알 수 있다.
다시한번 예시를 보면
setUID bit를 설정해주면 일시적 권한 상승으로 소유자 권한으로 실행되는 것을 볼 수 있다.
setUID 보안?
일반 유저들에게 권한을 상승시켜준다.
슈퍼맨의 컴퓨터 칩처럼 행동이 제한되어있다.
setUID 내 포함된 행위만 가능하다
sudo command와 달리 직접 권한을 주는것은 아니다. (sudo => 1. root의 pw 아는 경우
2. 다른 user(권한이 있는) pw 아는 경우
3. /etc/shadow file에 사용자가 등록되어 있는 경우
)
만약 superman이 "북쪽으로 가서 왼쪽으로 틀고 성벽을 부셔라"라는 명령을 할때, 만약 명령을 받는 Mallory가 지구 반대편에 있고, 성벽의 반대쪽에 은행이 있다고 할 경우, Mallory의 기준에서 북쪽으로 가서 왼쪽으로 틀면 은행이 나올것이다. 그러면 Mallory는 은행을 털 수 있다. 따라서 chip안의 SW구현도 중요하다!
Attack Surfave of Set-UID Programs
사용자의 입력으로 부터
사용자가 제어할 수 있는 시스템 입력을 통해서
환경변수
사용자에 의해 제어되는 비특권 프로세스 이용
1. 사용자의 입력
버퍼 오버플로우
Format String Vulerability ( string형태로 유저입력을 받았을 때 프로그램을 바꿈)
chsh 명령어
default shell을 바꾸는 명령(setUID 프로그램이다)
shell 프로그램은 /etc/passwd 파일의 마지막 filed에 표시되어 있음.
입력값은 두개의 줄을 포함할 수 있다. 따라서 첫번재 라인은 정상적이고 두번째 라인에 root 계정을 만들도록 할 수 있다.
혹은 만약 공격자가 3, 4번째 필드(UID, GID)에 0을 넣는다면 root 계정을 만들 수 잇다.
시스템 inputs (사용자가 통제 가능한 시스템 input을 통해서도 setUID 프로그램 공격이 가능하다.) 경쟁 조건
2. 환경변수
환경 변수를 사용해서 setUID 프로그램 공격이 가능하다.
환경 변수는 printenv나 env명령어를 통해 확인 가능하다.
등호 앞에 있는 것이 환경변수이고 오른쪽이 환경변수에 들어있는 값이다. (PWD = /home/scho)
일반적으로 파일의 경로를 지정할때 절대 경로나 상대 경로를 지정할 수 있다. 모든 명령들은 어떠한 폴더 아래에 존재한다.
system("/bin/sh") => 값을 입력받아 명령을 수행함을 알 수 있다. system(ls)를 할 경우 운영체제가 알아서 경로를 찾아서 ls를 실행한다. 이때 환경변수를 사용하여 알아서 경로를 찾음 echo path를 하면 :로 경로가 구분되어있고 처음 경로부터 해당 경로에 파일이 있는지 찾는다. path라는 환경변수에 등록된 경로들 순서대로 명령을 찾는다.
cd /home/attacker vi attack.c gcc -o ls attack.c export PATH=/home/attacker/:$PATH:/home/user1/bin
이러한 상황에서 공격자가 home 밑의 attack 파일을 만든다. 그리고 실행파일을 ls로 하고 환경변수를 바꾼다. 그러면 ls를 명령으로 입력하였을때 /bin/ls가 아닌 /home/attacker/ls가 실행된다.
Capability Leaking
자격 유출 어떤 특권 프로그램은 실행 중에 자기 자신의 권한을 다운그레이드한다. 대표적으로 su라는 명령어는 switch user로 사용자를 바꾸는 명령어다. setUID프로그램이다.
예시로 user1에서 user2로 바꿀때, EUID는 root이고 RUID는 user1이다. 그리고 비밀번호가 확인되었을때 RUID와 EUID는 동일하다. 그리고 EUID는 root에서 user2로 내려간다.
<set UID 프로그램의 소스>
/etc/zzz의 owner는 root이고 root만 writable하다.
fd 0은 표준입력 , 1은 표준 출력, 2는 표준에러이고 프로세스가 생성되자마자 default로 open된다.
따라서 open성공시 fd는 3이된다.
setuid(getuid()) => real uid를 가져와서 euid로 설정한다. (실행하는 사람은 root가 아님)
새로운 shell을 실행한다. 그 프로세스는 이전에 open된 파일을 그래도 상속한다. (fd 0, 1, 2, 3)
cap_leak을 owner를 root로 하고 setUID bit를 설정한다.
/etc/zzz에 쓰기를 할 수없다.
하지만 cap_leak을 실행하면 파일의 owner인 root의 권한으로 상승되고, fd를 상속받았으므로 fd 3이 open된 /etc/zzz이고 그곳에 ccccccccccc가 적혀진다.
그리고 새로운 쉘을 빠져나오면 ccccccccccccccc가 쓰여진 것을 알 수 있다.
높은 권한을 가진 EUID가 중요한 파일을 open한 상태로 새로운 shell이 상속받아 문제가 발생하였다.
getuid : real user ID
geteuid : effective user ID
setuid : set effecitive user ID
3. Invoking Programs
하나의 프로그램 내에서 외부 명령어 수행
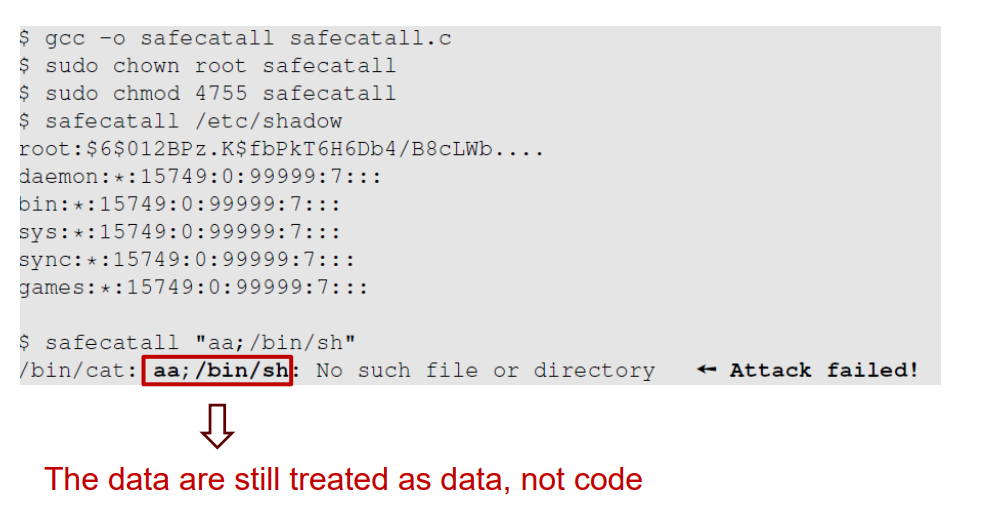
외부 명령어가 setUID 내에서 실행된다면 안전하지 않거나 엉뚱한 결과를 보여줌
공격 : 사용자는 명령에 대한 입력 데이터를 줌, 명령이 제대로 호줄 되지 않으면 유저 입력 데이터는 명령어 이름으로 될 수 있음.
system은 외부 명령어를 호출하는 함수이다.
root소유 setUID프로그램이다. 따라서 프로그램은 모든 파일을 볼 수 있지만 쓰기는 하지 못한다.
실행권한이 마지막 r-x이므로 누구나 실행이 가능하다.
