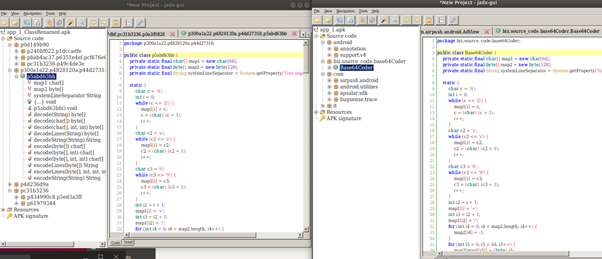
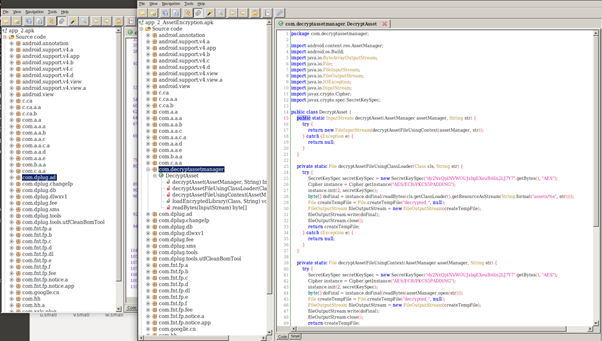
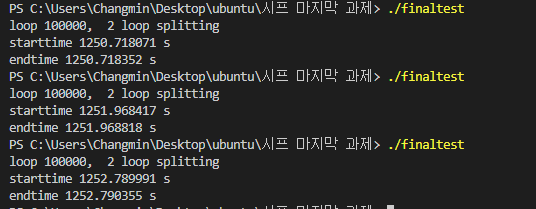
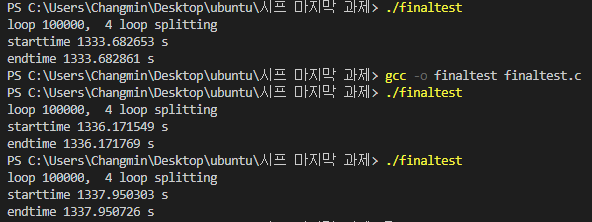
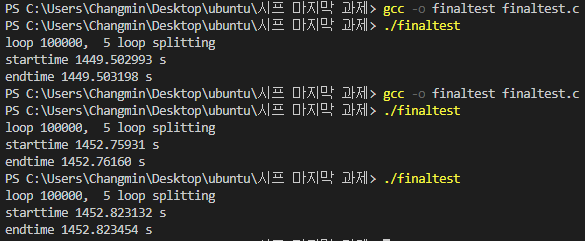
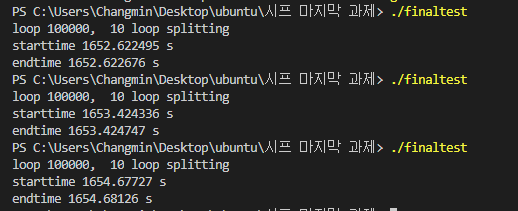
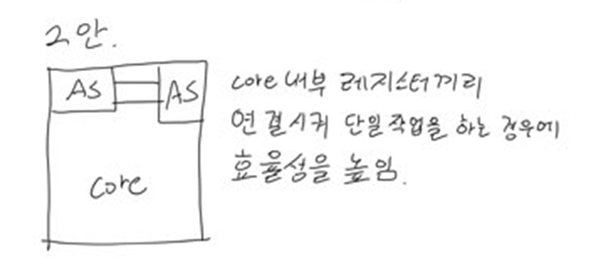
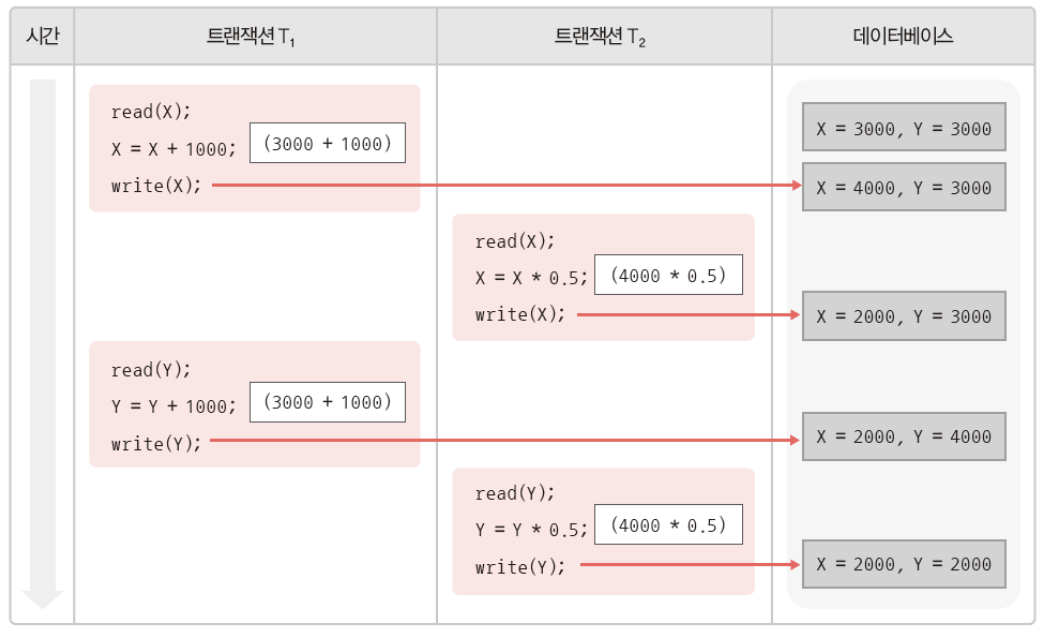
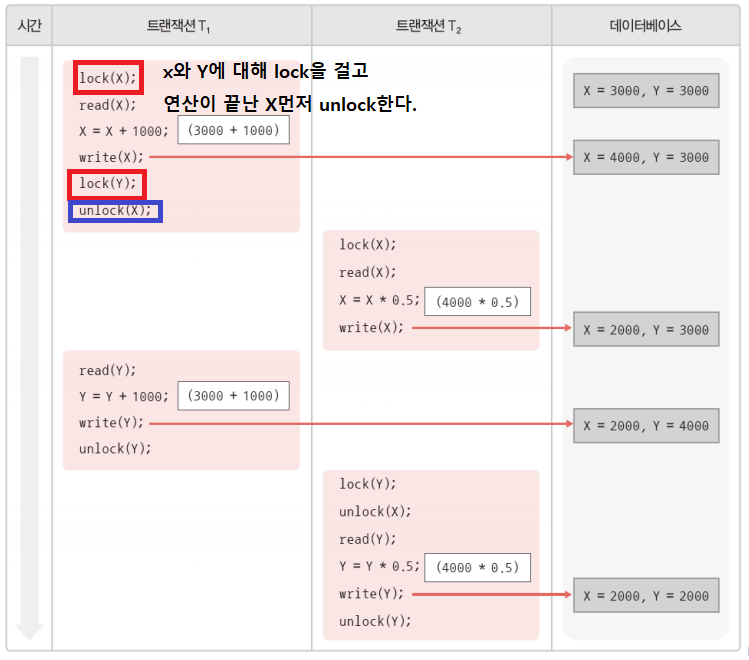
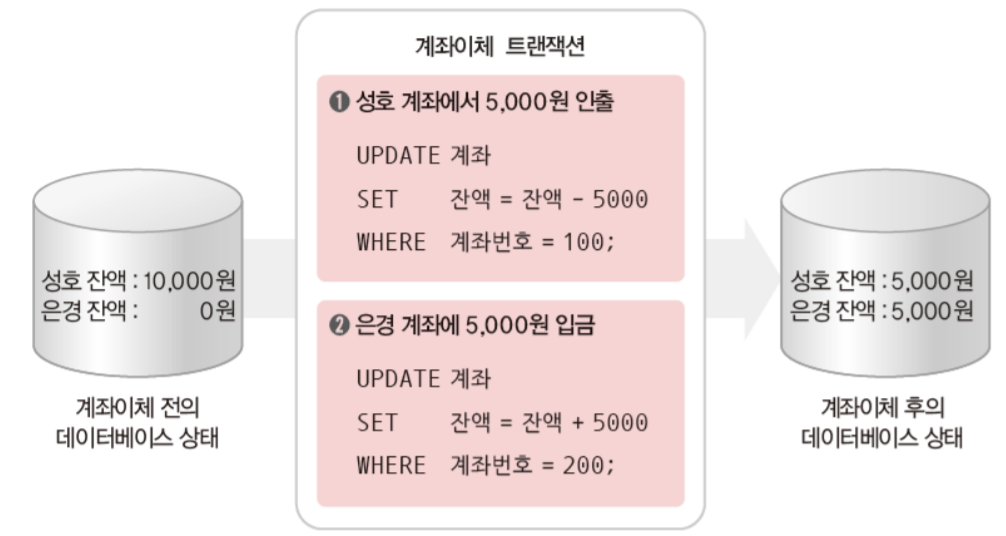
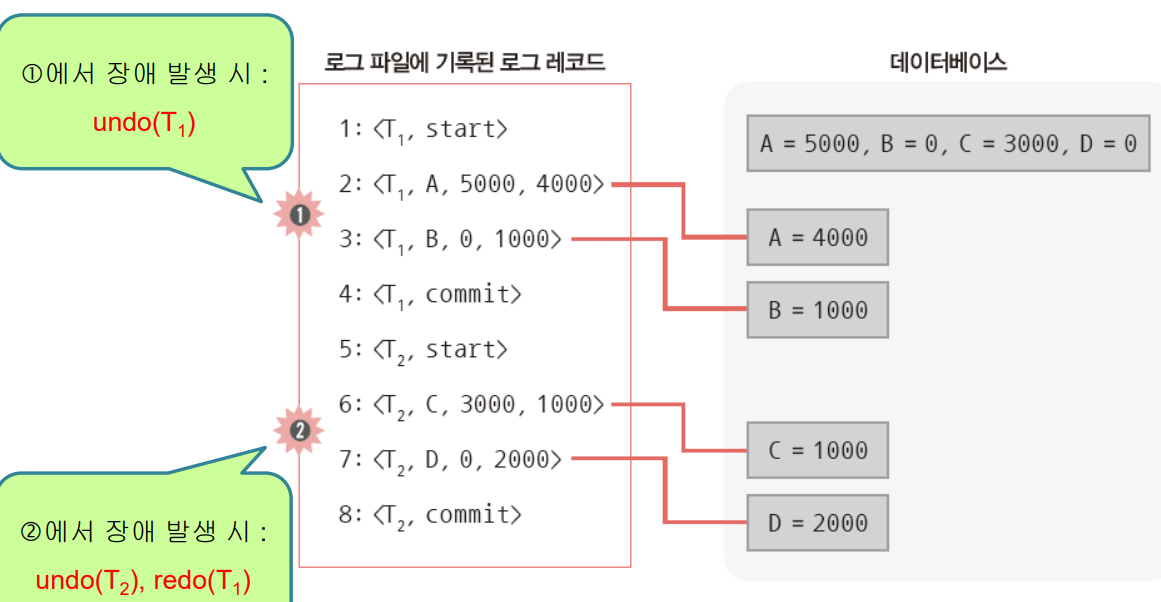
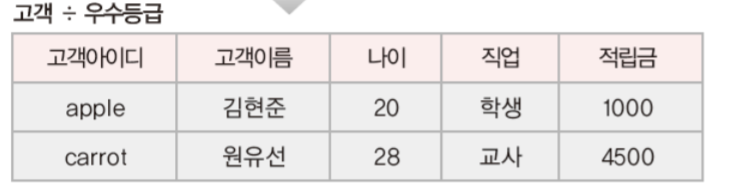
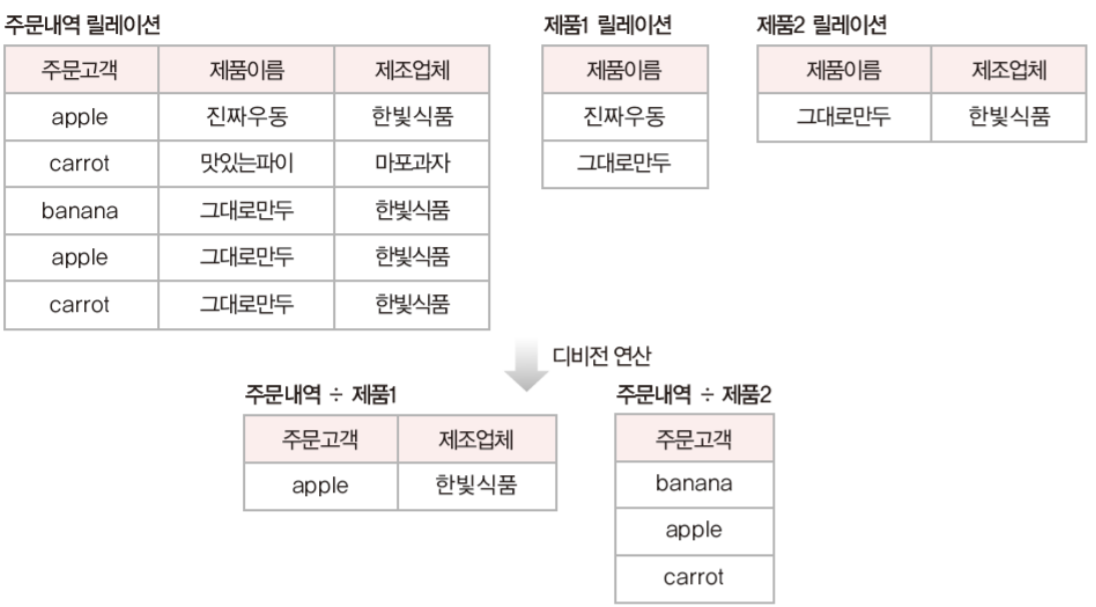
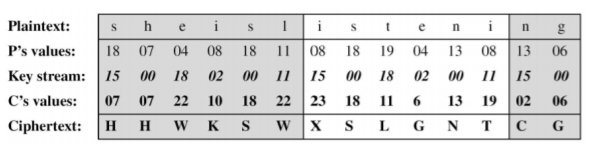
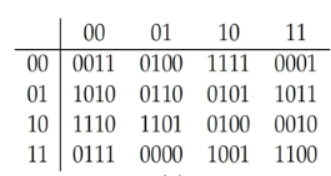
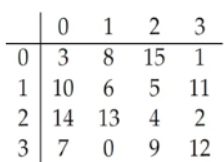
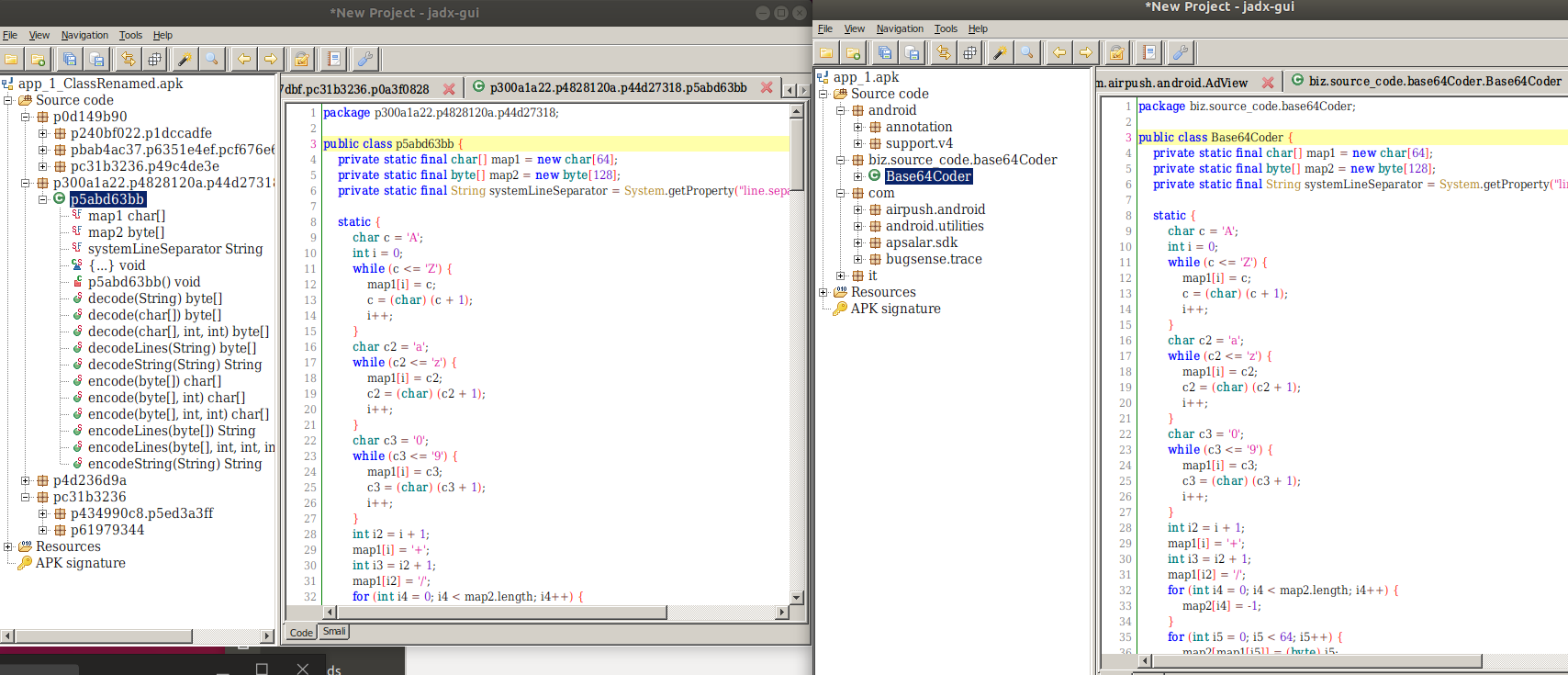
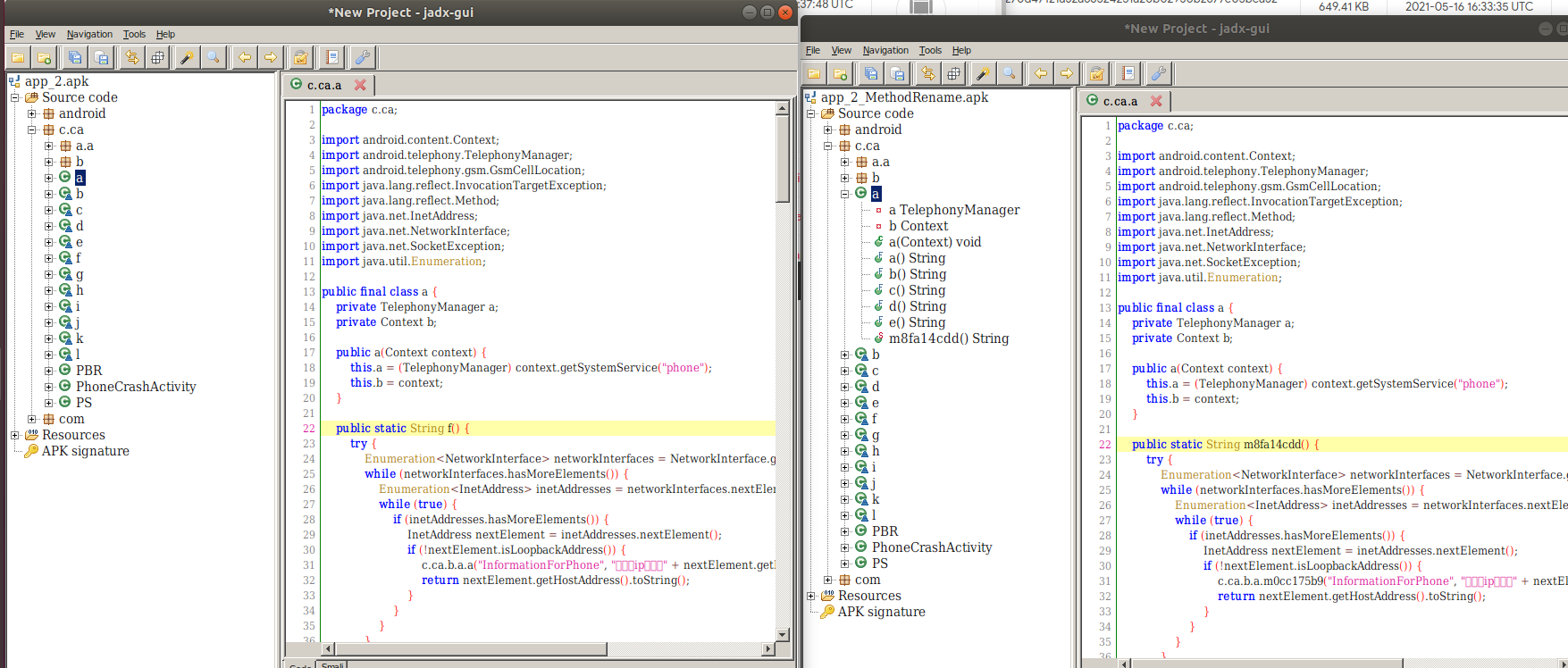
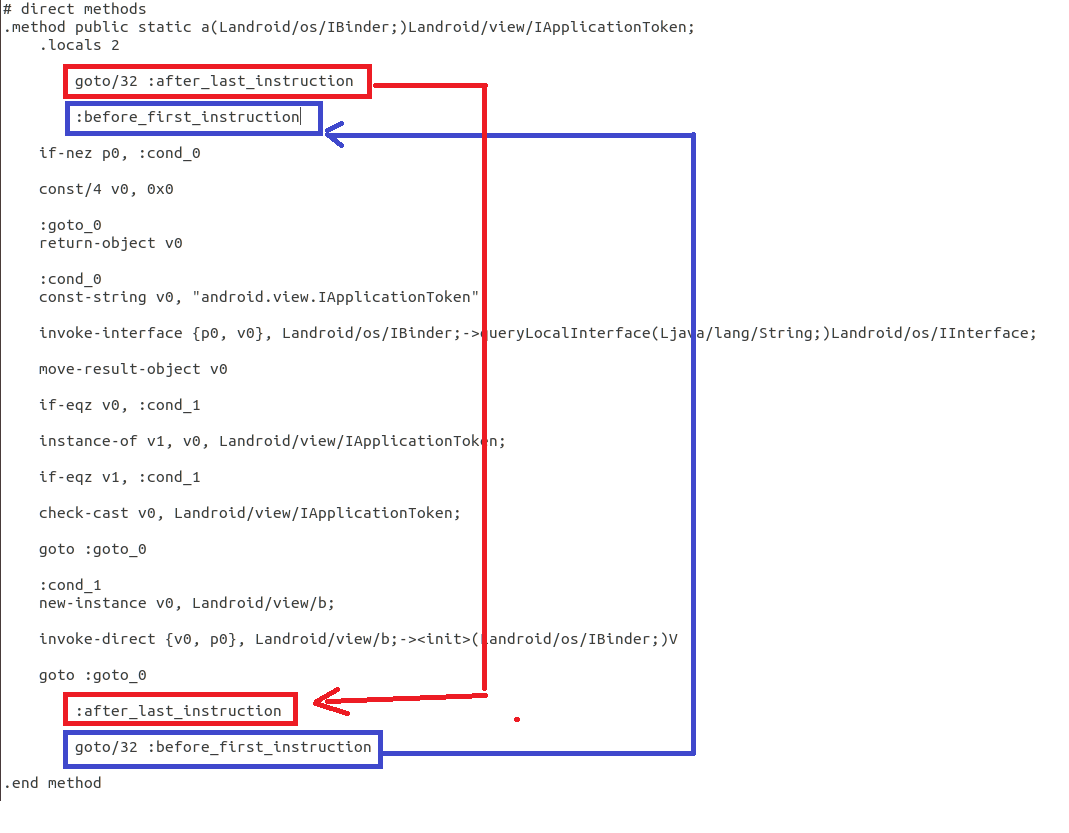
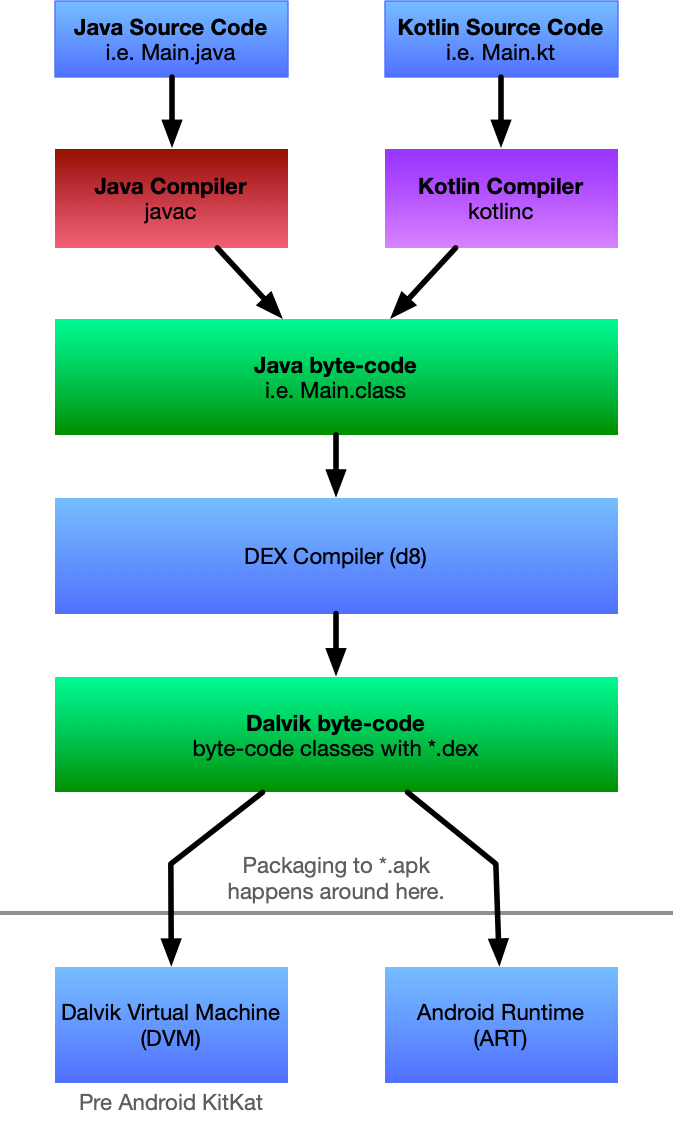
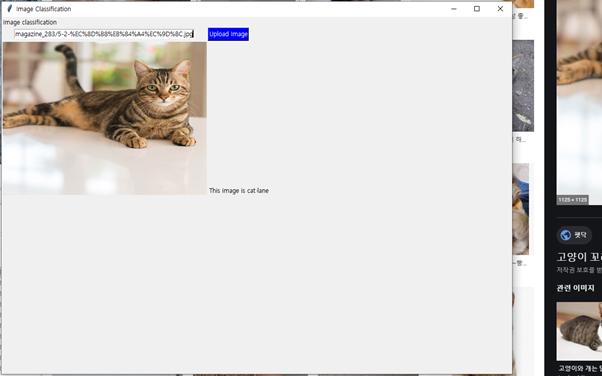
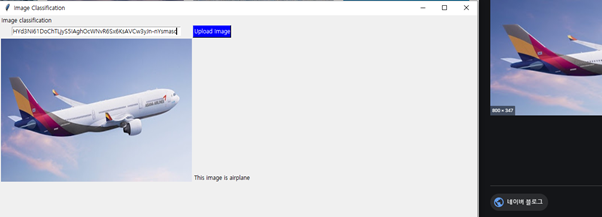
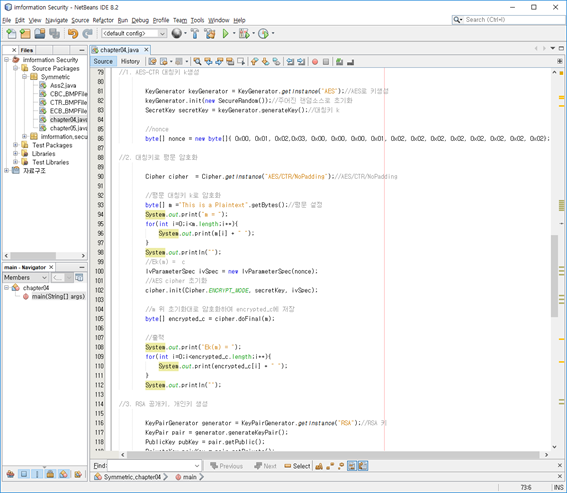
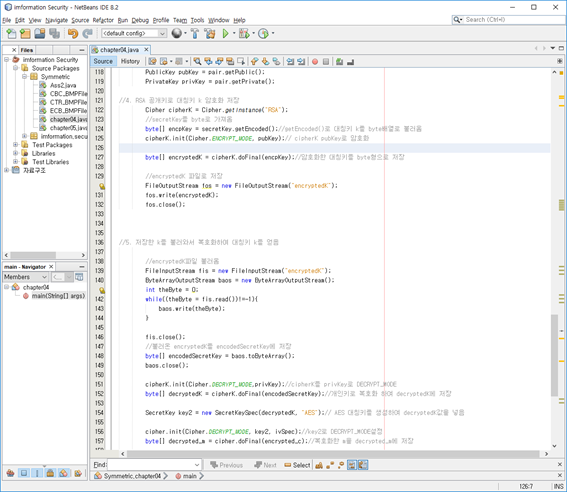
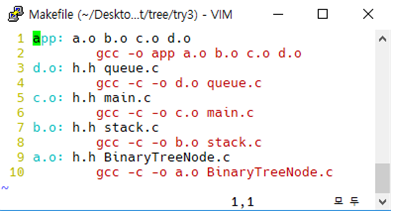
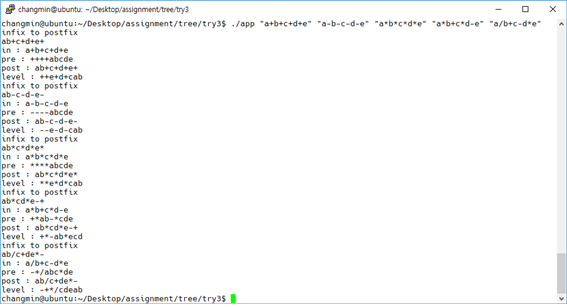
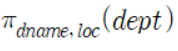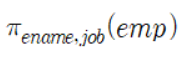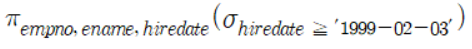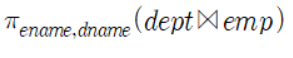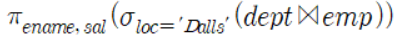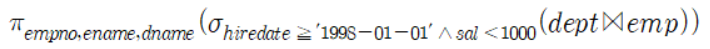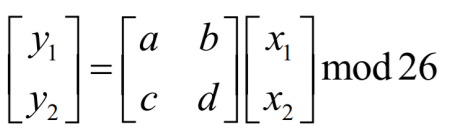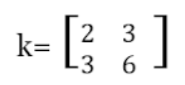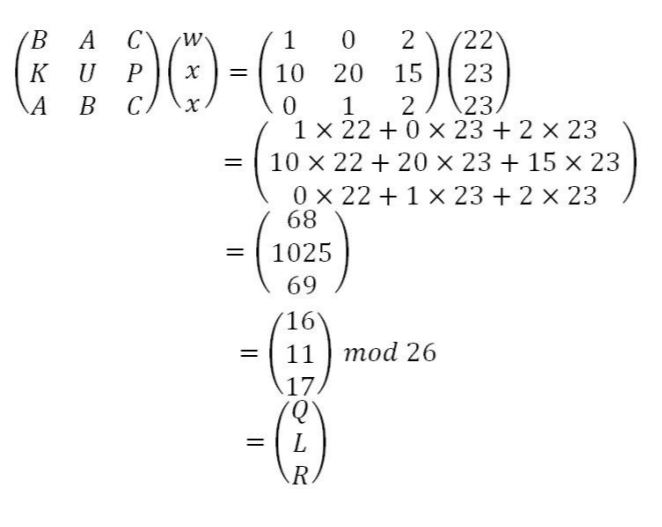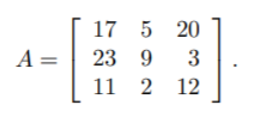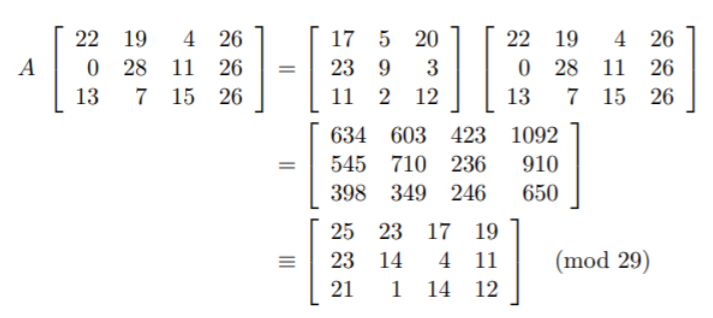class