';'은 shell에 두개 이상의 명령어를 줄 수 있게 한다. 예시) ls;ps ls;cp a b
(root가 owner인 setUId프로그램이기 때문에 shell이 뜰때 root shell이 뜬다. => $가 아니라 #)
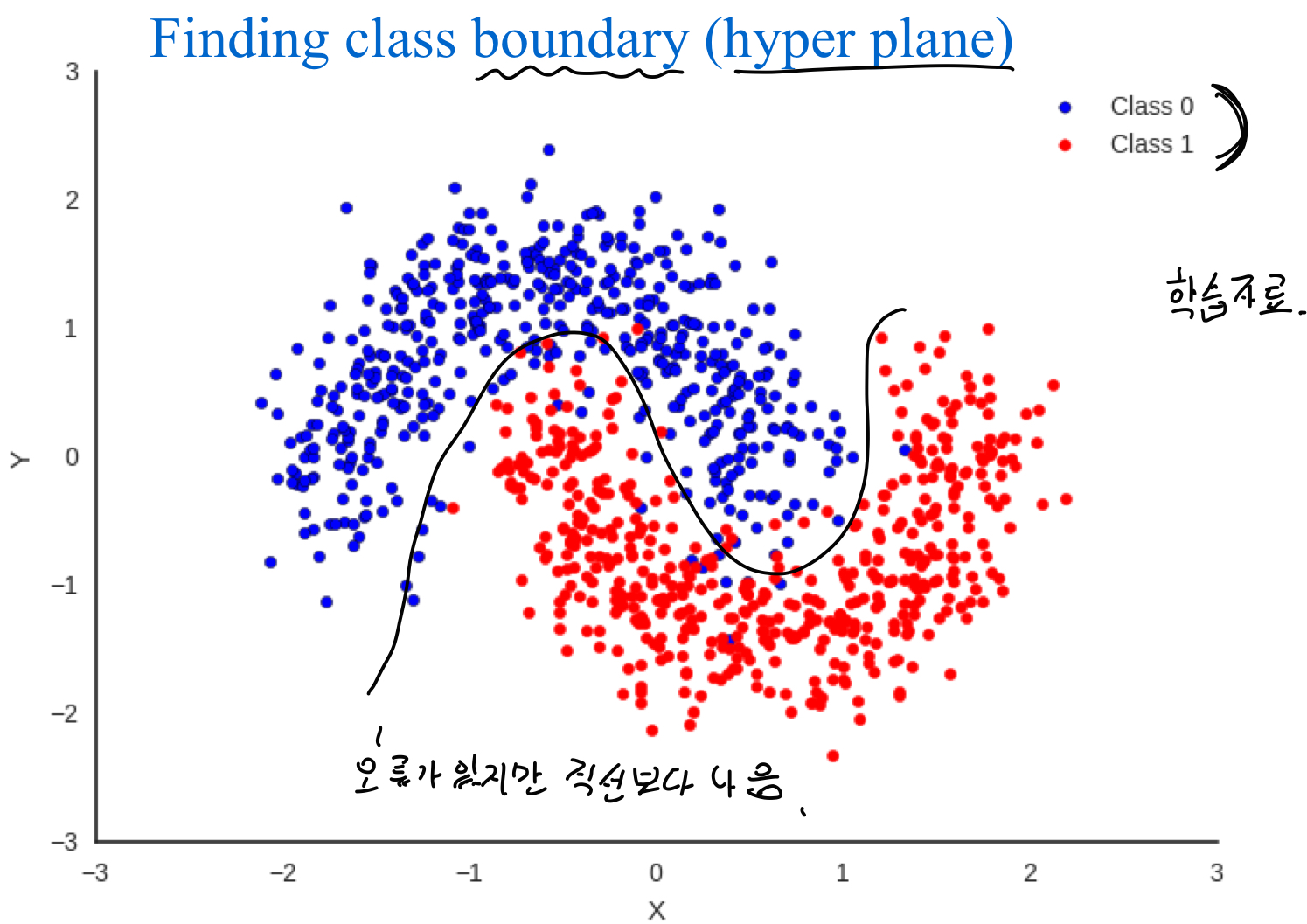
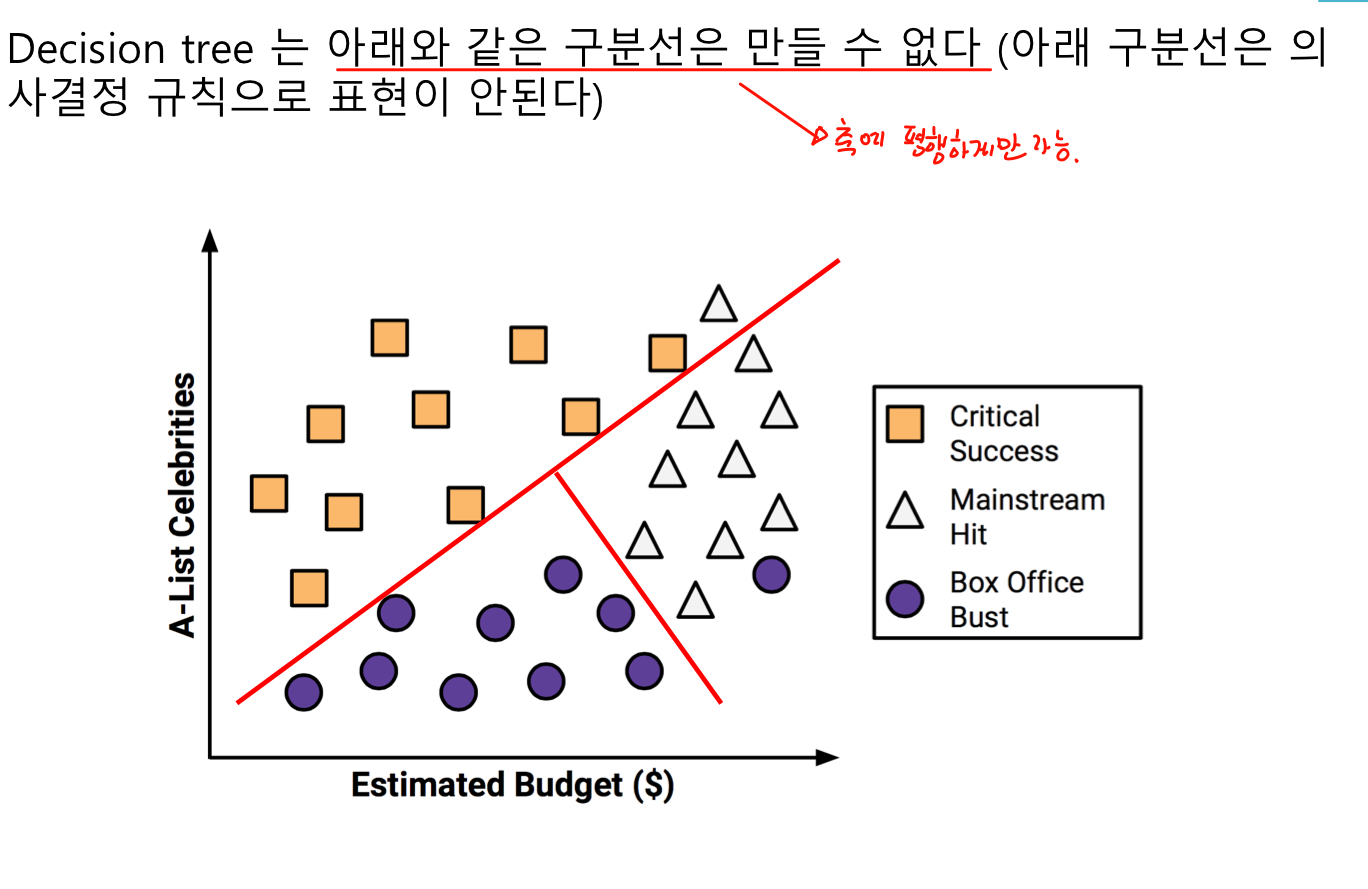
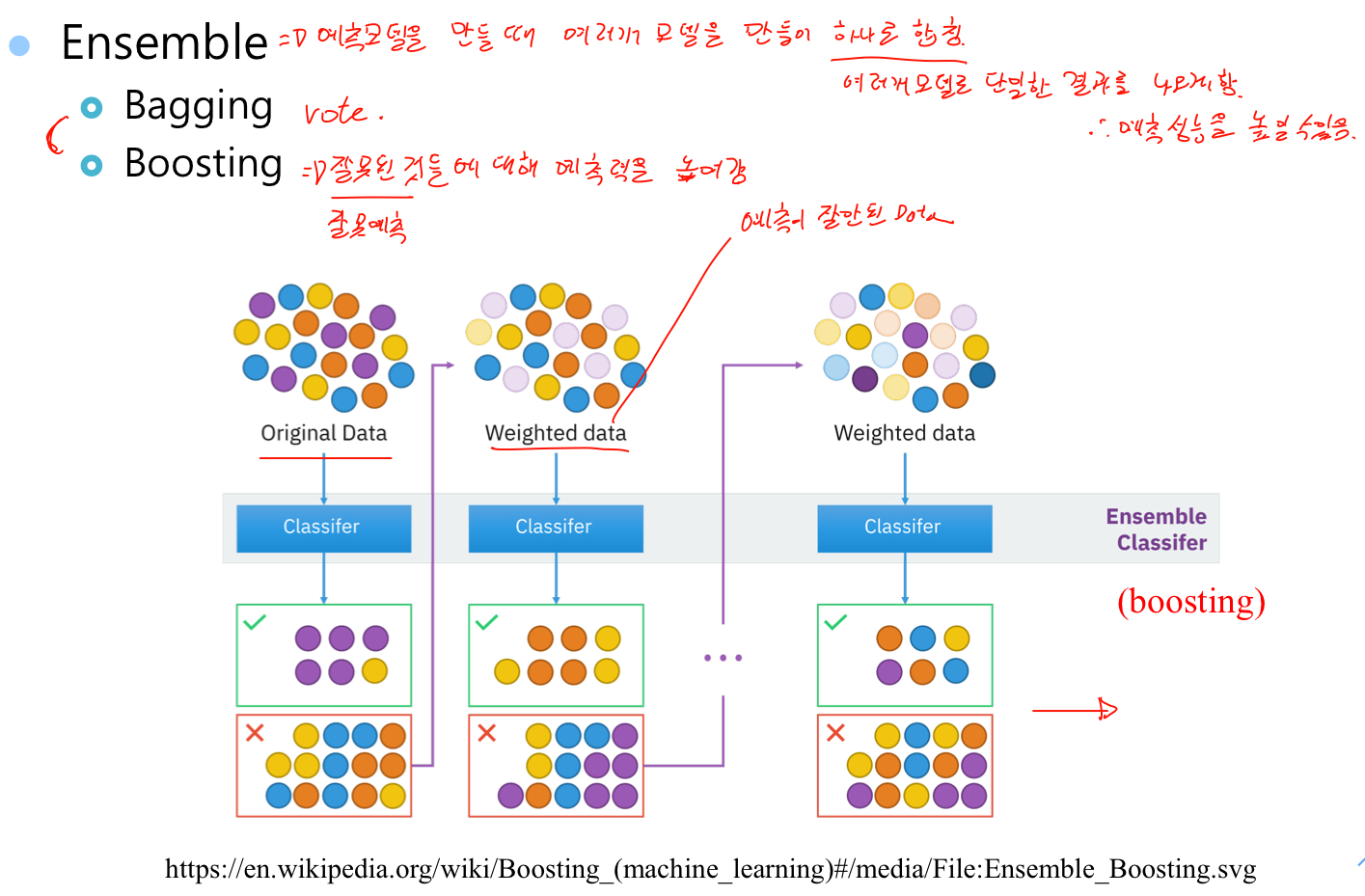
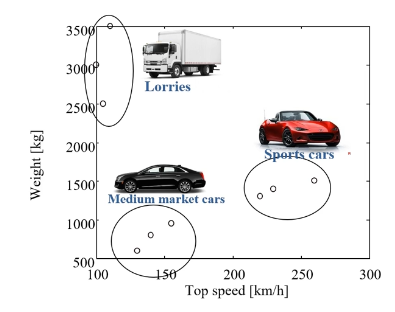
Learing for classification => class를 나누는 경계선을 찾는 문제였음
경계선을 직선으로 할 경우 오류가 많지만 곡선으로 할 경우 오류가 줄어들음
Scikit-learn classifiers
Logistic regression
KNN'
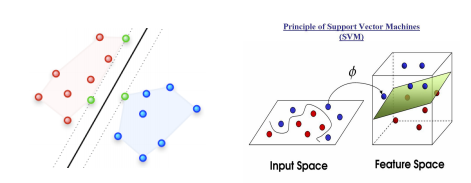
Support Vector Machine (SVM)
Naive Bayes
Decision Tree
Random Forest
AdaBoost
xgboost(Not in scikit-learn)
여러 classifier들이 있지만, 어떤 방법이 현재 가지고 있는 데이터에 대해 가장 효과적인지 사전에 알 수 없다. 따라서 모든 방법을 해보고 그 중에 좋은 것을 선택해야한다.
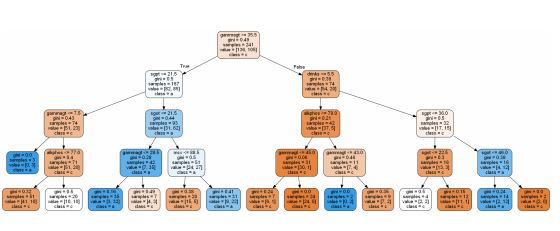
1. Decision Tree
큰 문제를 작은 문제들의 조각으로 나누어 해결한다.
예측을 위한 모델이 만들어졌을때, Tree의 형태로 나온다.
Tree형태이기때문에 결론이 나온 이유를 이해하기 쉽다. => 예측 결과에 대해서 근거가 명확하다
예를 들면 의료분야에서 질병진단시 근거가 명확해야한다.
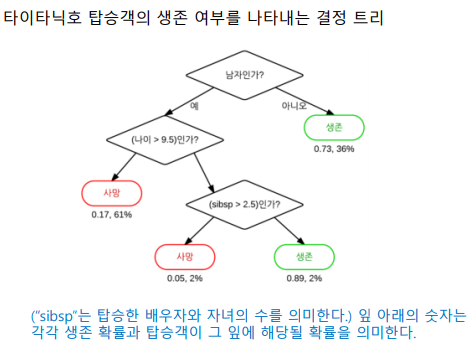
1.1 Decision Tree 예시
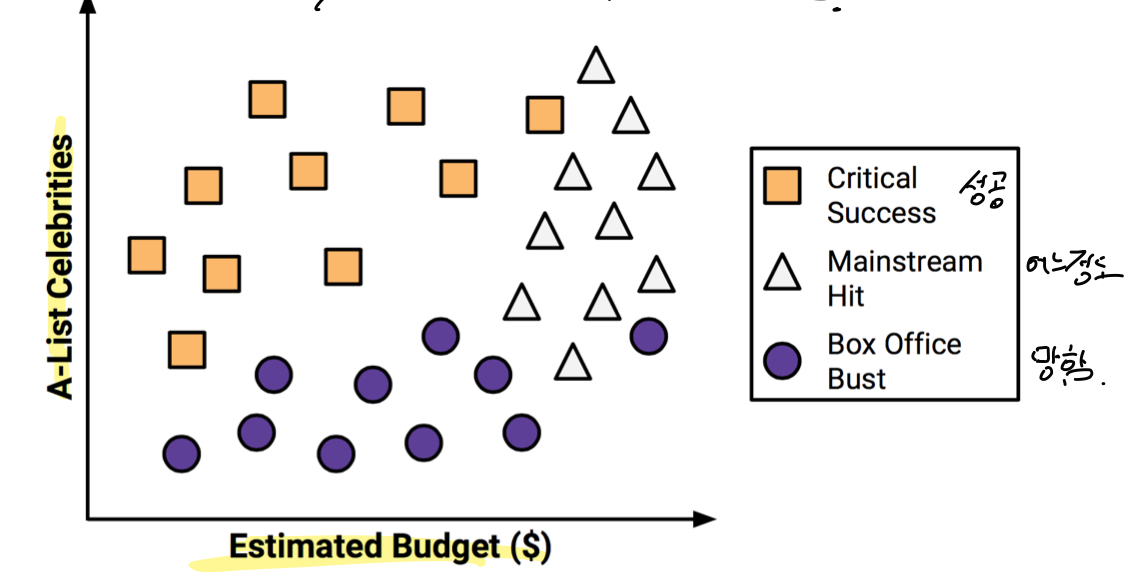
영화 대본 및 기본 정보를 이용하여 영화가 흥행할지 예측하는 모델
유명 배우수와 추정 제작비로 예측
결과는 매우흥행, 어느정도 흥행, 폭망으로 3가지로 구분
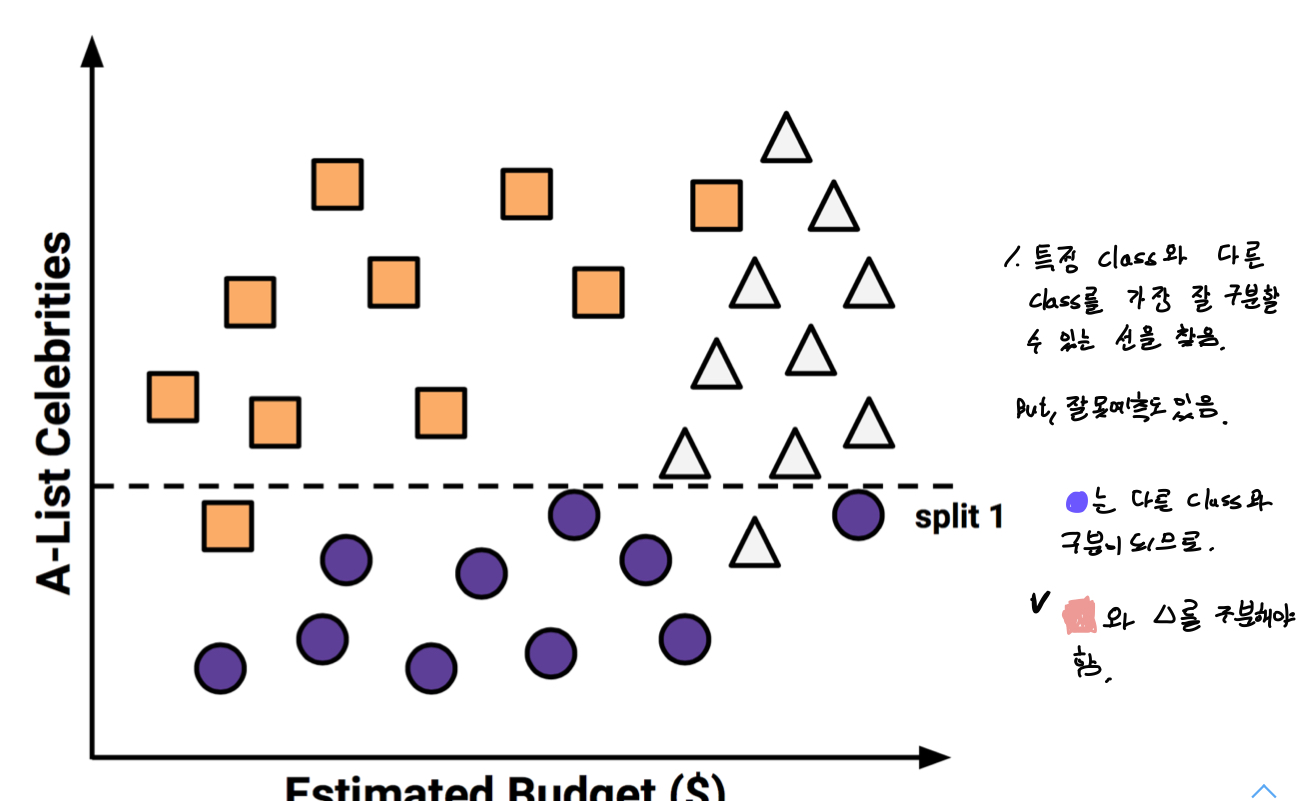
특정 class와 다른 class를 가장 잘 구분할 수 있는 선을 찾는다. 하지만, 잘못 예측한 경우도 있다.
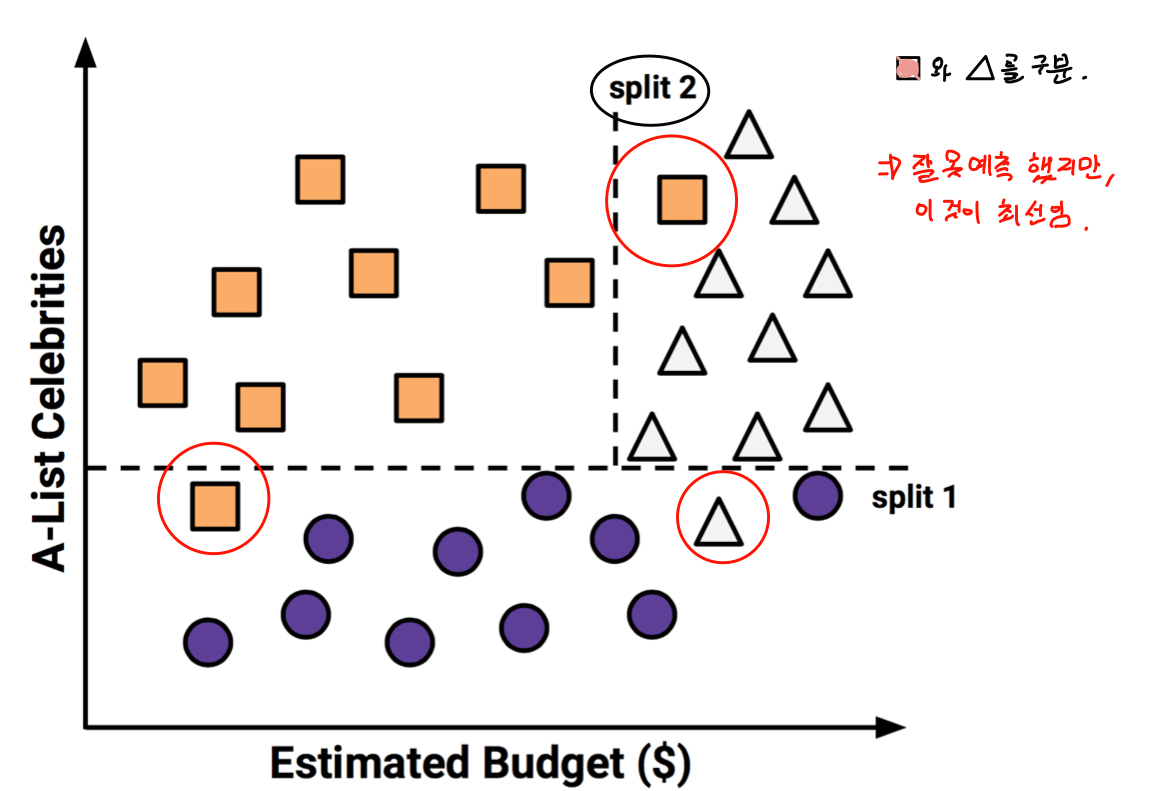
다른 class를 다시 구분하는 선을 찾는다. 잘못 예측한 것들이 있지만 최선이다.