renaming은 class의 이름를 "Base64Coder"처럼 식별할 수 있는 문자대신, "pabd63bb"와 같이 무슨 의미인지 알 수 없게 바꾸어 준다. 따라서 역공학으로 해당 파일을 보더라도 무슨 역할을 하는 지 알아차리기 힘들어 역공학을 방해한다. [1]
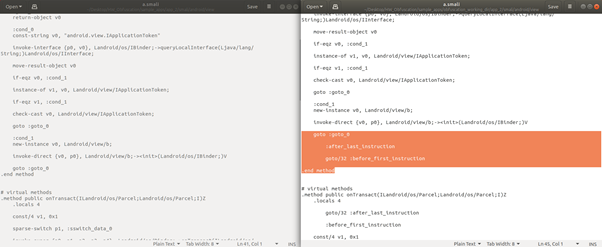
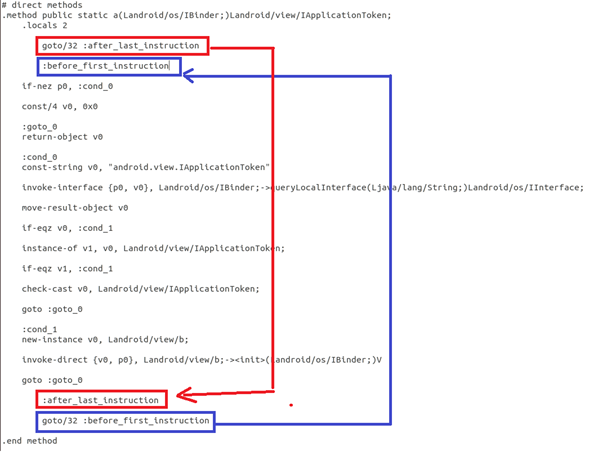
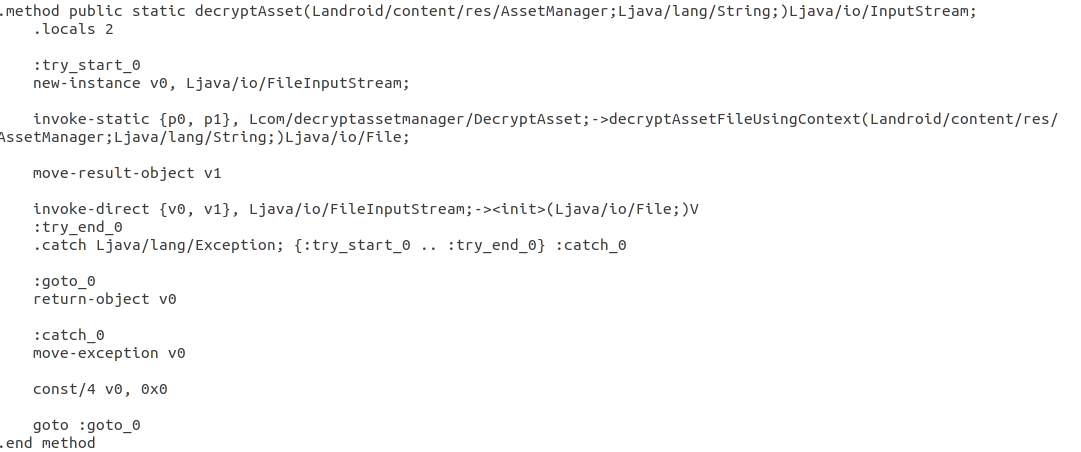
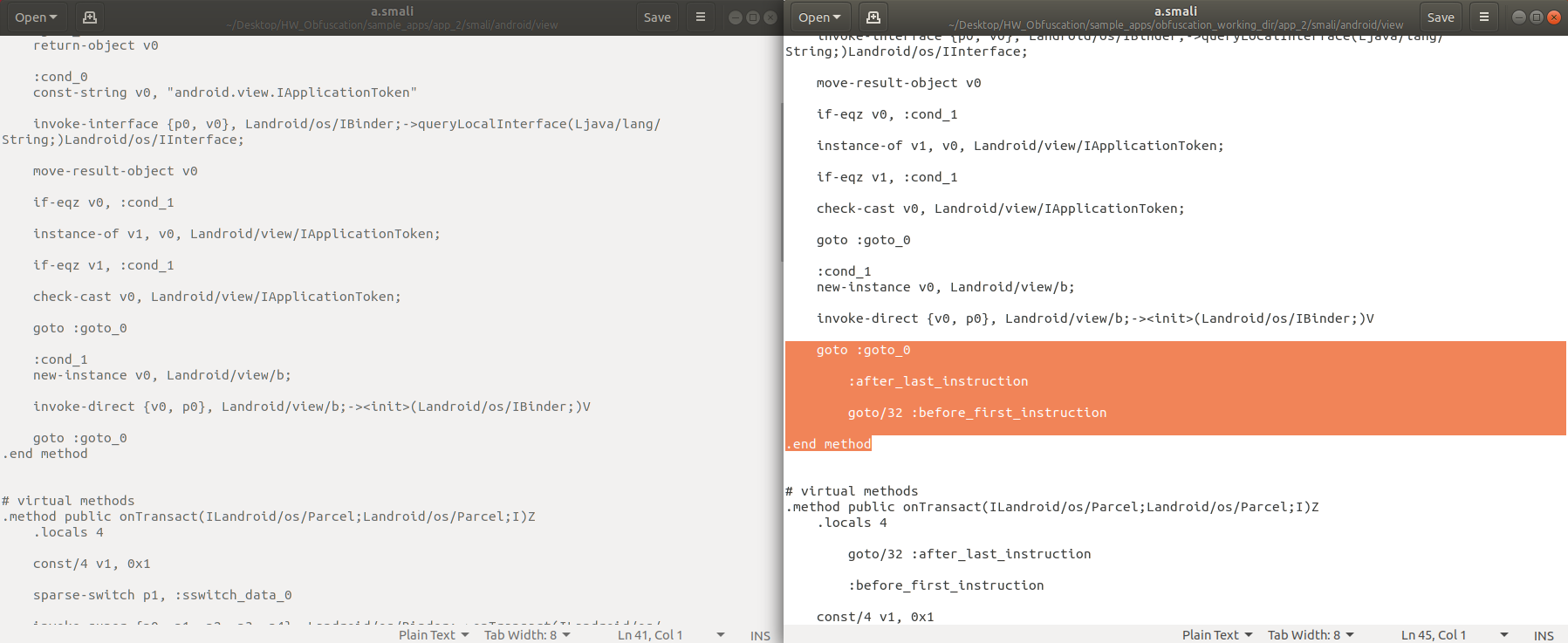
처음에 메소드의 끝을 가리키는 goto가 있고, 메소드 끝에 메소드의 처음을 가리키는 goto가 추가되어 bytecode 흐름이 달라졌다.
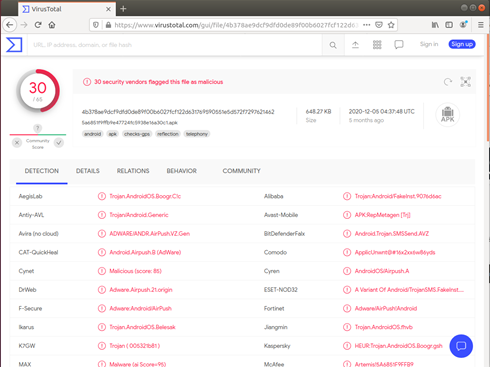
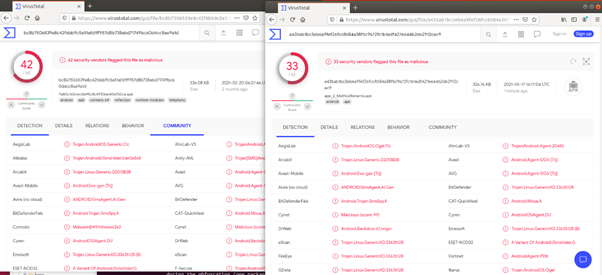
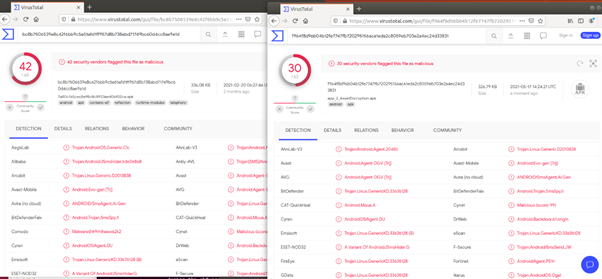
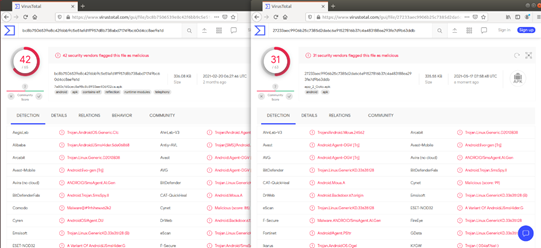
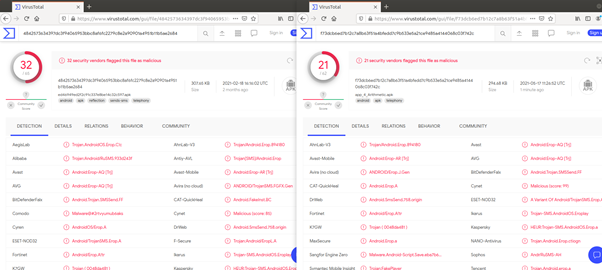
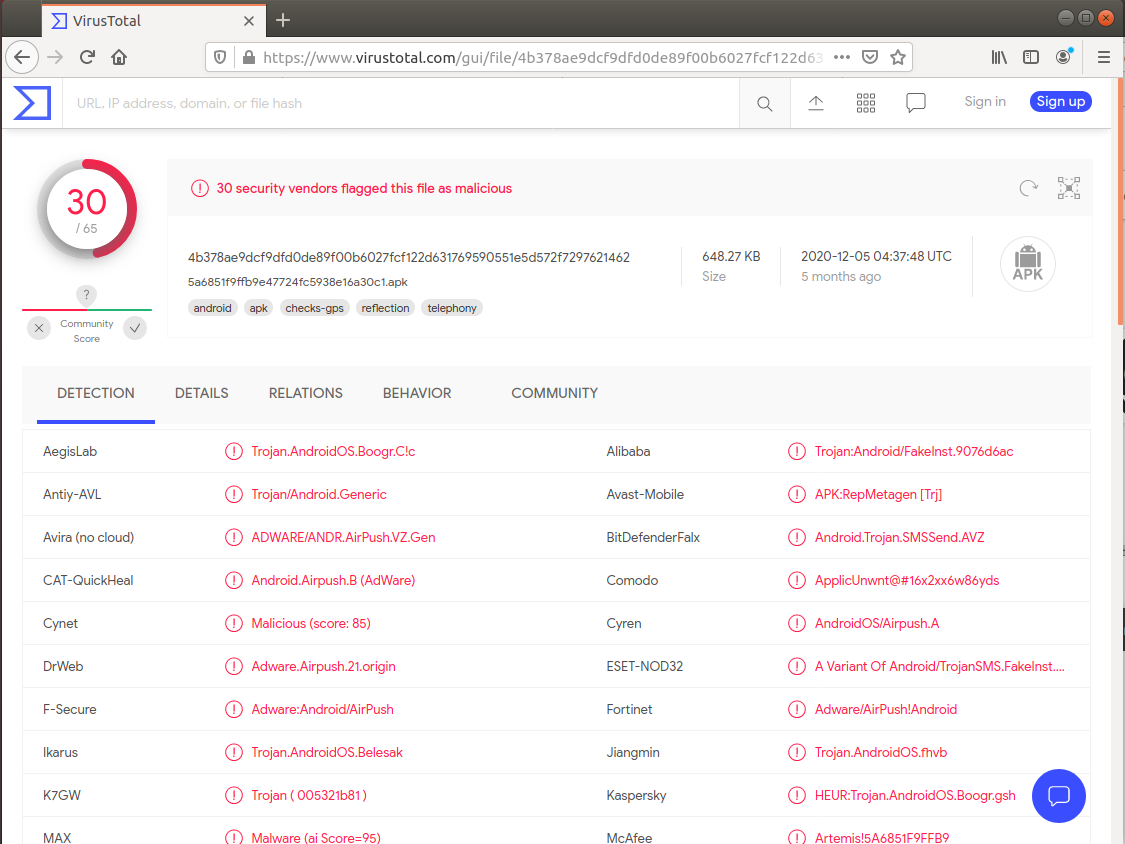
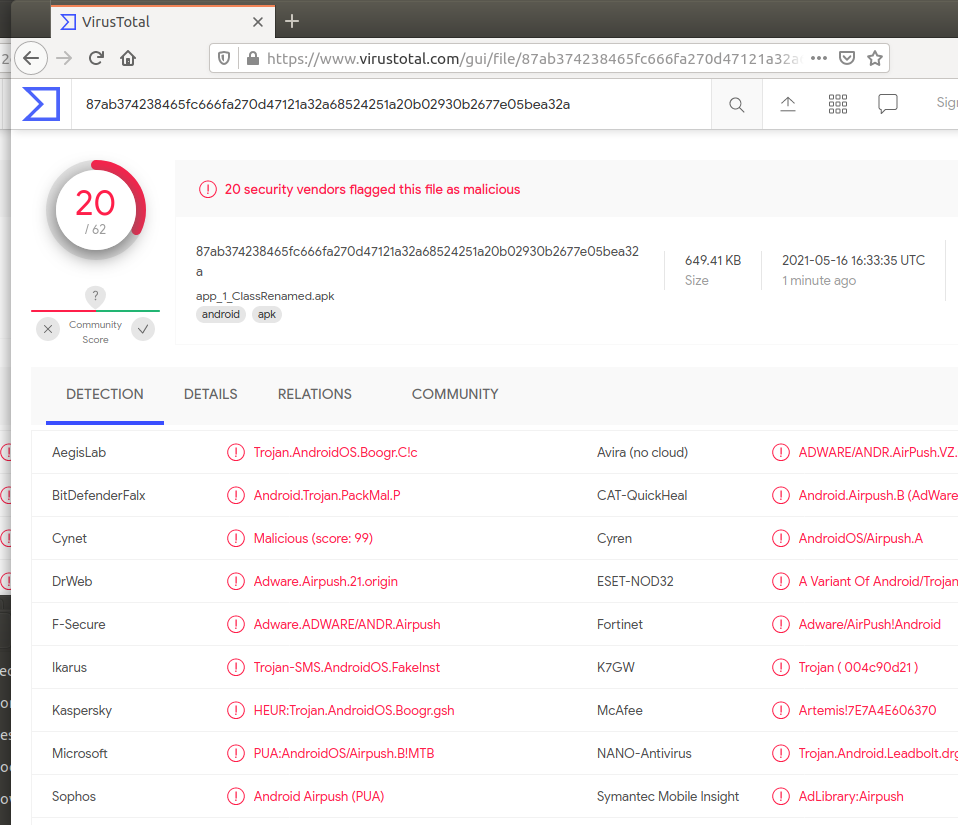
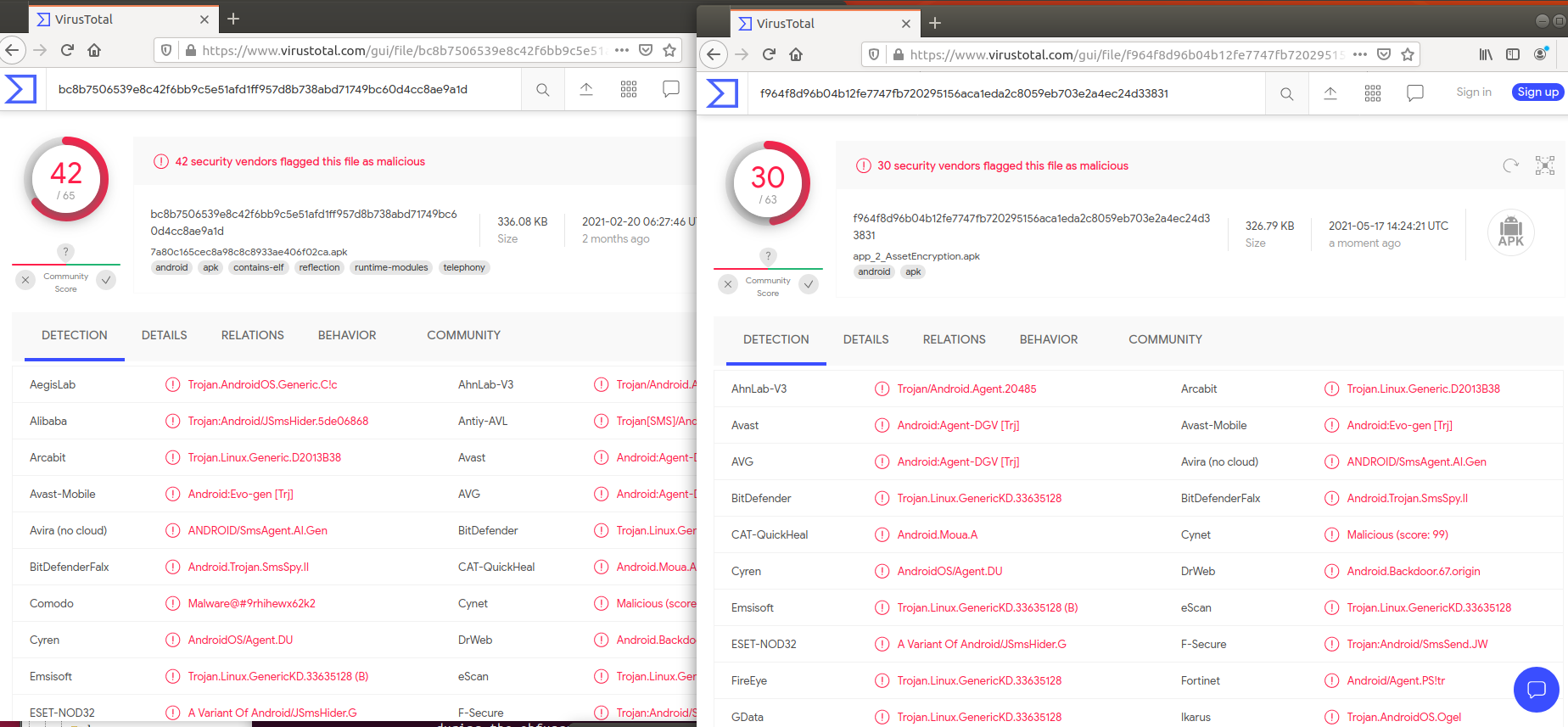
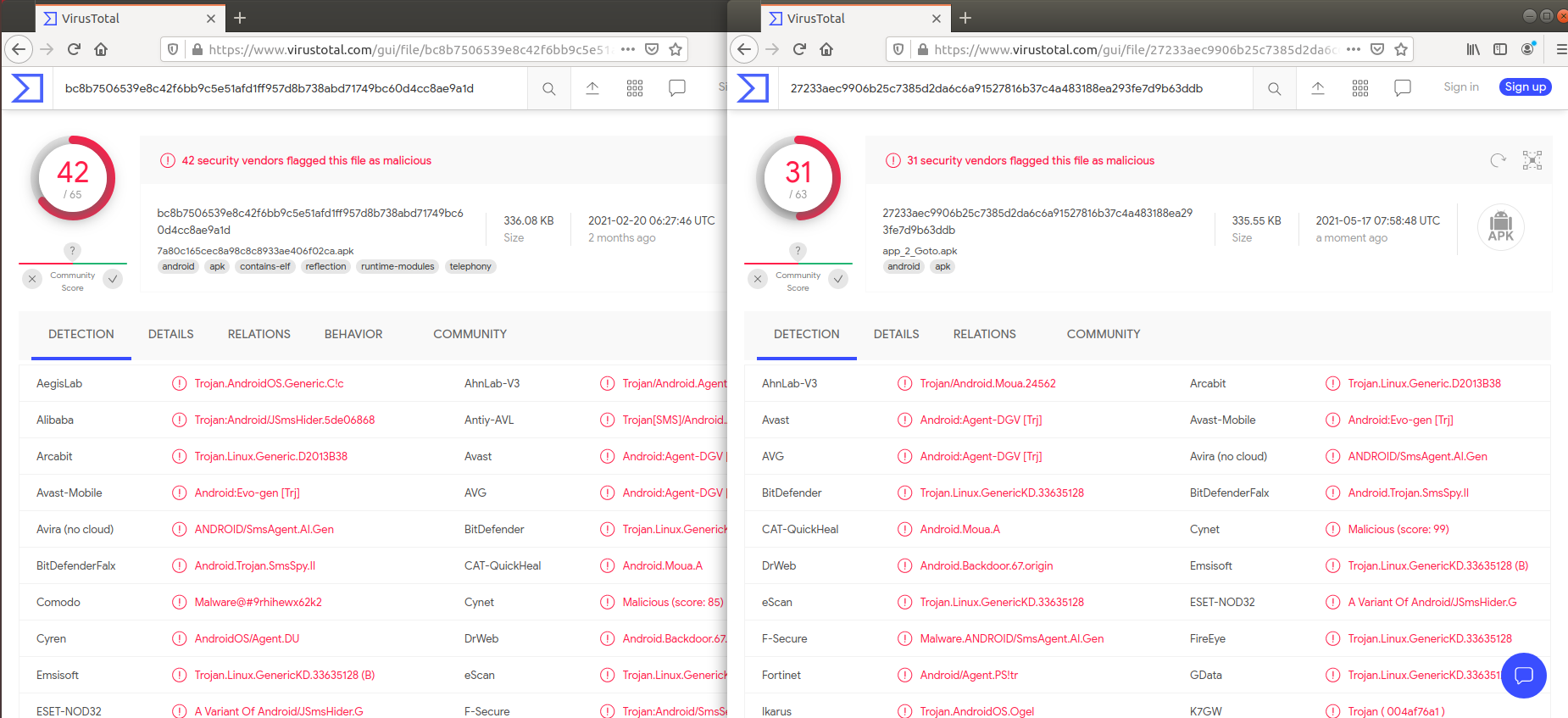
백신탐지 비교시
(왼쪽 : 기존앱, 오른쪽 : Goto옵션 적용)
Goto 옵션을 적용한 경우에 백신 탐지가 덜 되는 것을 알 수 있다.
3.2. Reorder
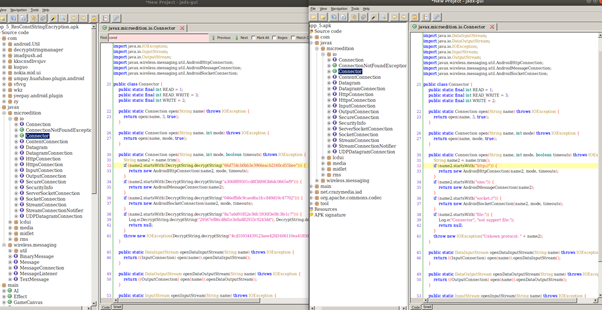
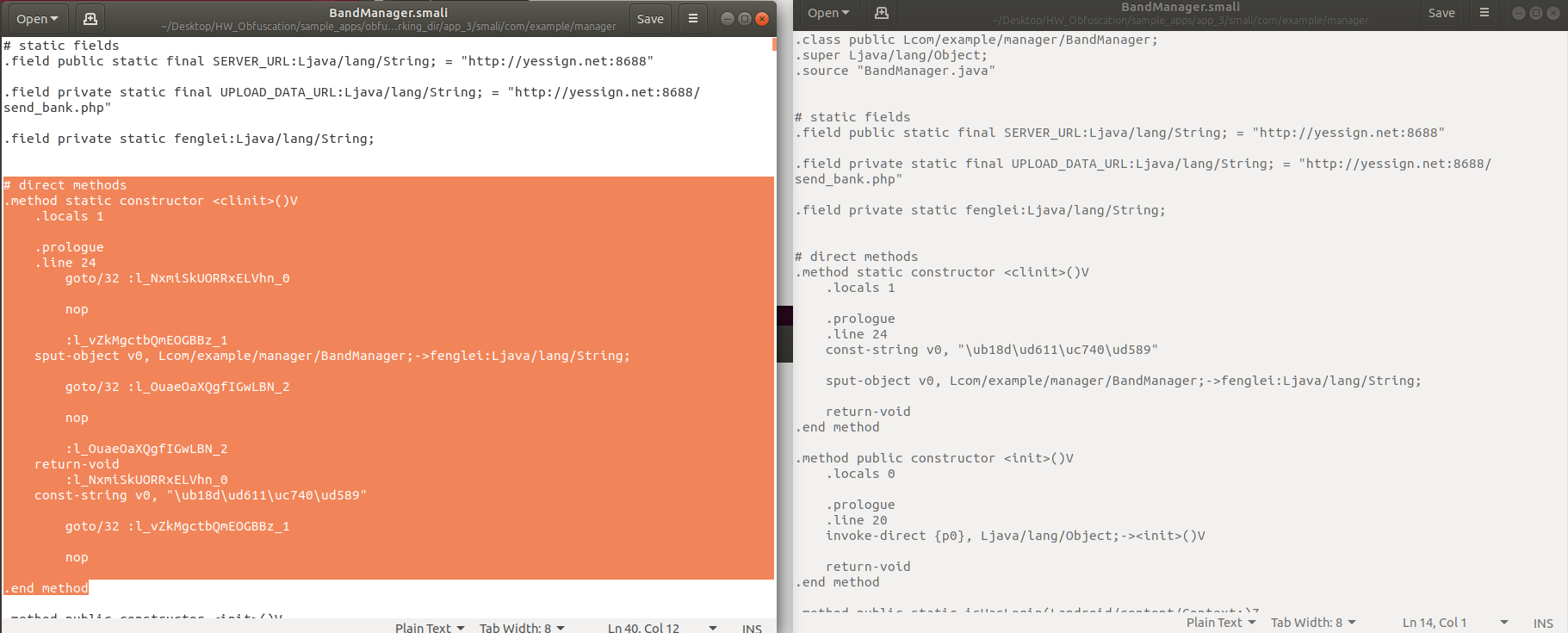
Reorder는 역공학하여 분석하기 어렵도록, 메소드의 명령어 흐름을 복잡하게 한다. 왼쪽의 그림이 Reorder된 app_3의 BandManager.smali이다. [2] 오른쪽의 기존과 method와 다르게 추가된 내용도 생기고 흐름도 goto문이 생기는 등 복잡하게 바뀐 것을 알 수 있다.
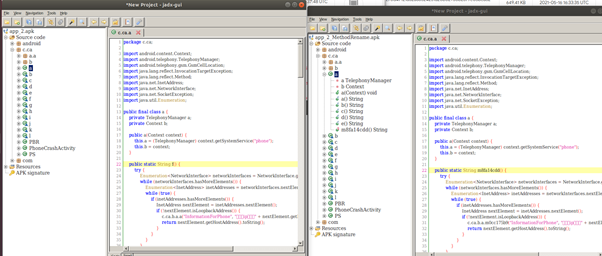
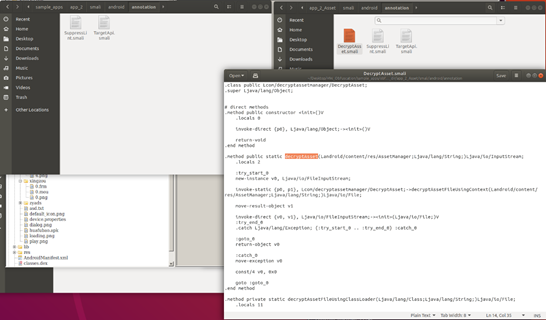
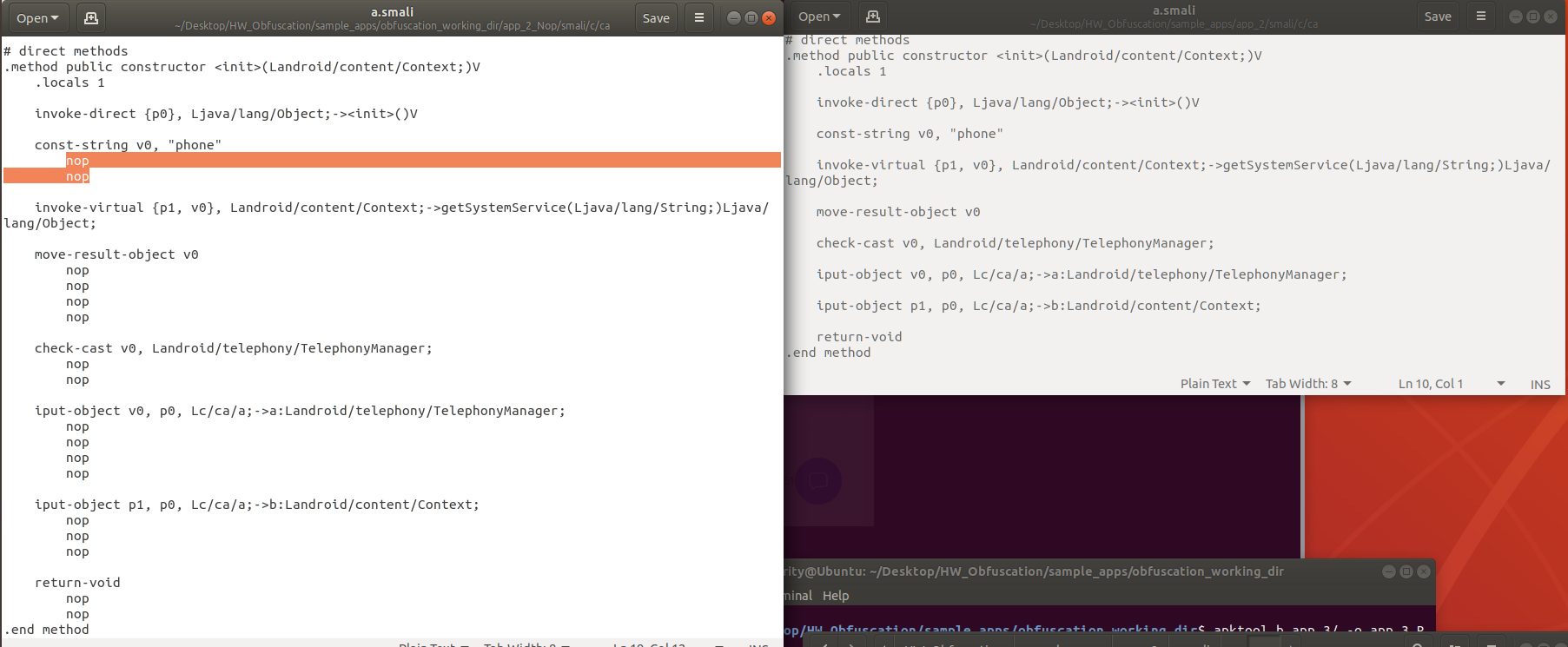
왼쪽의 Nop 옵션이 적용된 app_2/smali/c/ca/a.smali 파일을 보면 오른쪽의 기존 파일과 다르게 nop 명령어들이 추가된 것을 알 수 있다.