결과
1.1.1 문제점
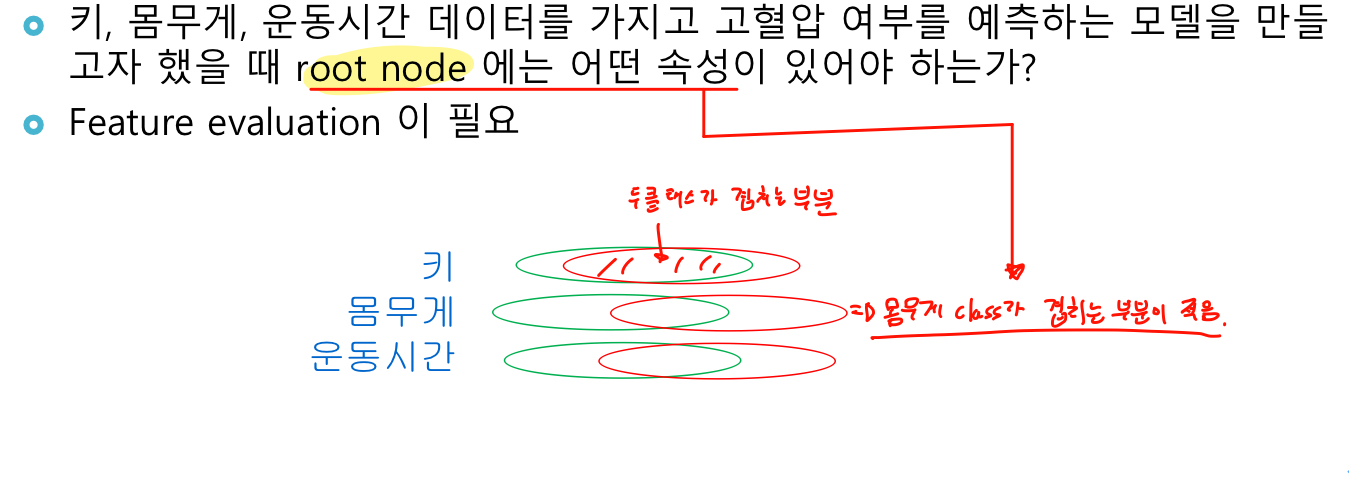
트리의 node를 선택 할 때 데이터 셋에서 어떤 속성을 선택할 것인가? => 이전 영화문제에서는 유명배우가 많으면서 예산이 적어야 성공한 영화였다. 그러면 스타급 배우수가 먼저인가? 예산이 먼저인가?
사진과 같이 class가 겹치는 부분이 적은 것을 선택한다.
트리를 split할 때 언제 중단할 것인가? => 트리의 가지를 계속 뻗어나가면 모든 instance를 100%t식별 할 수 있다. 하지만 overfitting발생
적당할 때 트리생성을 중단 해야한다. -> 가지치기(pruning) 경계선을 많이 나누면 이론상으로 100% 예측 가능한 tree를 만들 수 있다. 하지만 test 정확도는 낮다.
1.1.2 장점
모든 문제에 적합
결측치, 명목속성(범주), 수치속성을 처리하기에 용이
여러 속성중 중요한 속성들만 사용하여 예측
매우 많은 수 또는 상대적은 훈련 데이터로도 모델 구축 가능
수학적 배경이 없이도 해석이 가능한 모델
단순한 이론적 근거에 비해 높은 효율성
1.1.3 단점
결정 트리는 다수의 레이블을 가진 속성쪽으로 구분하는 경향이 잇음
모델이 쉽게 과적합(overfitting)하거나 과소적합(underfitting) 됨
축에 평행한 구분선을 사용하기 때문에 일부 관계를 모델화 하는데 문제가 있다.
훈련 데이터에 대해 약간의 변경이 결정 논리에 큰 변화를 준다.
큰 트리는 이해하기 어렵고 직관적이지 않다.
1.1.4 코드
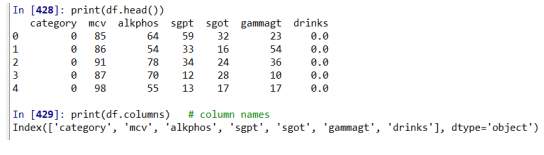
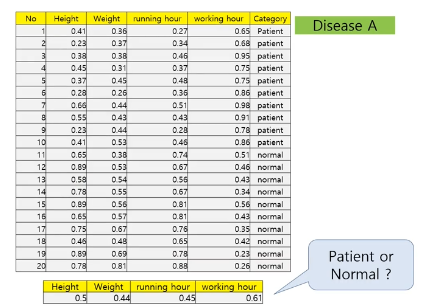
예시) liver.scv (간 장애 자료, 레이블 + 혈액검사 결과(6개 변수))
category mcv alkphos sgpt sgot gammagt drinks
category = 클래스 정보. 0 : 정상 1 : 간장애
데이터 셋 준비
설명변수/반응변수 구분
train/test 셋 나눔
모델 만듬
모델 training
튜닝
from sklearn.tree import DecisionTreeClassifier, export_graphviz //export_graphviz는 tree시각화에 필요
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
import pandas as pd
import pydot # need to install
#1. 데이터 셋 준비
# prepare the iris dataset
df = pd.read_csv('D:/data/liver.csv')
print(df.head())
print(df.columns) # column names
#2. 설명변수/반응변수 구분
df_X = df.loc[:, df.columns != 'category']
df_y = df['category']
#train/test 셋 나눔
# Split the data into training/testing sets
train_X, test_X, train_y, test_y = \
train_test_split(df_X, df_y, test_size=0.3,\
random_state=1234)
#4. 모델 만듬
# Define learning model (basic)
model = DecisionTreeClassifier(random_state=1234)
#5. 모델 학습
# Train the model using the training sets
model.fit(train_X, train_y)
# performance evaluation
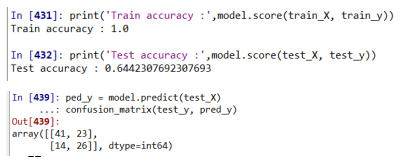
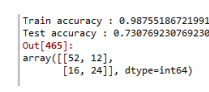
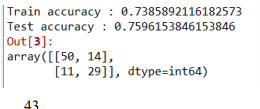
print('Train accuracy :',model.score(train_X, train_y))
print('Test accuracy :',model.score(test_X, test_y))
#6. 튜닝
# Define learning model (tuning)
model = DecisionTreeClassifier(max_depth=4, random_state=1234)
# Train the model using the training sets
model.fit(train_X, train_y)
# performance evaluation
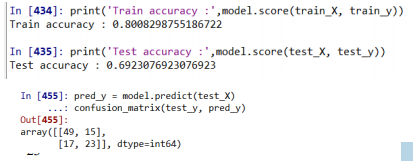
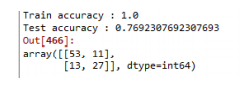
print('Train accuracy :',model.score(train_X, train_y))
print('Test accuracy :',model.score(test_X, test_y))
### 튜닝 후 test 정확도가 69%로 더 좋아진 것을 알 수 있다. 그러므로 매개변수를 잘 조절하면 모델의 성능이 좋아진다.
모델을 만들 때, 모델의 성능에 여향을 끼치는 매개변수들이다. 따라서 Hyper parameter를 어떻게 조절하냐가 중요하다. 그러나 매개변수가 20개 가까이 되므로 다 조절하기는 힘들다. 그러므로 몇개의 자료로 추린다.
criterion : String, optional (default = "gini") Decision Tree의 가지를 분리 할 때, 어떤 기준으로 정보 획득량을 계산하고 가지를 분리 할 것인지 정함 gini = entropy보다 빠르지만 한쪽으로 편향된 결과를 낼 수 있음 entropy = gini에 비해 조금 더 균형잡힌 모델을 만들 수 있다.
max_depth : int or None, optional(default = None) Decision Tree의 최대 깊이 제한을 줄 수 있음 사전 가지치기를 하고 voerfitting을 방지 할 수 있음
min_sample_split : int, float optaional(default = 2) 노드에서 가지를 분리할 때 필요한 최소 sample 개수에 대한 제한을 줄 수 있음. 주어진 값에 type에 따라 다음과 같이 기능함 int -> 주어진 값 그대로 사용 float -> 0,1사이의 값을 줄 수 잇음,. cell(전체 데이터수 * min_sample_split)의 값을 사용함
min_sample_leaf : int, float optaional(default = 2) 한 노드에서 가지고 있어야 할 최소 sample 개수에 대한 제한을 줄 수 있음.주어진 값에 type에 따라 다음과 같이 기능함 int -> 주어진 값 그대로 사용 float -> 0,1사이의 값을 줄 수 잇음,. cell전체 데이터수 * min_sample_leaf)의 값을 사용함
max_features : int, float, string or None, optional(default = None) Decision Tree model을 만들 때 사용할 수 있는 변수의 개수를 제한을 줄 수 있음 int -> 주어진 값 그대로 사용 flaot -> int(max_features * 총변수 개수) 사용 None -> 총 변수 개수 사용
class_weight : dict, list of dict or "balanced", default=None 예측 할때 두개의 class의 중요도가 다른 경우가 있다. 예로 환자 판단시, 정상을 정상으로 진단하는 것보다 환자를 환자로 진단하는 것이 더 중요하다 그러므로 정상:환자 = 6:4 와 같이 비율을 정한다. class_label: weight
1.2 Random Forest
N개의 Decision Tree가 투표를 통해 결정하는 방식이다.
Bagginf approach중 하나임. -> 여러 모델을 합쳐서 결론냄
주어진 데이터에서 랜덤하게 subset을 N번 sampling해서(좀 더 정확하게 observations와 features들을 랜덤하게 sampling) N개의 예측 모형을 생성
개별 예측 모형이 voting하는 방식으로 예측결과를 결정하여 Low Bias는 유지하고 High Variance는 줄임
Random Forest는 이런 Bagging 계열의 가장 대표적이고 예측력 좋은 알고리즘
1.2.1 코드
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
import pandas as pd
# prepare the iris dataset
df = pd.read_csv('D:/data/liver.csv')
print(df.head())
print(df.columns) # column names
df_X = df.loc[:, df.columns != 'category']
df_y = df['category']
# Split the data into training/testing sets
train_X, test_X, train_y, test_y = \
train_test_split(df_X, df_y, test_size=0.3,\
random_state=1234)
# Define learning model (# of tree: 10) #################
model = RandomForestClassifier(n_estimators=10, random_state=1234) # n_estimators = 트리 수
# Train the model using the training sets
model.fit(train_X, train_y)
# performance evaluation
print('Train accuracy :', model.score(train_X, train_y))
print('Test accuracy :', model.score(test_X, test_y))
pred_y = model.predict(test_X)
confusion_matrix(test_y, pred_y)
# Define learning model (# of tree: 10) #################
model = RandomForestClassifier(n_estimators=10, random_state=1234)
# Train the model using the training sets
model.fit(train_X, train_y)
# performance evaluation
print('Train accuracy :', model.score(train_X, train_y))
print('Test accuracy :', model.score(test_X, test_y))
pred_y = model.predict(test_X)
confusion_matrix(test_y, pred_y)
# Define learning model (# of tree: 50) #################
model = RandomForestClassifier(n_estimators=50, random_state=1234)
# Train the model using the training sets
model.fit(train_X, train_y)
# performance evaluation
print('Train accuracy :', model.score(train_X, train_y))
print('Test accuracy :', model.score(test_X, test_y))
pred_y = model.predict(test_X)
confusion_matrix(test_y, pred_y)
어떻게 컴퓨터가 그룹을 나누느냐? => 거리가 가까운것 끼리 묵음 따라서 거리 계산이 중요함.