[그림] "smali/c/ca/a.smali"비교
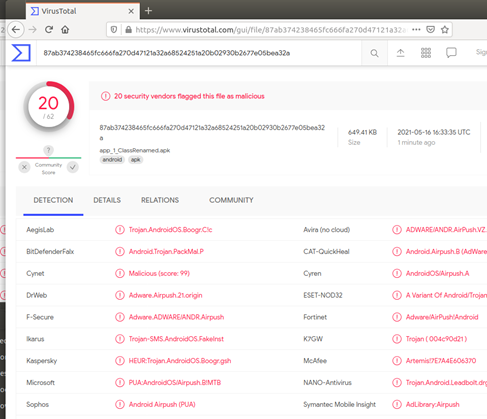
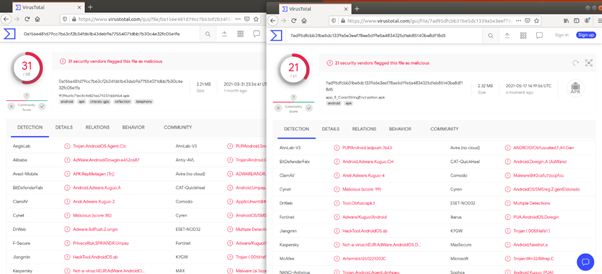
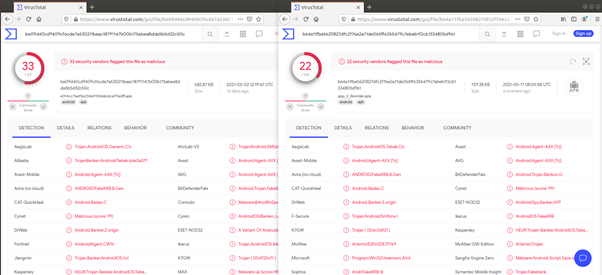
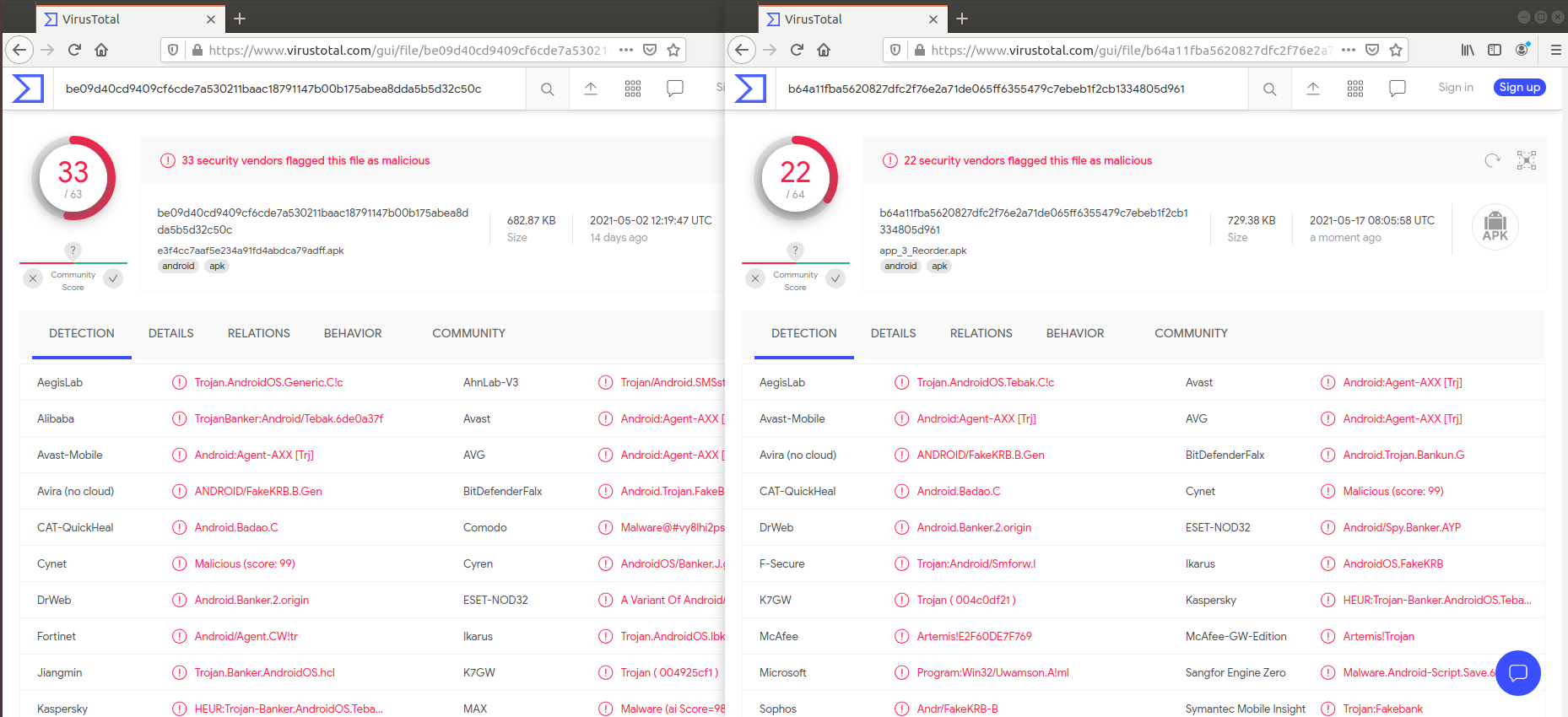
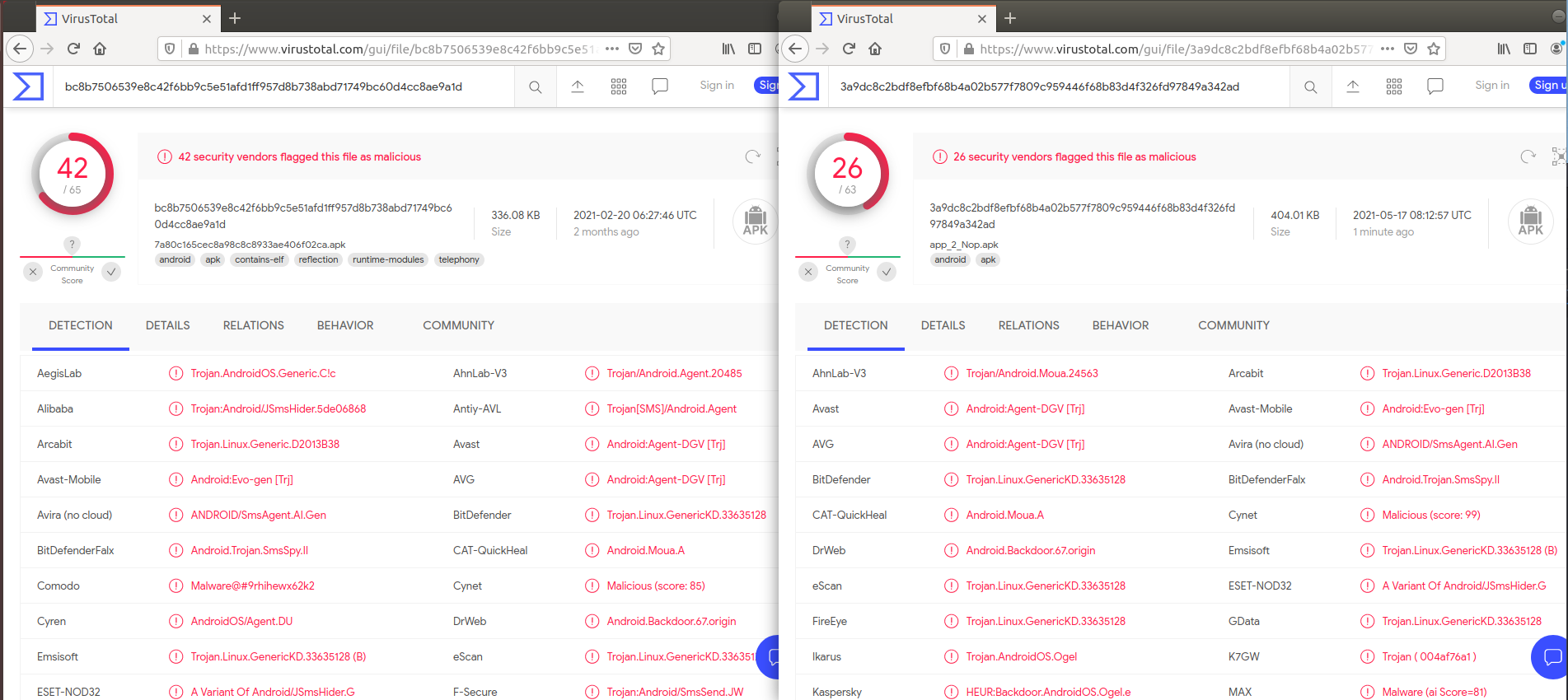
백신탐지 비교 시
(왼쪽 : 기존앱, 오른쪽 : nop 옵션 적용)
nop 옵션을 적용한 경우에 백신 탐지가 덜 되는 것을 알 수 있다.
3.4.ArithmeticBranch
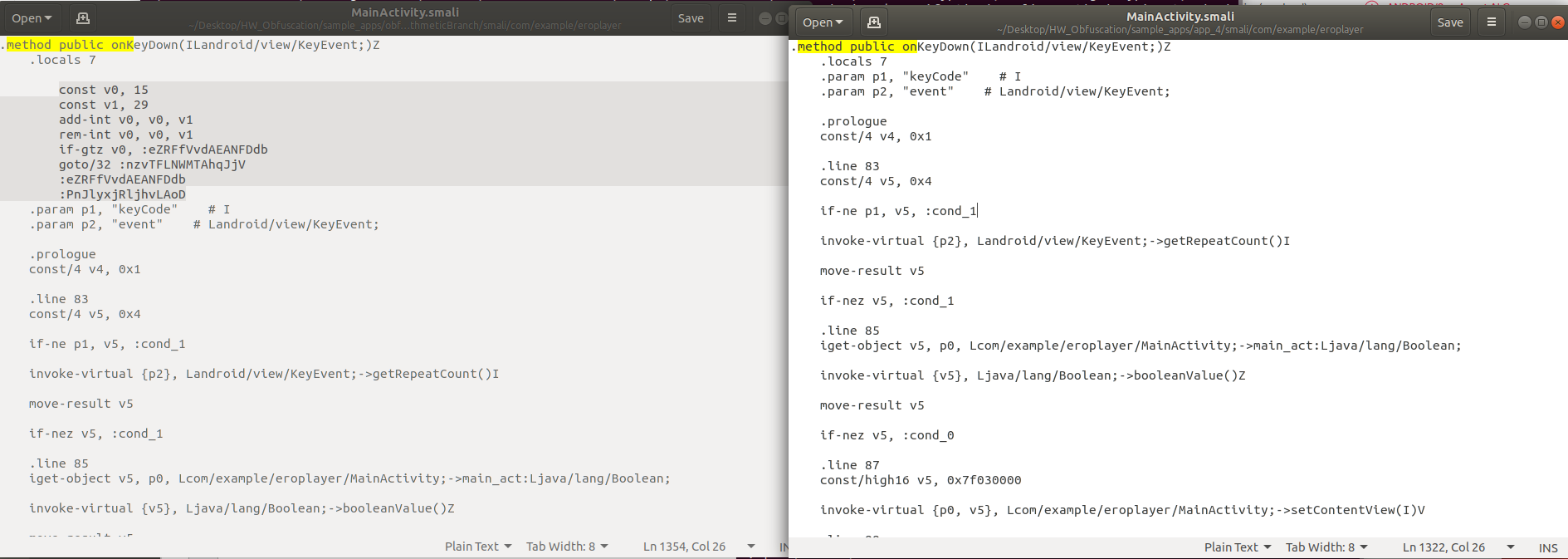
ArithmetiBranch 옵션은 의미 없는 코드를 삽입하여 명령어 흐름을 복잡하게 만들다. 따라서 역공학시 분석을 하기 어렵게 한다. [2] 왼쪽의 ArithmeticBranch 옵션이 적용된 app_4/smali/com/example/eroplayer/MainActivity을 보면 오른쪽의 기존 파일과 다르게 junk code가 삽입된 것을 알 수 있다.
[그림] “smali/com/example/eroplayer/MainActivity.smali" 비교
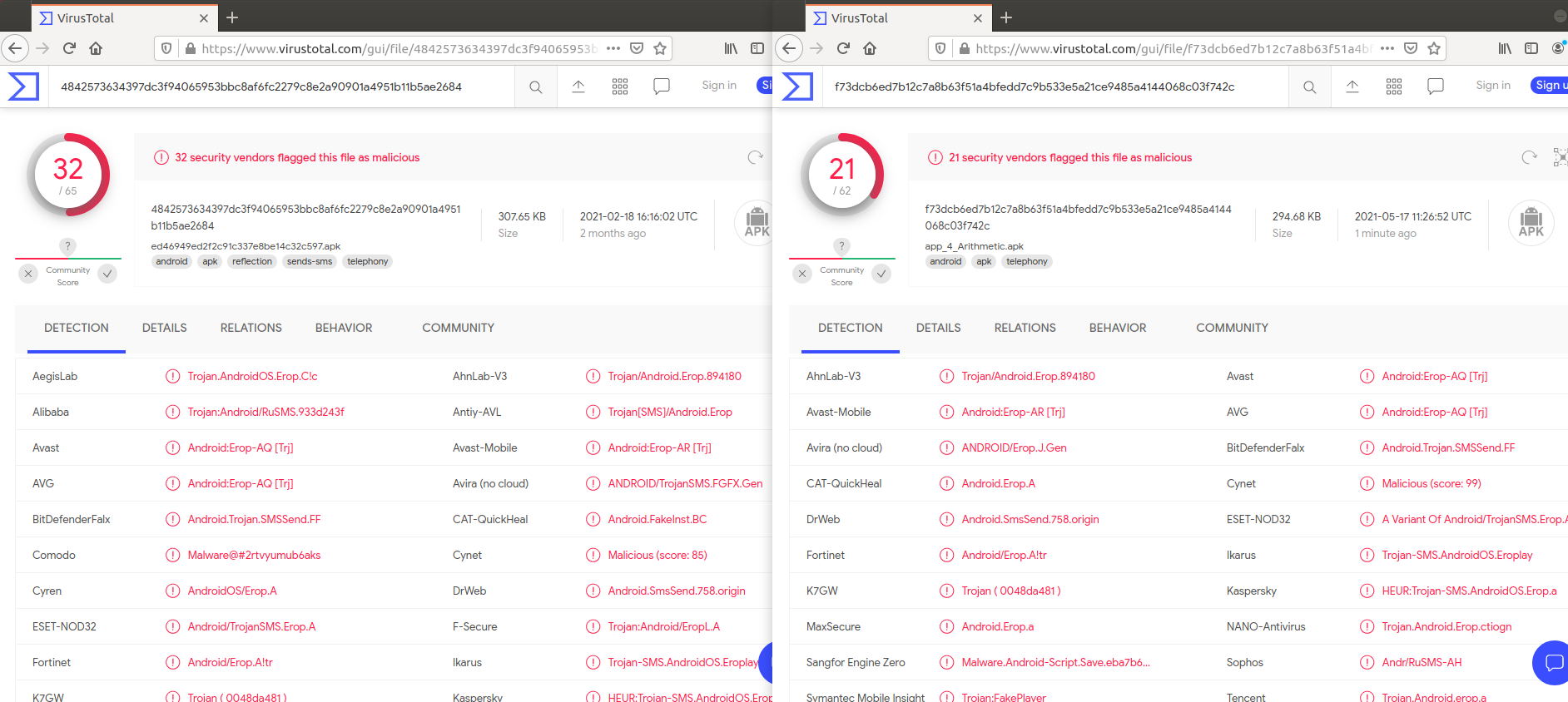
백신 탐지 비교 시
ArithmetiBranch 옵션을 적용한 경우에 백신 탐지가 덜 되는 것을 알 수 있다.