Classification
데이터들이 그룹이 나누어져있고 알고 있음
새로운 데이터가 들어왔을때, 어디에 속할지 판단함
예측, 의료에서 진단 분야에서 사용됨.
주로 많이 사용함.
범주데이터를 주므로 지도학습임.
예시 : clustering
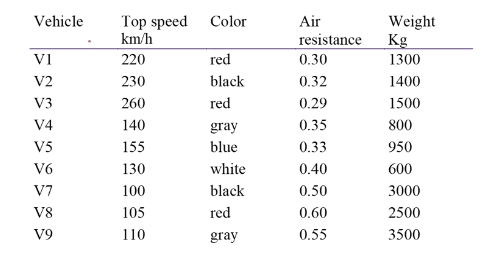
차량의 특성을 가지고 grouping
산점도를 그림
점이 모이는 것을 확인할 수 있음
그룹이 지어지면 해석이 가능해짐, 그룹의 특징을 해석해서 활용함
혹은 비정상 거래 판단시, 주류범주에 속하지 않으면 비정상 거래로 탐지
예시 : classification
이미 그룹이 만들어져 있음
ex) 병원 새로운 사람이 왔을때 환자인지 정상인지 판단
어떤 class에 속하는지 찾아봄
Binary vs multiple classfication
Binary classification
class 의 수가 2개인 경우
좀 더 쉬움 = 모델의 정확도가 높음
multifple classfication
class의 수가 3개 이상인 경우
K-means clustering
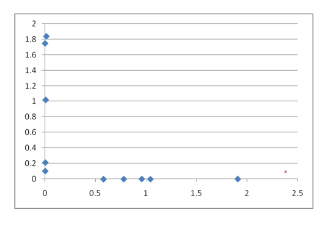
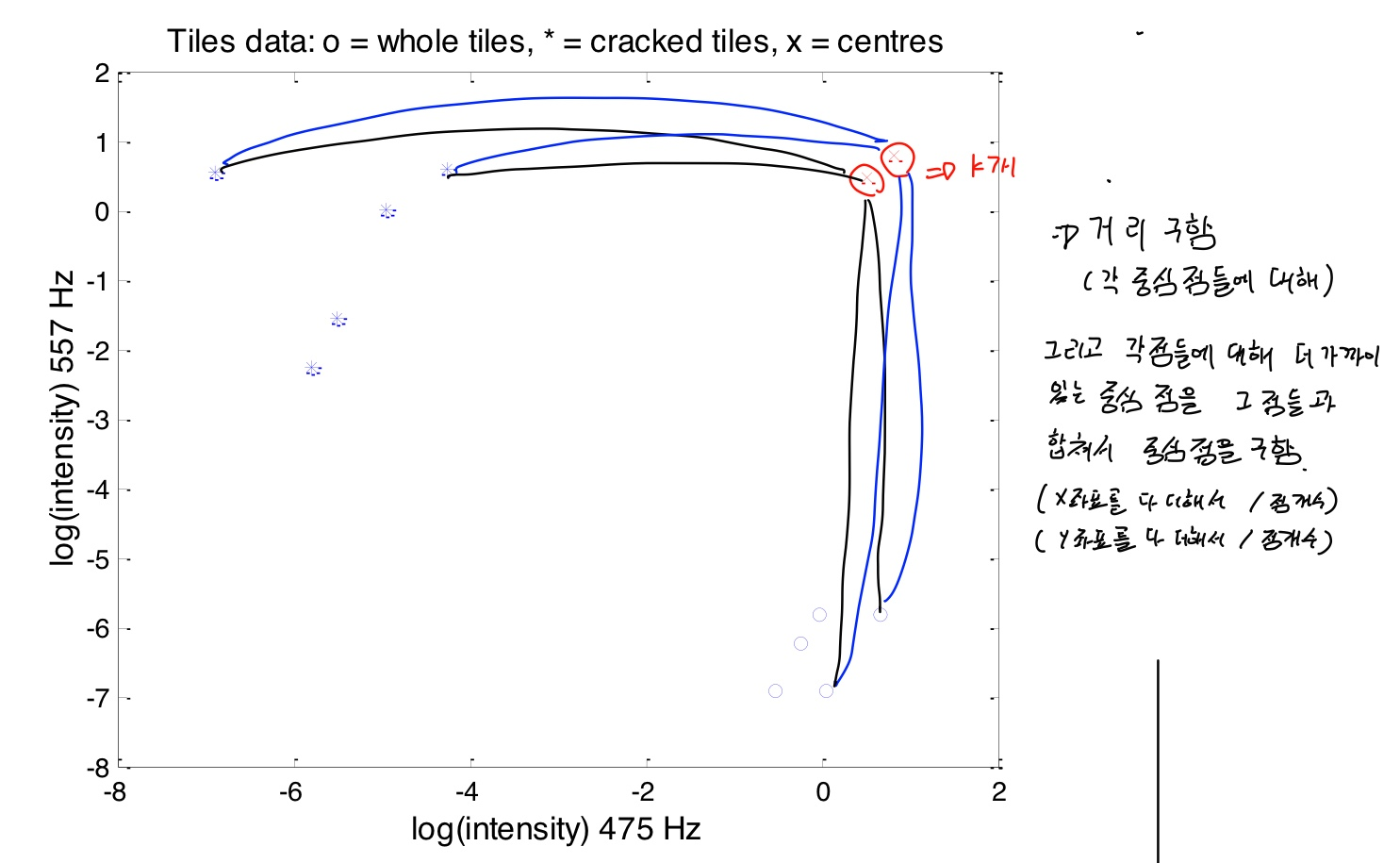
예시 : 금이간 타일과 정상 타일 군집화
크랙이 있는 것과 없는 것은 소리(주파수)가 다름
clustering을 하였을때, 금이 간 것과 안 간것끼리 class가 나뉘어야 사용할 수 있음
주의) log값을 취하여 사용함. 왜냐하면 scale을 맞추어 왜곡값을 줄이기 위하여임(그러지 않을 경우 값들이 x, y축에 붙음)
두개의 그룹으로 확연하게 분리됨
k = 클러스터의 수 => 따라서 2개(금간것, 안간것)
임의로 점 두개를 찍음( k 개수 만큼)
이 점이 각 클러스터의 중심점이 됨
중심점과 점들의 거리를 구함
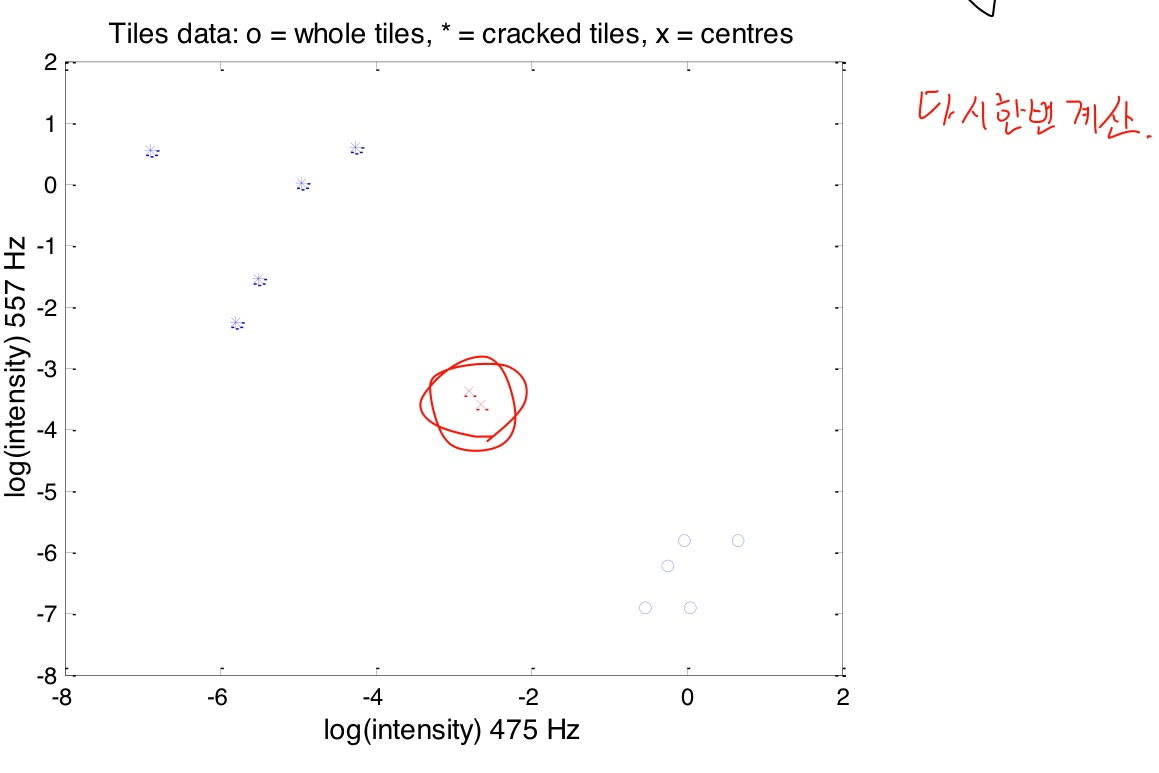
각 점들에 대해 더 가까이 있는 중심점을 그 점들과 합쳐서 중심점을 구함(x 좌표 평균, y 좌표 평균이 새로운 중심점)
반복하여 계산함
더 이상 안움직이는 때(움직임이 작을 때)가 오면 그룹의 중심을 찾았다는 뜻이다. 그러면 중심점들과 점 사이 거리를 계산하여 그룹을 찾는다.
두 그룹이 금간 것, 안간 것으로 구분이 되면, 이것으로 새로운 것이 들어왔을때 판단을 한다(중심점으로)
거리계산법
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
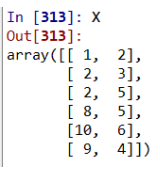
X = np.array([[1,2], [4,3], [2,5],
[8,5], [10,6], [9,4]])
kmeans = KMeans(n_clusters=2, random_state=0).fit(X)
n_clusters : 클러스터의 개수
random_state : seed for reproducability => 클러스터 중심점 위치를 랜덤하게 찍기위해
# cluster label
kmeans.labels_ #클러스터 번호 알려줌
# bind data & cluster label
np.hstack((X, kmeans.labels_.reshape(-1, 1))) #lable을 포함하여 X를 보여줌, 세로로 바꾸어 합침
# center of clusters
kmeans.cluster_centers_ #중심점의 좌표값을 보여줌
# predict new data
kmeans.predict([[0, 0], [12, 3]]) #예측
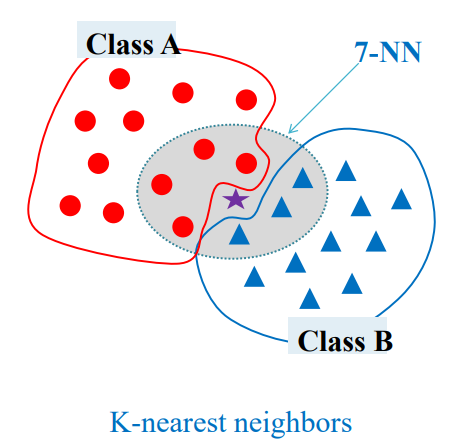
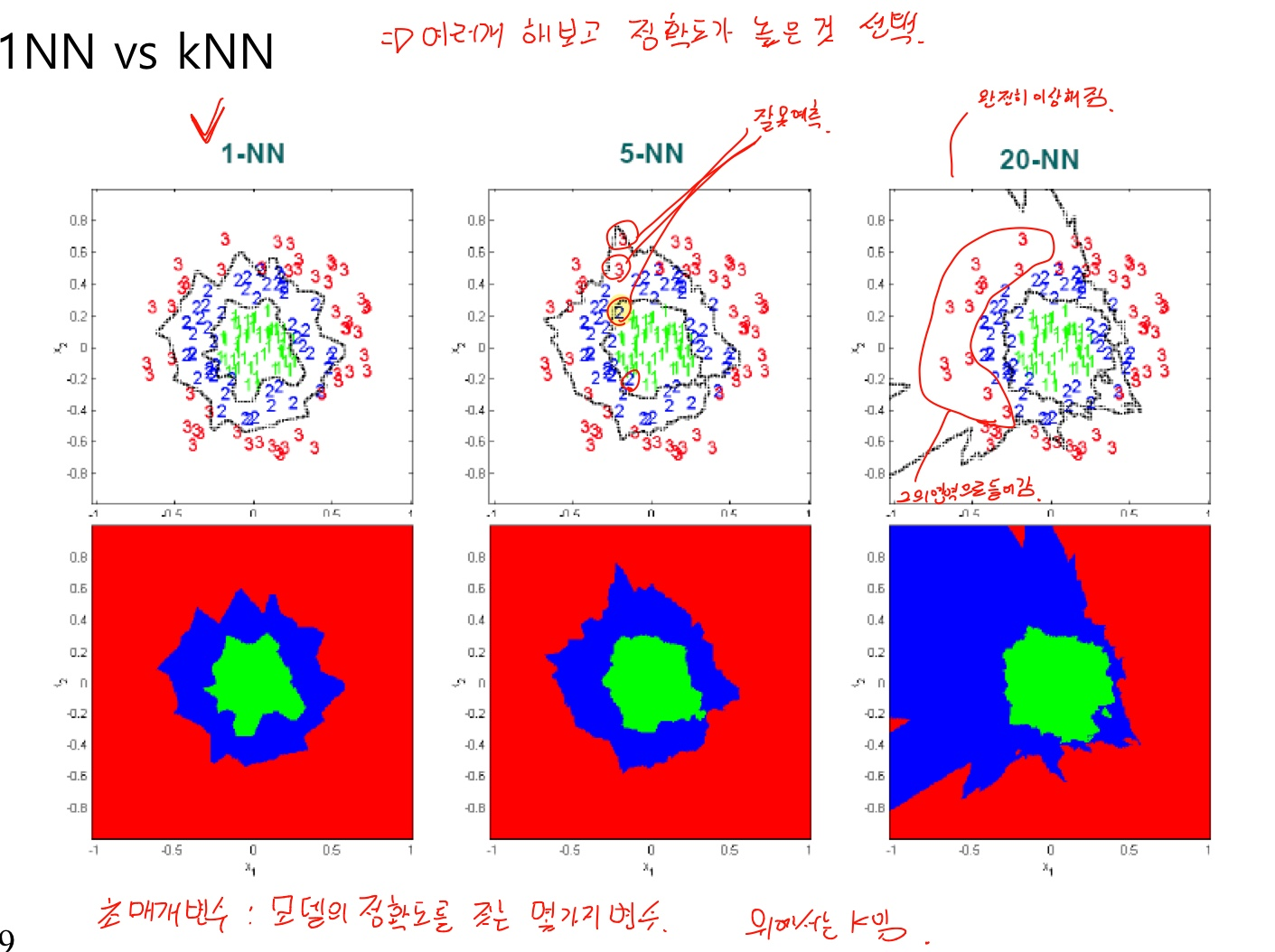
KNN classifier
분류(classification)
어느 카테고리에 속할것인가?
idea of KNN
모르는 데이터와 알려진 데이터 중 모르는 데이터에 가까운 것들을 추림
K-NN : K는 몇개를 추릴 것인지
그러면 K개 중 많은 것을 따름(다수를 따라감)
가까운 이웃을 판단하기 위해선 거리를 다 계산함(모르는 데이터와 알려진 데이터들 사이의 거리)
K는 홀수로 하여야 모르는 데이터가 어디에 속할 지 정하기 쉬움
계산
K의 값은 데이터의 수가 N이라 할 때, K < sqrt(N)을 권장
K가 클때와 작을때 각각 장단점이 있음
K개수에 따라 정확도가 달라지므로 여러개를 해보고 그중 정확도가 높은 것을 선택해야한다.
이러한 모델의 정확도에 영향을 미치는 변수를 초매개변수라 한다. 정확도가 높은 초매개변수를 찾는 것이 중요함
장점
통계적 가정 불필요(머신러닝 초기 모델들은 통계에 기반하여, 데이터는 정규분포를 따른다는 가정을 했다. 따라서 가정을 벗어난 데이터는 예측이 불가능했다)
단순하다
성능이 좋다
모델을 훈련하는 시간이 필요없다 (모델을 만드는 과정이 없음, 데이터를 바로 찾아서 결과를 냄 )
단점
데이터가 커질수록 많은 메모리가 필요하다
데이터가 커질수록 처리시간(분류시간)이 증가한다.
모르는 값이 있을 때, class를 구하려면 거리계산을 다 해주어야한다. 따라서 메인메모리에 모든 값이 있어야한다. 그리고 모두 거리계산을 해주어야한다.
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Load the iris dataset
iris_X, iris_y = datasets.load_iris(return_X_y=True)
print(iris_X.shape) # (150, 4)
# Split the data into training/testing sets
train_X, test_X, train_y, test_y = \
train_test_split(iris_X, iris_y, test_size=0.3,\
random_state=1234)
# Define learning model
model = KNeighborsClassifier(n_neighbors=3) #K값은 3임, 초매개변수 K = 3 (default값은 5임)
# Train the model using the training sets
model.fit(train_X, train_y)
# Make predictions using the testing set
pred_y = model.predict(test_X)
print(pred_y)
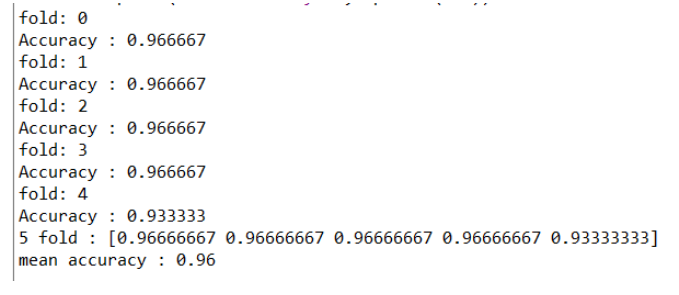
# model evaluation: accuracy #############
acc = accuracy_score(test_y, pred_y)
print('Accuracy : {0:3f}'.format(acc))
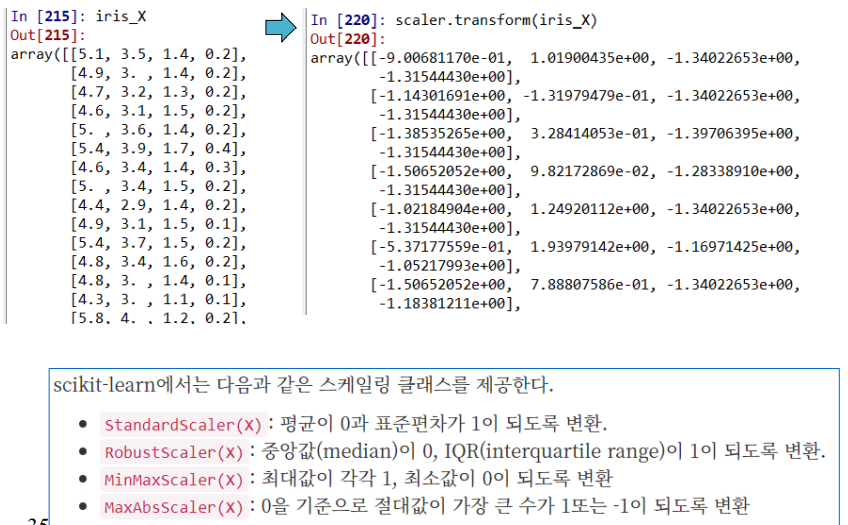
Dataset scaling
거리기반 학습방법을 적용할 때는 scaling이 필요
예로 키, 시력을 비교시 (170, 0.8) 두 값간의 차이가 커서 시력의 거리 의미가 없어짐
따라서 두 크기의 스케일을 바꾸어 동등한 영향력을 가지게해야함.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler() # 정의
scaler.fit(X) # X : input data # 실행
X_scaled = scaler.transform(X) # 결과 얻음
Performance metric : 모델 성능 평가 척도
For Binary classification model only
Sensitivity
Specificity
precision
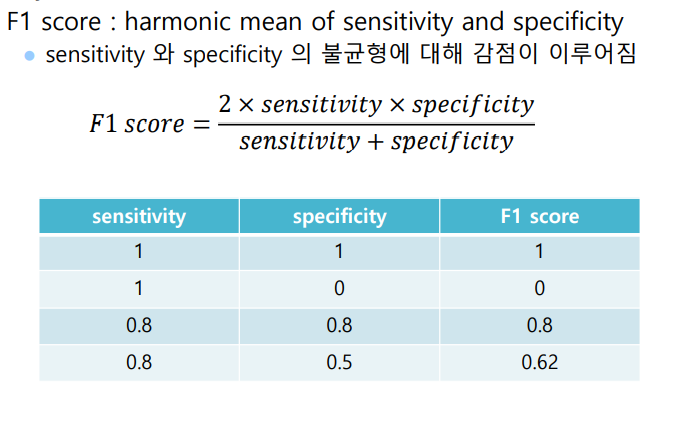
F1 score
ROC, AUC
For All classification model
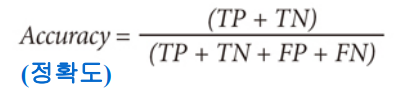
Accuracy
=> 평가 척도가 다양한 이유는 응용을 어디에 하느냐에 따라 모델 평가 척도가 달라지기때문
Binary classification metric
의료일 경우 FP인 경우, 음성을 양성으로 잘못 판단한 것이므로 정상을 비정상으로 진단한 경우다. FN인 경우 양성을 음성으로 잘못 판단한 것이다. 실제로 감염이 된 것인데 안되었다고 판단하므로 FN의 경우가 더 심각하다
민감도
- Sensitivity = TP/(TP+FN) => (실제 양성인데) 양성 판단 / 실제 양성
특이도
- Specifity = TN/(TN+FP) => (실제 음성인데) 음성 판단 / 실제 음성
정밀도
- Precision = TP/(TP+FP) => (실제 양성인데) 양성 판단 / 양성 판단
F1 ScoreBinary가 아닌 경우
class A, B, C가 있을경우
For class A : A는 Postive, B,C는 Negative
For class B : B는 Postive, A,C는 Negative
For class C : C는 Postive, A,B는 Negatvie => table을 만드는 경우 복잡하고 의미를 찾기 힘들다.