일반적인 개발자의 입장에선, 안드로이드 난독화는 역공학을 어렵게하여, 개발자가 만든 소스코드, 파일 등을 보호할 수 있게 해주는 좋은 수단이다.
[1] 난독화에 강인한 안드로이드 앱 버스마킹 기법 김 동 진 , 조 성 제° , 정 영 기* , 우 진 운**, 고 정 욱***, 양 수 미**** Android App Birthmarking Technique Resilient to Code Obfuscation Dongjin Kim , Seong-je Cho° , Youngki Chung* , Jinwoon Woo**, Jeonguk Ko***, Soo-mi Yang****
[2] 안드로이드 어플리케이션 역공학 보호기법 하 동 수*, 이 강 효*, 오 희 국*
[3] Android Code Protection via Obfuscation Techniques: Past, Present and Future Directions Parvez Faruki, Malaviya National Institute of Technology Jaipur, India Hossein Fereidooni, University of Padua, Italy Vijay Laxmi, Malaviya National Institute of Technology Jaipur, India Mauro Conti, University of Padua, Italy Manoj Gaur, Malaviya National Institute of Technology Jaipur, India
[4] APK에 적용된 난독화 기법 역난독화 방안 연구 및 자동화 분석 도구 구현* 이 세 영,† 박 진 형, 박 문 찬, 석 재 혁, 이 동 훈‡ 고려대학교 정보보호대학원
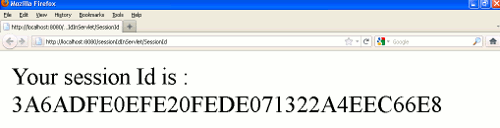
#mysql - python connection test
import pymysql #mysql과 연동하기 위해
#필요한 기본 DB 정보
host = "localhost"
user = "root"
pw = "password"
db = "my_db"
#DB에 접속
conn = pymysql.connect(host= host, user = user, password = pw, db = db)
#사용할 sql문
sql1 = "SELECT ename FROM emp WHERE empno=7521"
sql2 = "SELECT dname FROM emp, dept WHERE dept.deptno=emp.deptno and ename='scott'"
sql3 = "SELECT ename FROM emp WHERE job='salesman'"
sql4 = "SELECT dname FROM dept"
querys = [sql1, sql2, sql3, sql4]
for sql in querys:
print(sql)
# sql문 실행/데이터 받기
curs = conn.cursor() #sql 실행시 결과를 담고 있는 버퍼를 정렬
curs.execute(sql) #앞의 sql문 실행
row = curs.fetchone() #sql실행결과 모두 가져오기, fetchall 모든 행 가져옴, fetchone은 하나의 행만 가져옴
while(row):
print(row)
row = curs.fetchone()
print("==========================================================")
#db 접속 종료
curs.close()
conn.close()
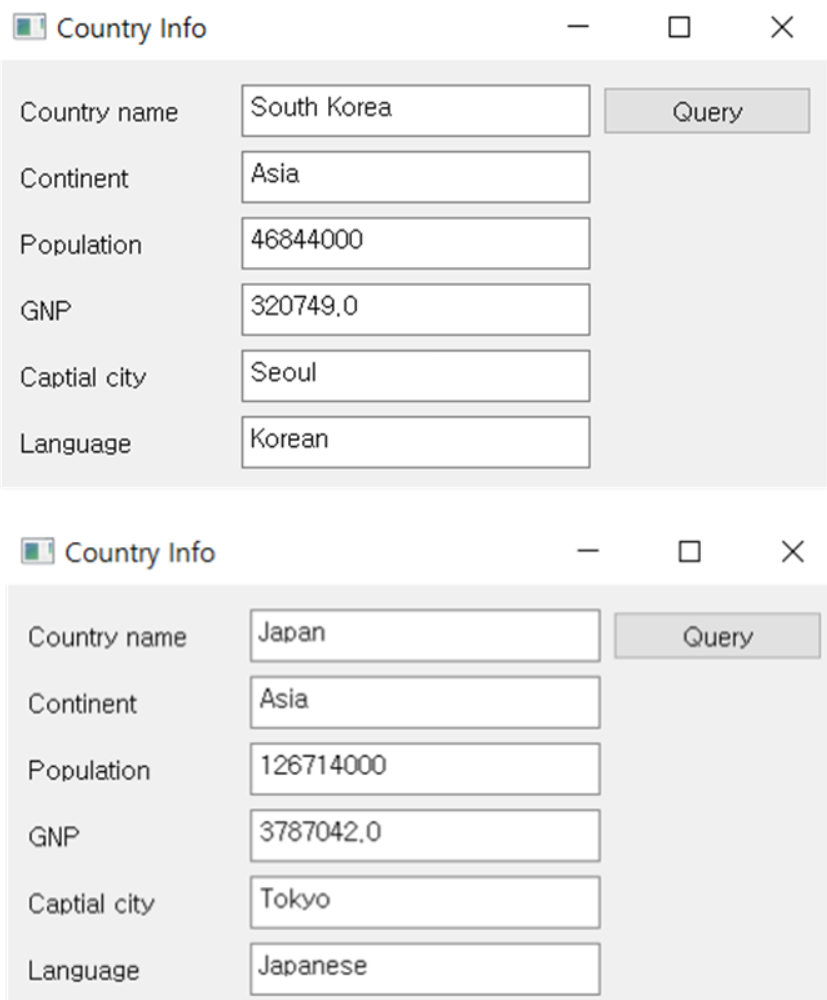
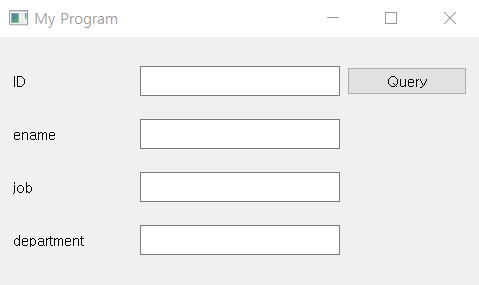
Mysql 의 world 데이터베이스와 연동하여 다음과 같이 국가명을 입력하면 해당 국가의 정보를 출력하는 윈도우 프로그램
- 매치되는 국가가 없으면 모든 항목에 공백 출력
import sys
import pymysql
from PyQt5.QtWidgets import *
def connectDB():
#필요한 db 정보
host = "localhost"
user = "root"
pw = "Changmin97"
db = "world"
#db 접속
conn = pymysql.connect(host=host, user =user, password =pw, db =db)
return(conn) #connection 리턴
def disconnectDB(conn):
conn.close()
class MyApp(QWidget):
def __init__(self):
super().__init__()
self.initUI()
# UI 디자인 함수
def initUI(self):
#QLable 문자열 출력
label1 = QLabel('Country name')
label2 = QLabel('Continent')
label3 = QLabel('Population')
label4 = QLabel('GNP')
label5 = QLabel('Captial city')
label6 = QLabel('Language')
#text_Country_name
self.text_Country_name = QTextEdit()
self.text_Country_name.setFixedWidth(200)
self.text_Country_name.setFixedHeight(30)
#버튼 생성, 버튼 클릭시 btn_1_clicked 실행
btn_1 = QPushButton('Query')
btn_1.clicked.connect(self.btn_1_clicked)
#text_Continent
self.text_Continent = QTextEdit()
self.text_Continent.setFixedWidth(200)
self.text_Continent.setFixedHeight(30)
#text_Population
self.text_Population = QTextEdit()
self.text_Population.setFixedWidth(200)
self.text_Population.setFixedHeight(30)
#text_GNP
self.text_GNP = QTextEdit()
self.text_GNP.setFixedWidth(200)
self.text_GNP.setFixedHeight(30)
#text_Captial_city
self.text_Captial_city = QTextEdit()
self.text_Captial_city.setFixedWidth(200)
self.text_Captial_city.setFixedHeight(30)
#text_Language
self.text_Language = QTextEdit()
self.text_Language.setFixedWidth(200)
self.text_Language.setFixedHeight(30)
#화면 배치, grid를 만들어 배치
gbox = QGridLayout()
gbox.addWidget(label1,0,0)
gbox.addWidget(self.text_Country_name, 0, 1)
gbox.addWidget(btn_1, 0, 2)
gbox.addWidget(label2,1,0)
gbox.addWidget(self.text_Continent, 1, 1)
gbox.addWidget(label3,2,0)
gbox.addWidget(self.text_Population, 2, 1)
gbox.addWidget(label4,3,0)
gbox.addWidget(self.text_GNP, 3, 1)
gbox.addWidget(label5,4,0)
gbox.addWidget(self.text_Captial_city, 4, 1)
gbox.addWidget(label6,5,0)
gbox.addWidget(self.text_Language, 5, 1)
self.setLayout(gbox)
self.setWindowTitle('Country Info')
self.setGeometry(300, 300, 480,250) #창뜨는 위치, 크기
self.show()
#버튼 클릭 처리
def btn_1_clicked(self):
#사용자가 입력한 값 받아서 empno 저장
Country_name = self.text_Country_name.toPlainText()
sql = "SELECT country.name, continent, country.population, gnp, city.name, language \
From country, city, countrylanguage\
where country.code = city.countrycode \
and country.code = countrylanguage.countrycode\
and country.capital=city.id\
and IsOfficial = 'T' \
and country.name ="+"'"+Country_name+"'"
#ex) ename '"+ename+"'" =>문자일 경우 따옴표 주의!
conn = connectDB()
curs = conn.cursor()
curs.execute(sql)
result = curs.fetchone() # sql 실행 결과 가져오기
if result:
self.text_Country_name.setText(result[0])
self.text_Continent.setText(result[1])
self.text_Population.setText(str(result[2]))
self.text_GNP.setText(str(result[3]))
self.text_Captial_city.setText(result[4])
self.text_Language.setText(result[5])
else:
self.text_Country_name.setText("") #매치되는 국가가 없으면 모든 항목에 공백 출력
curs.close()
disconnect(conn)
#END Class
#프로그램 실행, class를 생성하고 실행
if(__name__ == '__main__'):
app = QApplication(sys.argv)
ex = MyApp()
sys.exit(app.exec_())
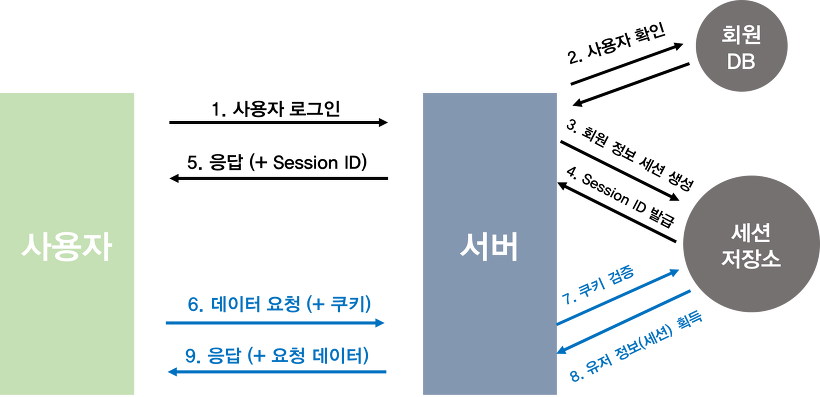
서버에 직접 접속, 원격접속 둘다 하려면 같은이름의 local, remote계정 두가지 많들어야한다.
권한은
1. 모든 DB
2. 패턴에 매칭되는 DB(이름으로 검색), 선택한 DB
에 접근할 수 있는 권한을 줄 수 있고,
select, insert, update, delete, execute, show view, create, alert, index, drop..... 와 같은 권한을 줄 수 있다
Mysql workbench는 DB단위로 권한을 부여하고 회수한다. => 세부적으로 되지 않는다.
따라서 sql 명령문 (grant, revoke)를 이용하여 테이블 단위로 권한을 부여하고 회수할 수 있다.
GRANT select ON my_db.emp TO user_1@localhost;
GRANT select, insert, update ON my_db.dept TO user_1@localhost;
root 사용자일 경우 sql문을 사용하여 사용자를 생성하고 권한부여, 회수가 가능하다.
localhost 사용자의 경우'
create user user_2@localhost identifited by '4321';
원격접속 사용자의 경우
create user 'user_2'@'%' identified by '4321';
생성된 사용자 확인
SELECT * from mysql.user;
mysql => system 카탈로그 정보가 있는 데이터 베이스
user => user테이블에 사용자 정보가 저장
권한의 부여
my_db에 대한 모든 권한 부여
grant all privileges on my_db.* to user_2@localhost;
일부 권한 부여
grant select, insert on my_db.* to user_1@localhost;
테이블에 대한 모든 권한 부여
grant all privilleges on my_db.emp to user_1@localhost;
테이블에 대한 일부 권한 부여
grant select, insert on my_db.emp to user_1@localhost;
with grant option
자신의 권한을 다른 user에게 부여할 수 있게 된다.
grant all privileges on my_db.* to user_2@localhost with grant option;
user_2로 로그인하여 다른 유저에거 자신의 권한을 grant 할 수 있다.