# module load
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.linear_modle import LinearRegression
from sklearn.metrics import mean_wquared_error, r2_score
from sklearn.model_selection import train_test_split
# prepare dataset
cars = pd.read_csv('D:cars.csv')
speed = cars['speed']
distance = cars['distance']
# data frame to npl.numpy => numpy 배열로 바꾸어주어야함
speed = np.array(speed).reshape(50,1)
distance = np.array(distance_.reshape(50,1) # 1차원 벡터가 되어야 하므로 (50,1)로 바꾸어줌 (2차원 벡터로)
# Split the data into training/testing sets
train_X, test_X, train_y, test_y = train_test_split(speed, distance, test_size=0.2, random_state=123)
# 인자 speed = x, distance = y, test_size-0.2 = 전체 개수 중 20%를 테스트로 사용하고 나머지를 trainning으로, random_State = 무엇이 test가 되고 train이 될지 랜덤하게 결정
# 학습 방법을 정해줌
model = LinearRegression()
# 학습 시킴
model.fit(train_X, train_Y)
# 예측함(테스트 셋으로 테스트함)
pred_y = model.predict(test_X)
print(pred_y)
# 예측
print(model.predict([[13]])
- [[]] 괄호 2개를 사용하는 이유는 predict는 배열이 들어가야하는데, 2차원 배열을 만들기 위해서 괄호 2개를 사용함
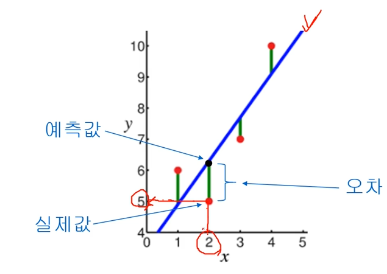
앞의 예시인 자동차의 속도를 가지로 제동거리를 예측할 경우, 단순히 제동거리는 주행속도에 의해 결정이 되진 않음!
따라서 다양한 요인을 넣는다면 오차는 줄어들 것임
예시 = 특정 직군의 연봉을 교육년수, 여성비율, 평판으로 예측
import pandas as ps
import numpy as np
from sklearn.linear_model import LinearRegression
from skleran.metrics import mean_squared_error, r2_score
from sklearn.model_selection import train_test_split
# split the data into training/testing sets
train_X, test_X, train_y, test_y = train_test_split(df_X, df_y, test_size=0.2)
# Dfine learing model
model = LinearRegression()
# Train the model using the training sets
model.fit(train_X, train_y)
# Make predictions using the testing set
pred_y = model.predict(test_X)
print(pred_y)
learning model은 같지만 내용은 달라짐 = 변수 3개
# The coefficient & intercept
print('cofficients: {0:.2f}, {1:,2f}, {2:.2f} Intercept {3:.3f}'.format(model.coef_[0], model.coef_[1], model.coef[2], model.intercept))
# The mean squared error
print('Mean squared error: {0:.2f}',format(mean_squared_error(test_y, pred_y)))
# The coefficient of determination: 1 is perfect prediction
print('Coefficient of determinaion: %.2f' % r2_score(Test_y, pred_y))
# Test single data
my_test_x = np.array([11.44, 8.13, 54.1]),reshape(1,-1) #행의 개수는 1, 열은 알아서 맞추어라(주어진 개수대로)
my_pred_y = model.predict(my_test_x) #예측값 얻음
print(my_pred_y)
Logistic regression
일반적인 회귀 문제는 종속변수가 수치데이터임
범주형 데이터를 예측할때, 회귀방법으로 구할때
예시 : iris 데이터셋이에서 4개의 측정 데이터로부터 품종(분류)을 예측
Logistic 회귀도 y값이 숫자임
from sklearn import datasets #dataset에 iris가 포함되어 잇음
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score # 모델 정확도가 오차를 사용하지 못함
# Load the diabetes dataset
iris_X, iris_y = datasets.load_iris(return_X_y=True) # 독립변수와 종속변수를 구분해서 가져옴
print(iris_X.shape)
# Split the data into training/testing sets
train_X, test_X, train_y, test_y = train_test_split(iris_X, iris_y, test_size=0.3, random_state=1234)
# Define learning model
model = LogisticRegression()
# Train the model using the training sets
model.fit(train_X, train_y)
# Make predictions using the testing set
pred_y = model.predict(test_X)
print(pred_y)
# model evaluation: accuracy #############
acc = accuracy_score(test_y, pred_y)
print('Accuracy : {0:3f}'.format(acc))
Accuracy = 예측과 정답이 일치하는 instance 수 / 전체 test instance 수
! 종속변수가 숫자여야하기 때문에 문자형으로 되어 있는 범주 데이터를 숫자로 변환해야됨 => LabelEncoder
from sklearn.preprocessing import LabelEncoder
import numpy as np
number = LabelEncoder() # 객체생성
label_str = np.array(['M','F','M','F','M'])
label_num = number.fit_transform(label_str).astype('int') # int로 바꾸어라 기준은 알파벳 순서대로 F =0, M = 1
print(label_str)
print(label_num)
최소한의 권한 (Least privilege). 각 사용자와 프로그램은 가능한 최소한의 권한을 사용하여 작동해야 한다. 이 원리는 사고, 에러 또는 공격으로부터의 손상을 제한하며 또한 권한을 갖는 프로그램간의 잠재적인 상호작용의 수를 저하시는데 따라서 의도되지 않은, 원하지 않은 또는 부적절한 권한 사용이 덜 일어나게 할 것이다. 이 개념은 프로그램의 내부로 확장될 수 있는데 이러한 권한을 필요로하는 프로그램의 가장 작은 부분만이 이러한 권한을 가져야 한다.
메카니즘의 효율적 사용/단순 (Economy of mechanism/Simplicity). 보호 시스템 설계는 가능한 단순하고 작아야 한다. 이들은 "소프트웨어의 라인별 검사 및 보호 메카니즘을 구현하는 하드웨어의 물리적 조사와 같은 기법들이 필요하다. 이러한 기법이 성공적이기 위해서는 작고 단순한 설계가 절대적으로 필요하다" 라고 논의하고 있다. 이는 때때로 "KISS ("keep it simple, stupid")" 라고 기술된다.
오픈 설계 (Open design). 보호 메카니즘은 공격자의 무지에 의존하지 않아야 한다. 대신 메카니즘은 패스워드 또는 비밀키와 같은 비교적 소수 (쉽게 변경될 수있는) 아이템의 기밀성에 의존하며 공개적이여야 한다. 오픈 설계는 상세한 공개적 조사를 가능하게 하며 또한 사용자 자신이 사용하고 있는 시스템이 합당함을 깨닫게 할 수 있다. 솔직히 널리 배포되어 있는 시스템에 대해 기밀을 유지하려고 하는 것은 현실적이지 않다; 디컴파일러와 파괴된 하드웨어는 구현시의 어떤 비밀을 재빨리 드러낼 수 있다. Bruce Schneier 은 스마트 엔지니어는 소스 코드가 폭넓은 검토를 받았으며 모든 확인된 문제가 수정되었음을 보장해야 할뿐만 아니라 보안과 관련된 모든 것에 대해 오픈 소스 코드를 요구해야 한다고 주장하고 있다
완벽한 조정 (Complete mediation). 모든 접근 시도가 검사되어야 하는데 메카니즘이 파괴될 수 없도록 이를 위치시켜라. 예를 들어 클라이언트-서버 모델에서 일반적으로 서버는 사용자가 자신의 클라이언트를 구축 또는 수정할 수 있기 때문에 모든 접근 검사를 해야 한다.
고장 안전 디폴트 (Fail-safe defaults (예, 허가권 기반 접근 방법). 디폴트는 서비스 부인이어야 하며 보호 체계가 접근이 허가되는 조건을 확인해야 한다.
권한 분리 (Separation of privilege). 원칙적으로 객체에 대한 접근은 한가지 이상의 조건에 의존해야 하며 따라서 한가지 보호 시스템을 무너뜨려도 완전한 접근을 할 수 없을 것이다.
최소한의 공통 메카니즘 (Least common mechanism). 공유 메카니즘 (예, /tmp 또는 /var/tmp 디렉토리 사용) 의 수와 그 사용을 최소화해라. 공유 객체는 정보 흐름 및 의도되지 않은 상호작용에 대해 잠재적으로 위험한 채널을 제공한다.
심리학적 수용성/사용의 편리함 (Psychological acceptability/Easy to use). 휴먼 인터페이스는 사용하기 쉽도록 설계되어야 하며 따라서 사용자는 일상적 및 자동적으로 보호 메카니즘을 정확히 사용할 것이다. 보안 메카니즘이 사용자가 보호하려는 목적의 정신적 이미지와 밀접하게 일치된다면 실수는 줄어들 것이다.
Set- UID Privilieged Programs
Need for Privilieged Programs
예를 들어 /etc/shadow 파일의 권한을 보면
-rw-r----- 1 root shadow 1443
~
=> 오직 오너만이 write할 수 있다.
하지만 일반 유저들이 그들의 비밀번호를 바꿀때 어떻게 바꿀 수 있을까? 특권 프로그램을 이용해서 바꾼다
일반적으로 운영체제 내에서 세부적으로 접근 제어를 하는 것은 굉장히 복잡하다. rwx 3가지 권한을 세부적으로 할 경우 write를 1. 앞에 2. 중간에 3. 뒤에 와 같이 3가지로 나눌 수 있다. 하지만 복잡해진다.
따라서 rwx + 3bits 총 12비트로 permission을 나타낸다. (확장, fine-grained access control을 위해 3bits를 추가한다.)
일반적으로 OS가 제공하는 접근제어를 바로 사용가능하지만 (e.g system call) 특별한 경우(e.g root가 가진 파일 수정)는 특권 프로그램이 필요하다! => setUID가 설정된 프로그램이 필요하다! 혹은 daemons (관리자(super user)를 믿는다고 가정한다. 일반 사용자들은 특권 프로그램을 이용해서 바꿀 수 있다)
Different Type of Privileged Programs
Daemons in Linux (MS Windows 에서는 services) 백그라운드에서 계속 수행된다. 따라서 키보드로 부터 입력을 받을 수 없다. root나 특권을 가진 유저의 권한으로 실행해야한다.
만약 daemon에게 요청을 하고 요청이 타당하면 daemon이 수행한다. (특히 Network는 Service를 위해 daemon들을 많이 사용한다. ps - af, ef, af 등을 통하여 모든 프로세스들을 보면 d로 끝나는 것들이 있다. Network daemon을 뜻한다. => 중요한 일을 하므로 root의 권한을 주던지 어떤 특권이 있는 사용자의 권한으로 돌아간다. 중요한 일을 하므로 daemon을 임의로 만들지 못한다.
Set-UID Programs Unix 시스템에서 사용된다. 특정한 비트가 표시되어있는 프로그램이다.
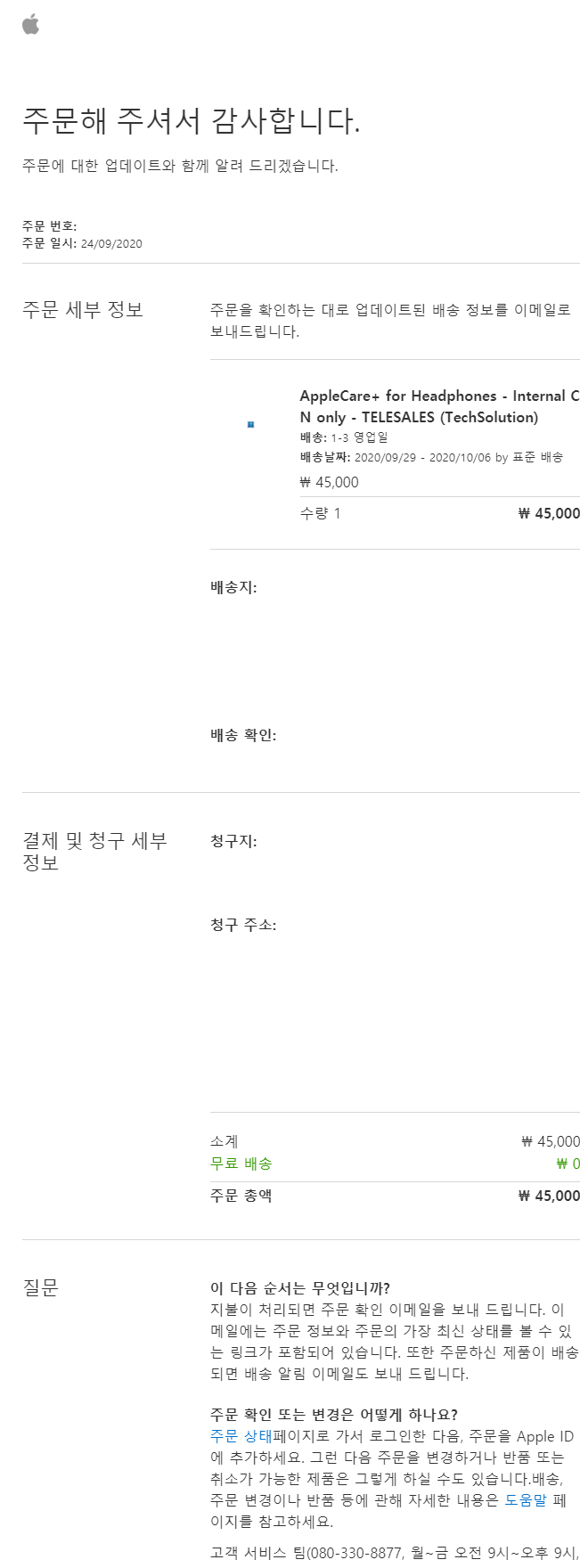
사용하던 노트북이 나사집이 부러지면서 힌지가 제 역할을 하지 못하게 되어 교체를 하게 되었다.
원래 G마켓에서 호러쇼를 하여 20% 할인쿠폰과 AMD 8%할인쿠폰을 사용하여 약 59만원 정도에 레노버 Slim3 14are - R7모델을 구입하려 하였다. 그 이유는 라이젠 7을 단 노트북중 가볍고 가장 싼 가격이였다.(전에 쓰던 노트북이 2kg대여서 이번 구매에서는 무게를 가장 중점으로 두었다)
하지만 다음날 판매자는 가격을 13만원을 더 올려버렸고, 현금으로 다른 업체에서 63만원 가량에 구입하려 하였지만 재고가 없다고 하여 TFX 4700H를 구매하게 되었다.
Slim3 14are-R7 대비
SSD (250 ->500)용량
RAM(8GB(4gb온보드) -> 16GB(듀얼채널))
모니터(ntsc45% -> NTSC:72%)
무게(1.4kg->1.1kg)
CPU(8C8T->8C16T)
배터리(35Wh->47Wh)
로 가격대비 이득이 많은것같아 TFX4700H를 선택하였다.
주문은 목요일에 하였고 배송은 월요일에 받았다.
박스는 다음과 같이 꼼꼼히 포장되어 왔다.
구성품이다. 본체 충전기 보증서이다.
본품을 열면 모니터 키보드 자국 방지를 위한 작은 부직포 하나와 상단모니터 보호를 위한 비닐, 보증서가 나온다.
저 터치패드는 불이 들어오면 꺼진상태이고 불이 꺼지면 터치패드가 켜진상태이다.
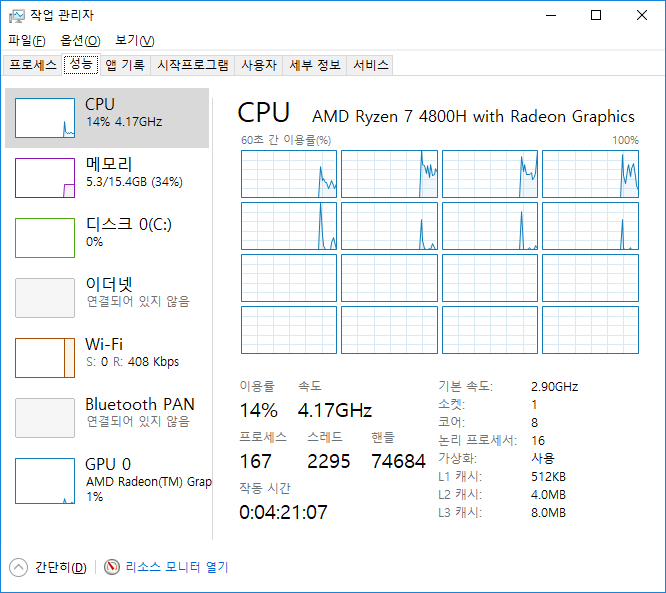
16쓰레드의 웅장함이 느껴진다 ㄷㄷ
문제점으로는 별 문제가 되진 않을 수 있는데. 키보드 중앙이 볼록하게 올라와있다. 그리고 HDMI 사용시 충전기를 꼽으면 화면이 깜빡거리는 문제점이 있다.
이 부분을 제외한다면 나머지부분은 크게 문제되지 않는것 같다.
이 성능과 가격대와 무게를 생각하면 이만한 노트북이 없는것 같다.
추가 10일간 사용해본 후기를 남기겠다.
단점)
1. 충전기가 부피가 크고 무겁다. 하지만 PD충전기를 구입한다면 휴대성이 더 좋을 것이다.
2. 키보드 백라이트는 없다고 생각하는 것이 편하다
3. 스피커의 품질이 썩 좋진 않다. 하지만 못들을 수준까진 아니다. 4. 배터리 보호 프로그램이 없다. 보통 60%나 80%까지만 충전되게 설정해주는 프로그램들이 있는데 이 모델에는 없고 바이오스 상에 설정하는 것도 없다. 따라서 항상 전원을 꼽고 사용한다면 주의하길 바란다.
장점)
1. 가벼운데 8코어 16쓰레드이다.
2. 1.1kg무게로 오버워치 정도는 무난하게 돌린다.
3. 생각보다 배터리가 오래간다. 카페에서 5-6시간 정도 있었는데 굳이 충전을 하지않아도 사용가능했다. (주로 검색과 강의를 들었다.)
4. 플라스틱 바디가 아니라 금속 바디이다.
추가)
-상판이 너무 밋밋하다.
-위에서 말한 배터리 타임은 밝기를 50%정도로 낮춘 상태다. -전원 충전 시 HDMI 사용할 경우 화면 꺼짐이 랜덤이라, 모니터를 연결하여 사용시 충전이 다되면 전원을 빼고 사용하는 것이 좋다. ( c-type 포트로 충전시 위와같은 문제는 해결된다. 따라서 시중 65w 충전기 아무거나 하나 사서 사용한다면 문제없을 듯 하다.) -뜨거울때 팬 속도를 최대로 하면 금방 시원해진다.
-8C16T라 멀티코어 사용 시 빠르다.
-오버워치 플레이시 간혹 한타때 프레임이 50정도로 내려갔다 올라온다.
-USB type C 포트는 모니터 출력을 지원하지 않는다고 들었다.
-Caps Lock 키와 터치패드에 불이 들어와 켜져있는지 표시가 되어 편하다.
-배터리 충전 시간이 빠른것같다. 한시간 정도만 충전하면 3-4시간은 사용가능(밝기 낮추었을때)