부여된 권한을 확인하려면
flush privileges; //변경된 내용을 메모리에 반영(권한 적용)
show grant for user_1@localhost;
권한 회수 => revoke
revoke delete on my_db.emp from user_2@localhost;
사용자 삭제
drop user user_2@localhost;
사용자 관리 - role
ex) 영업업무를 하는 user1, user2, user3이 있고 필요한 권한은 select, update일 경우
create role sales_role; //역할 생성
grant select, update on my_db.emp to sales_role; //역할에 권한 부여
grant sales_role to user1@localhost;
grant sales_role to user2@localhost;
grant sales_role to user3@localhost;
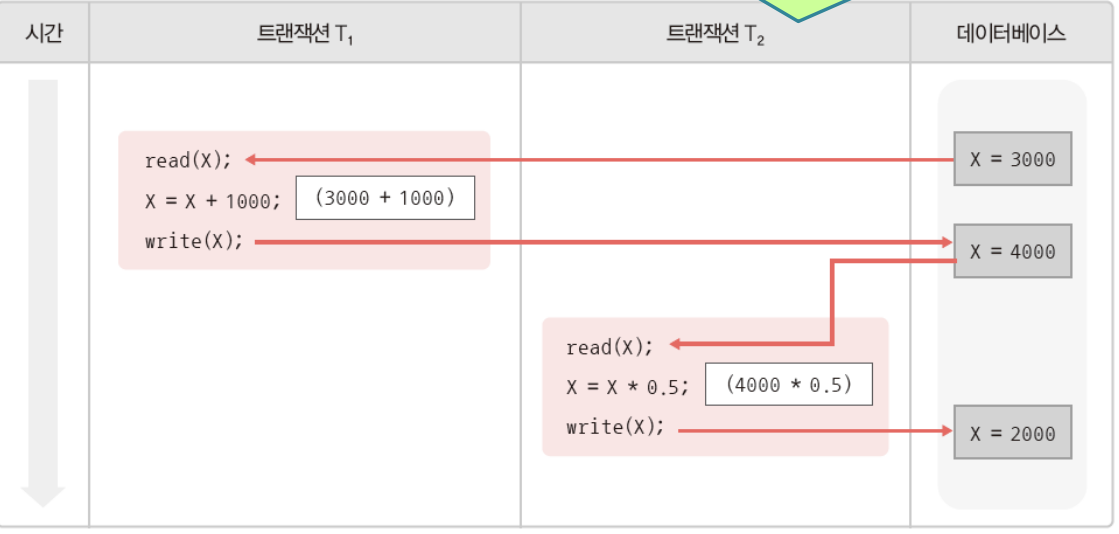
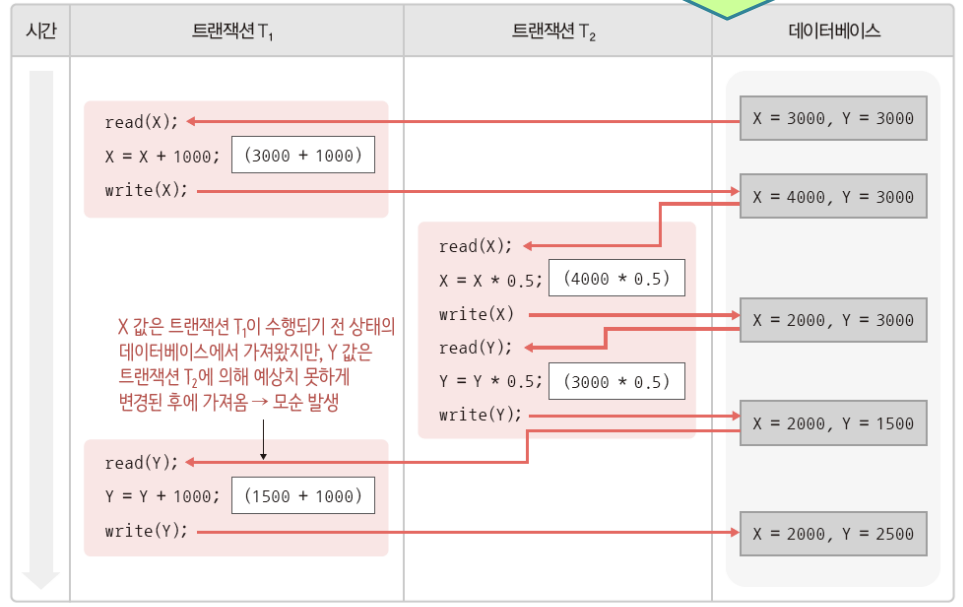
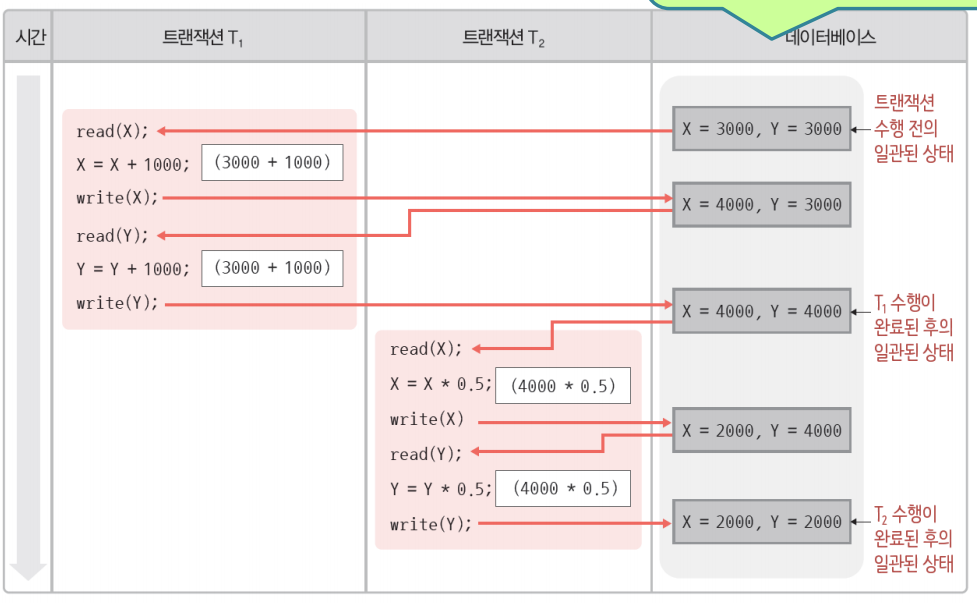
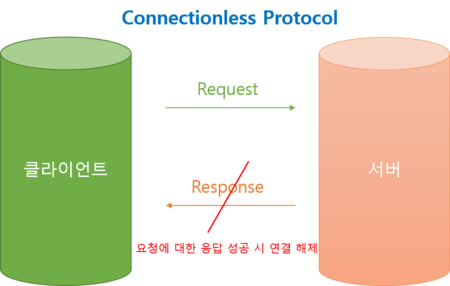
메모리 버퍼의 경계가 있는데 경계와 관련된 연산에 대한 제한, 제약을 적절히 처리하지 못할때 생길 수 있는 약점
어떤 소프트웨어는 메모리 버퍼와 관련된 연산을 할 수 있다.
하지만 그 연산은 버퍼의 의도된 경계 바깥쪽의 영역을 read/wrtie할 수 있음
연산의 제약조건은 버퍼의 의도된 경계내에서 연산해야
버퍼의 경계내의 메모리를 읽고 쓰기 해야됨
어떤 언어는 직접적으로 메모리 위치를 참조하는데 그 위치가 실제로 유효한지 아닌지 확인 하지 않음
프로그램이 참조할 수 있는 유효한 주소인지 체크하지 않아 다른 변수나 자료구조 내부 프로그램 메모리 영역을 읽거나 쓸 수 있음 = >연산 제약을 제대로 처리 하지 않았기 때문에
공격으로 연결되면 임의의 코드를 실행할 수 있고 임의의 제어흐름으로 변조, 민감한 정보 읽기, 시스템이 망가짐
cwe 119 = > 버퍼 오버플로우라고도 함
버퍼 오버플로우는 사람마다 다른 의미로 사용가능
어떤 도구는 버퍼의끝을 넘어서서 write하는것
다른 개발자는 버퍼의 경계밖(버퍼의 시작점, 끝 밖의 공간)에서 읽거나 쓰는것.
또 어떤 사람들은 버퍼의 끝 이후에 어떠한 행동을 하는 것(읽기, 쓰기 가능)
사람마다 다르기때문에 혼란스러운 용어임
따라서 메모리 경계에서 부적절한 연산 제한이 올바른 표현이다.'
이러한 약점의 결과는 CIA가 깨짐
인가되지 않은 코드,명령실행, 메모리 변조 가능
한바이트만 조작할 수 있음
가용성, 기밀성
어떤 메모리를 읽을수 잇고 시스템이 비정상적으로 종료될수 잇음 (dos) cpu같은 자원을 소모(메모리도 가능)
메모리 경계를 넘어서면 메모리의 붕괴를 가져와 시스템이 붕괴됨
해당 프로그램이 공격을 받아서 무한루프상태로 갈수도 있다.
기밀성
read memory
주어진 자료구조 범위를 넘어서서 읽으면 민감한 정보를 읽을 수도 잇다.
메모리의 현재 버퍼의 위치와 같은 정보
어떻게 완화??
소프트웨어 보안은 개발생명 전 주기에서 고려
각 단계에서 취약점을 완화할 숭 ㅣㅆ다
요구사항분석 => 언어선택을 잘 해야. cwe119에 강한 언어를 사용하며 ㄴ좋다, c보단 자바와 같은 언어(자체적으로 메모리 관리를 함) ada나 c#은 오버플로우 보호기법을 적용하고 잇음
그렇지만 이러한 언어들은 binary가 아님 실제 실행시 native코드로 변환 되어야함. 따라서 native code와 상호작용하는 인터페이스는 오버플로우 약점에 취약(자바 가상머신은 c로 만들어져잇음)
언어를 윗단에서 좋은 언어를 사용하더라도 완전하게 해결하는 것은 아님
아키텍쳐및 설계
라이브러리나 프레임워크를 잘 사용
검증이된 라이브러리나 프레임 워크 사용 => safe c String 라이브러리, strsafe.h
string 관련 오버플로우 문제를 해결 => 완벽X
많은 오버플로우는 string고 ㅏ연관 없음, 하지만 string관련 문제를 해결가능
cwe119취약점을 방어할 숭 ㅣㅆ다.
빌드 컴파일 단계
컴파일 할때 최신 컴파일러사용, 컴파일 옵션을 버퍼 오버플로우를 탐지할 수 잇게 사용
MS visual studio 에선 GS flag, Fedora/red hat에선 fortify source gcc flag사용
공격이나 취약점을 조기에 탐지할 숭 ㅣㅆ음
하지만 완변하지 ㄴ않음
구현단계
자신이 작성중인 버퍼가 원하는 대로 작동하는지 두번이상 확인
strcpy -> strncpy
gets->fgets
memcpy보다 안전한 것 사용
안전한 라이브러리 함수 사용
운영단계
운영 환경을 좀더 안전하게 만들어라
관리자는 aslr , position-independent executable (pie)와 같은 기능을 사용해서 특정한 주소를 공격자가 예측하지 못하게 해라
공격자는 버퍼의 주소를 예측하기 어려움
NX비트 활용 (hw기법)
임의의 코드가 스택이나 데이터 세그먼트에 들어갈 확률이 높은데, data execution protection(nx) 를 하면 코드 세그먼트가 아닌 스택이나 데이터 세그먼트 코드는 실행하기 못하게함.기본적으로 프로세스의 메모리 레이아웃에서는 코드, 텍스트 세그먼트의 코드만 실행해야함. 공격자들은 자기가 실행하고 싶은 코드를 스택이나 ㄴ=데이터 세그먼트에 넣음,
# -*- coding: utf-8 -*-
"""
Created on Mon Feb 22 14:47:47 2021
@author: changmin
"""
'''
msg = "It is Time"
print(msg.upper()) #대문자로 결과물만, msg는 그대로
print(msg.lower()) # 결과물만 소문자로
print(msg)
tmp = msg.upper()
print(tmp)
print(tmp.find('T')) # 문자열에서 해당 문자 인덱스 번호 반환(처음 발견한)
print(tmp.count('T')) # 문자열에서 해당 문자 개수 반환
print(msg[:2]) # 슬라이싱 => 처음부터 2개만
print(msg[3:5]) # 3번 인덱스부터 4번 인덱스 까지
print(len(msg)) # 문자열 길이 반환
for i in range(len(msg)):
print(msg[i], end =" ") # 옆으로 출력
print()
for x in msg:
print(x, end = " ")
print()
for x in msg:
if x.isupper():
print(x, end =' ')
elif x.islower():
print(x, end = ' ')
print('\n\n')
for x in msg:
if x.isalpha():
print(x, end=' ')
print()
tmp = 'AZ'
for x in tmp:
print(ord(x)) # 아스키 넘버 출력
tmp =65
print(chr(tmp))
'''
'''
리스트와 내장함수(1)
'''
'''
import random as r
a=[]
print(a)
b = list()
a=[1, 2, 3, 4, 5]
print(a)
print(a[0])
b = list(range(1, 11))
print(b)
c=a+b
print(c)
print('\n\n\n')
print(a)
a.append(6)
print(a)
a.insert(3, 7) # 3번 인덱스에 7넣음
print(a)
a.pop() # 맨 뒤 인덱스 없앰
print(a)
a.pop(3) # 3번 인덱스 없앰
print(a)
a.remove(4) # 4라는 값 제거
print(a)
print(a.index(5)) # 5라는 값이 있는 인덱스 번호를 반환
d=list(range(1, 11))
print(d)
print(sum(d)) # 리스트 안의 합을 반환
print(max(d)) # 리스트중 가장 큰값 찾아줌
print(min(d)) # 작은값 반환
print(min(7, 5)) # 인자값들 중 최소값을 찾아줌
print(min(7, 3, 5))
print(d)
r.shuffle(d) # 값 섞음
print(d)
d.sort() # 오름차순
print(d)
d.sort(reverse = True) # 내림차순
print(d)
d.clear() # 리스트 값들 다 삭제
print(d)
'''
'''
'''
#리스트와 내장함수 2
'''
a =[23, 12, 36, 53, 19]
print(a[:3]) # 슬라이싱
print(a[1:4])
print(len(a)) # 길이 출력
for i in range(len(a)):
print(a[i], end=' ')
print()
for x in a:
print(x, end = ' ')
print()
for x in a:
if x%2 == 1:
print(x, end = ' ')
print()
# 튜플로 출력
# enumerate => (0,23) (1,36) ..... (4,19)
for x in enumerate(a):
print(x[0], x[1])
for index, value in enumerate(a):
print(index, value)
print()
# all => 모두 참이면 참을 리턴
if all(50>x for x in a):
print('Yes')
else:
print('No')
# any => 한번이라도 참이면 참
if any(15>x for x in a):
print('Yes')
else:
print('No')
'''
#튜플
'''
b=(1, 2, 3, 4, 5)
print(b[0])
#b[0]=7 # 에러 튜플의 값은 변경 불가, 리스트의 값은 변경가능
#print(b[0])
'''
"""
'''
2차원 리스트 생성과 접근
'''
a= [0]*3
print(a)
a = [[0]*3 for _ in range(3)] # 크기가 3인 일차원 리스트 언더바는 변수없이 반복문만 돔 => 일차원 리스트 3번 만듦
a[0][1] = 2
print(a)
print()
#표처럼 출력
for x in a:
print(x)
for x in a:
for y in x:
print(y, end =' ')
"""
'''
람다 함수 => 함수 이름이 없음
'''
'''
def plus_one(x):
return x+1
print(plus_one(1))
'''
plust_two = lambda x: x+2
print(plust_two(1))
a = [1, 2, 3]
# map => 함수명, 자료 =>
def plus_one(x):
return x+1
print(plus_one(1))
print(list(map(plus_one, a))) # a에 대해 plus one을 함
print(list(map(lambda x:x+1, a))) # a에 대해 plus one을 함
#mysql - python connection test
import pymysql #mysql과 연동하기 위해
#필요한 기본 DB 정보
host = "localhost"
user = "root"
pw = "XXXX"
db = "my_db"
#DB에 접속
conn = pymysql.connect(host= host, user = user, password = pw, db = db)
#사용할 sql문
sql = "SELECT * FROM emp LIMIT 10"
# sql문 실행/데이터 받기
curs = conn.cursor() #sql 실행시 결과를 담고 있는 버퍼를 정렬
curs.execute(sql) #앞의 sql문 실행
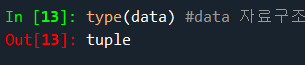
data = curs.fetchall() #sql실행결과 모두 가져오기, fetchall 모든 행 가져옴, fetchone은 하나의 행만 가져옴
type(data) #data 자료구조
data #data 내용출력
data[0] #첫번째 행
str(data[0][0]) #첫번째 행의 첫번째 컬럼
#db 접속 종료
curs.close()
conn.close()
import sys
import pymysql
from PyQt5.QtWidgets import *
def connectDB():
#필요한 db 정보
host = "localhost"
user = "root"
pw = "Changmin97"
db = "my_db"
#db 접속
conn = pymysql.connect(host=host, user =user, password =pw, db =db)
return(conn) #connection 리턴
def disconnectDB(conn):
conn.close()
class MyApp(QWidget):
def __init__(self):
super().__init__()
self.initUI()
# UI 디자인 함수
def initUI(self):
#QLable 문자열 출력
label1 = QLabel('ID')
label2 = QLabel('ename')
label3 = QLabel('job')
label4 = QLabel('department')
#self => 외부에서 접근 가능
#text박스 생성 = QTextEdit
self.text_id = QTextEdit()
self.text_id.setFixedWidth(200)
self.text_id.setFixedHeight(30)
#버튼 생성, 버튼 클릭시 btn_1_clicked 실행
btn_1 = QPushButton('Query')
btn_1.clicked.connect(self.btn_1_clicked)
#text박스 생성 = QTextEdit
self.text_ename = QTextEdit()
self.text_ename.setFixedWidth(200)
self.text_ename.setFixedHeight(30)
#text박스 생성 = QTextEdit
self.text_job = QTextEdit()
self.text_job.setFixedWidth(200)
self.text_job.setFixedHeight(30)
#text박스 생성 = QTextEdit
self.text_dept = QTextEdit()
self.text_dept.setFixedWidth(200)
self.text_dept.setFixedHeight(30)
#화면 배치, grid를 만들어 배치
gbox = QGridLayout()
gbox.addWidget(label1,0,0)
gbox.addWidget(self.text_id, 0, 1)
gbox.addWidget(btn_1, 0, 2)
gbox.addWidget(label2,1,0)
gbox.addWidget(self.text_ename, 1, 1)
gbox.addWidget(label3,2,0)
gbox.addWidget(self.text_job, 2, 1)
gbox.addWidget(label4,3,0)
gbox.addWidget(self.text_dept, 3, 1)
self.setLayout(gbox)
self.setWindowTitle('My Program')
self.setGeometry(300, 300, 480,250) #창뜨는 위치, 크기
self.show()
#버튼 클릭 처리
def btn_1_clicked(self):
#사용자가 입력한 값 받아서 empno 저장
empno = self.text_id.toPlainText()
sql = "SELECT ename, job, danme \
From emp e, dept d\
where e.deptno = d.deptno\
and empno = "+ empno
#ex) ename '"+ename+"'" =>문자일 경우 따옴표 주의!
conn = connectDB()
curs = conn.cursor()
curs.execute(sql)
result = curs.fetchone() # sql 실행 결과 가져오기
self.text_ename.setText(result[0])
self.text_job.setText(result[1])
self.text_dept.setText(restul[2])
curs.close()
disconnect(conn)
#END Class
#프로그램 실행, class를 생성하고 실행
if(__name__ == '__main__'):
app = QApplication(sys.argv)
ex = MyApp()
sys.exit(app.exec_())
ex 1)
- 사원번호가 7521인 사원의 이름을 출력한다
- 이름이 SCOTT 인 사원의 부서이름을 출력한다
- 담당업무가 SALESMAN 인 모든사원의 이름을 출력한다.
- 모든 부서의 이름을 출력한다.
import pymysql #mysql과 연동하기 위해
#필요한 기본 DB 정보
host = "localhost"
user = "root"
pw = "Changmin97"
db = "my_db"
#DB에 접속
conn = pymysql.connect(host= host, user = user, password = pw, db = db)
#사용할 sql문
sql1 = "SELECT ename FROM emp WHERE empno=7521"
sql2 = "SELECT dname FROM emp, dept WHERE dept.deptno=emp.deptno and ename='scott'"
sql3 = "SELECT ename FROM emp WHERE job='salesman'"
sql4 = "SELECT dname FROM dept"
querys = [sql1, sql2, sql3, sql4]
for sql in querys:
print(sql)
# sql문 실행/데이터 받기
curs = conn.cursor() #sql 실행시 결과를 담고 있는 버퍼를 정렬
curs.execute(sql) #앞의 sql문 실행
row = curs.fetchone() #sql실행결과 모두 가져오기, fetchall 모든 행 가져옴, fetchone은 하나의 행만 가져옴
while(row):
print(row)
row = curs.fetchone()
print("==========================================================")
#db 접속 종료
curs.close()
conn.close()
ex 2)
Mysql 의 world 데이터베이스와 연동하여 다음과 같이 국가명을 입력하면 해당 국가의 정보를 출력하는 윈도우 프로그램을 작성하시오
- 매치되는 국가가 없으면 모든 항목에 공백 출력
import sys
import pymysql
from PyQt5.QtWidgets import *
def connectDB():
#필요한 db 정보
host = "localhost"
user = "root"
pw = "Changmin97"
db = "world"
#db 접속
conn = pymysql.connect(host=host, user =user, password =pw, db =db)
return(conn) #connection 리턴
def disconnectDB(conn):
conn.close()
class MyApp(QWidget):
def __init__(self):
super().__init__()
self.initUI()
# UI 디자인 함수
def initUI(self):
#QLable 문자열 출력
label1 = QLabel('Country name')
label2 = QLabel('Continent')
label3 = QLabel('Population')
label4 = QLabel('GNP')
label5 = QLabel('Captial city')
label6 = QLabel('Language')
#text_Country_name
self.text_Country_name = QTextEdit()
self.text_Country_name.setFixedWidth(200)
self.text_Country_name.setFixedHeight(30)
#버튼 생성, 버튼 클릭시 btn_1_clicked 실행
btn_1 = QPushButton('Query')
btn_1.clicked.connect(self.btn_1_clicked)
#text_Continent
self.text_Continent = QTextEdit()
self.text_Continent.setFixedWidth(200)
self.text_Continent.setFixedHeight(30)
#text_Population
self.text_Population = QTextEdit()
self.text_Population.setFixedWidth(200)
self.text_Population.setFixedHeight(30)
#text_GNP
self.text_GNP = QTextEdit()
self.text_GNP.setFixedWidth(200)
self.text_GNP.setFixedHeight(30)
#text_Captial_city
self.text_Captial_city = QTextEdit()
self.text_Captial_city.setFixedWidth(200)
self.text_Captial_city.setFixedHeight(30)
#text_Language
self.text_Language = QTextEdit()
self.text_Language.setFixedWidth(200)
self.text_Language.setFixedHeight(30)
#화면 배치, grid를 만들어 배치
gbox = QGridLayout()
gbox.addWidget(label1,0,0)
gbox.addWidget(self.text_Country_name, 0, 1)
gbox.addWidget(btn_1, 0, 2)
gbox.addWidget(label2,1,0)
gbox.addWidget(self.text_Continent, 1, 1)
gbox.addWidget(label3,2,0)
gbox.addWidget(self.text_Population, 2, 1)
gbox.addWidget(label4,3,0)
gbox.addWidget(self.text_GNP, 3, 1)
gbox.addWidget(label5,4,0)
gbox.addWidget(self.text_Captial_city, 4, 1)
gbox.addWidget(label6,5,0)
gbox.addWidget(self.text_Language, 5, 1)
self.setLayout(gbox)
self.setWindowTitle('Country Info')
self.setGeometry(300, 300, 480,250) #창뜨는 위치, 크기
self.show()
#버튼 클릭 처리
def btn_1_clicked(self):
#사용자가 입력한 값 받아 저장
Country_name = self.text_Country_name.toPlainText()
sql = "SELECT country.name, continent, country.population, gnp, city.name, language \
From country, city, countrylanguage\
where country.code = city.countrycode \
and country.code = countrylanguage.countrycode\
and country.capital=city.id\
and IsOfficial = 'T' \
and country.name ="+"'"+Country_name+"'"
#ex) ename '"+ename+"'" =>문자일 경우 따옴표 주의!
conn = connectDB()
curs = conn.cursor()
curs.execute(sql)
result = curs.fetchone() # sql 실행 결과 가져오기
if result:
self.text_Country_name.setText(result[0])
self.text_Continent.setText(result[1])
self.text_Population.setText(str(result[2]))
self.text_GNP.setText(str(result[3]))
self.text_Captial_city.setText(result[4])
self.text_Language.setText(result[5])
else:
self.text_Country_name.setText("") #매치되는 국가가 없으면 모든 항목에 공백 출력
curs.close()
disconnect(conn)
#END Class
#프로그램 실행, class를 생성하고 실행
if(__name__ == '__main__'):
app = QApplication(sys.argv)
ex = MyApp()
sys.exit(app.exec_())
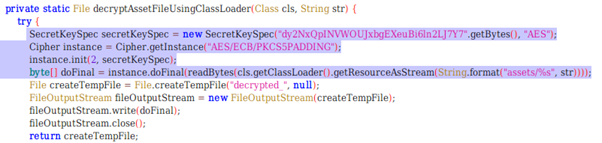
jadx로 같은 파일을 확인하면, class의 이름이 Base64Coder에서 pabd63bb로 바뀐 것을 알 수 있다.
class renaming은 class의 이름를 "Base64Coder"처럼 식별할 수 있는 문자대신, "pabd63bb"와 같이 무슨 의미인지 알 수 없게 바꾸어준다. 따라서 역공학으로 해당 파일을 보더라도 무슨 역할을 하는 지 알아차리기 힘들어 역공학을 방해한다. [1]
처음에 메소드의 끝을 가리키는 goto가 있고, 메소드 끝에 메소드의 처음을 가리키는 goto가 추가되었다.
백신탐지 비교
(왼쪽 : 기존앱, 오른쪽 : Goto옵션 적용)
- Reorder
Reorder는 역공학하여 분석하기 어렵도록, 메소드의 명령어 흐름을 복잡하게 한다. 왼쪽의 그림이 Reorder된 app_3의 BandManager.smali이다. [2] 오른쪽의 기존과 method와 다르게 추가된 내용도 생기고 흐름도 goto문이 생기는 등 복잡하게 바뀐 것을 알 수 있다.
왼쪽의 Nop 옵션이 적용된 app_2/smali/c/ca/a.smali 파일을 보면 오른쪽의 기존 파일과 다르게 nop 명령어들이 추가된 것을 알 수 있다.
백신탐지 비교
(왼쪽 : 기존앱, 오른쪽 : nop 옵션 적용)
- ArithmeticBranch
ArithmetiBranch 옵션은 의미 없는 코드를 삽입하여 명령어 흐름을 복잡하게 만들다. 따라서 역공학시 분석을 하기 어렵게 한다. [2] 왼쪽의 ArithmeticBranch 옵션이 적용된 app_4/smali/com/example/eroplayer/MainActivity을 보면 오른쪽의 기존 파일과 다르게 junk code가 삽입된 것을 알 수 있다.
이번 과제를 하면서, 개발자의 자산을 보호하는 것도 중요하지만, 악성코드를 탐지를 위해 난독화를 탐지하는 기술도 중요하다고 느꼈다.
참고논문
[1] 난독화에 강인한 안드로이드 앱 버스마킹 기법 김 동 진 , 조 성 제° , 정 영 기* , 우 진 운**, 고 정 욱***, 양 수 미**** Android App Birthmarking Technique Resilient to Code Obfuscation Dongjin Kim , Seong-je Cho° , Youngki Chung* , Jinwoon Woo**, Jeonguk Ko***, Soo-mi Yang****
[2] 안드로이드 어플리케이션 역공학 보호기법 하 동 수*, 이 강 효*, 오 희 국*
[4] Android Code Protection via Obfuscation Techniques: Past, Present and Future Directions Parvez Faruki, Malaviya National Institute of Technology Jaipur, India Hossein Fereidooni, University of Padua, Italy Vijay Laxmi, Malaviya National Institute of Technology Jaipur, India Mauro Conti, University of Padua, Italy Manoj Gaur, Malaviya National Institute of Technology Jaipur, India
CREATE FUNCTION f_mgr (e_name varchar(10))
RETURNS varchar(10)
BEGIN
declare manager varchar(10);
select m.ename into manager
from emp e, emp m
where e.mgr=m.empno and e.ename = e_name;
RETURN manager;
END
(2) 부서번호를 입력하면 부서의 위치를 출력하는 함수를 작성하시오 (f_loc)
다음과 같이 함수를 테스트한 결과를 보이시오.
select empno, ename, job, f_loc(deptno) as loc
from emp
CREATE FUNCTION f_loc (d_no int)
RETURNS varchar(10)
BEGIN
declare d_loc varchar(10);
select loc into d_loc
from dept
where deptno = d_no;
RETURN d_loc;
END
1. 사원번호를 매개변수로 입력 받아 사원번호, 이름, 담당업무, 연봉, 소속부서명을 보여주는 stored procedure 를 작성하시오 (p_emp_sel_1)
CREATE PROCEDURE p_emp_sel_1(id int)
BEGIN
select empno, ename, job, sal, dname from emp, dept
where emp.deptno=dept.deptno and empno = id;
END
2. 부서번호, 부서명, 위치를 매개변수로 입력 받아 새로운 부서 정보를 생성하는 stored procedure 를 작성하시오 (p_dept_insert_1)
CREATE PROCEDURE p_dept_insert_1(d_num int , d_name varchar(10), d_loc varchar(10))
BEGIN
insert into dept values(d_num, d_name, d_loc);
END
3. 사원번호, 사원 이름을 매개변수로 입력 받아 이름을 수정하는 stored procedure 를 작성하시오 (p_emp_update_1)
CREATE PROCEDURE p_emp_update_1 (e_num int, e_name varchar(10))
BEGIN
update emp set ename=e_name where empno = e_num;
END
1. 사원번호를 매개변수로 입력 받아 사원의 담당업무가 ‘CLERK’ 이면 급여를 20% 올리고, 아닌 경우는 10%를 올리는 stored procedure 를 작성하시오 (p_emp_update_2)
CREATE PROCEDURE p_emp_update_2 (e_num int)
BEGIN
declare e_job varchar(10);
select job into e_job
from emp
where empno=e_num;
if(e_job = 'clerk') then
update emp
set sal=sal*1.2
where empno=e_num;
end if;
if(e_job != 'clerk') then
update emp
set sal=sal*1.1
where empno=e_num;
end if;
END
2. 사원번호를 매개변수로 입력 받은 후에 그 사원이 속한 부서 사람들의 연봉 합계를 구하여 출력하는 stored procedure 를 작성하시오 (p_emp_sel_2)
CREATE PROCEDURE p_emp_sel_2 (e_num int)
BEGIN
select sum(sal)
from emp
where deptno = (select deptno from emp where empno = e_num);
END
3. 사원번호를 매개변수로 입력 받은 후에 사원의 급여가 평균급여 이상이면 해당 사원의 근무지를 보이고, 그렇지 않으면 사원의 직무를 보이는 stored procedure 를 작성 하시오. (p_emp_sel_3)
CREATE PROCEDURE p_emp_sel_3 (e_num int)
BEGIN
declare e_sal decimal(10,4);
declare avg_sal decimal(10,4);
select sal into e_sal
from emp
where empno=e_num;
select avg(sal) into avg_sal
from emp;
if(avg_sal <= e_sal) then
select loc from empd where empno=e_num;
else
select job from emp where empno=e_num;
end if;
END
=> 어플리케이션마다 복수의 SQL문 기술할 필요 없이 만들어진 저장 프로시저를 사용하면 다른 어플리케이션을 수정하여 컴파일 할 필요 없음.
=> 저장 프로시저는 만들어지는 순간에 구문이 검사됨, 따라서 DBA의 에러를 감소시킬 수 있음(실행전 검사)
=> SQL문을 직접 실행시킬 수 없는 사용자들도 저장 프로시저만 실행시킬 수 있는 권한을 가지게 할 수 있다.
단점
=> 접하기 어렵다.
=> DBMS 제품마다 문법이 다르다(비표준화)
=> 저장프로시저를 남발하는 경우 유지보수가 어렵다.
함수와의 차이점
저장프로시저 : 일반적으로 return 값이 없는 프로그램, CALL에 의해서 호출
함수 : return 값이 있는 프로그램, MAX(), min()과 같이 SQL문 안에서 사용됨
- 저장 프로시저 생성
CREATE PROCEDURE 저장프로시저이름()
BEGIN
SQL문 1;
SQL문 2;
END
BEGIN ~ END 사이에 원하는 SQL문들을 작성하면 된다.
** 구분문자 문제
위와 같이 작성시 BEGIN ~ END안에서 SQL문이 작성이 덜 되었더라도 ;를 만나게되면 CREATE PROCEDURE 을 실행하게되어 완성되지 않은 상태로 저장프로시저가 생성된다.
CREATE PROCEDURE 저장프로시저이름(인수이름 자료형)
BEGIN
SQL문 1;
SQL문 2
END
와 같이 될 경우 MySQL 콘솔창은 ;이 입력되면 ;이전단계까지의 명령문을 실행하게 되기때문이다.
따라서
저장 프로시저에서 END를 입력하고난 뒤 CREATE PROCEFURE 명령이 실행되게 해야한다.
DELIMITER를 사용하여 구분문자를 ;대신 다른 문자로 변경한다.
EX) DELIMITER // 혹은 DELIMITER =
와 같이원하는 문자를 적으면 된다.
DELIMITER // =>구분 문자를 ;에서 //로 변경
CREATE PROCEDURE pr1()
BEGIN
SELECT * FROM tb;
SELECT * FROM tb1;
END
// =>//구분문자를 만났으므로 이전까지 입력된 명령을 수행
DELIMITER ; => 구분문자를 다시 ;로 변경
- 저장 프로시저 실행
CALL 저장프로시저이름;
ex) CALL pr1();를 실행하면
자동으로 SELECT * FROM tb;와 SELECT * FROM tb1;가 실행된다.
- 저장 프로시저 인수 사용
PROCEDURE 저장프로시저이름(인수이름 자료형);
예를 들어 sales가 200 이상인 값을 보려고 할때
select * from tb where sales>=d;와 같이 설정하면
DELIMITER //
CREATE PROCEDURE pr1(d INT)
BEGIN
SELECT * FROM tb WHERE sales>=d;
END
//
DELIMITER ;
d를 인자로 받아들여 pr1(200)을 실행하면
select * from tb where sales>=200;이 된다.
- 작성된 저장 프로시저 내용 표시
SHOW CREATE PROCEDURE 저장프로시저이름;
ex) SHOW CREATE PROCEDURE pr1;
pr1의 프로시저 내용을 볼 수 있게 된다.
- 저장 프로시저 삭제
DROP PROCEDURE 저장프로시저이름;
- 저장 함수
저장 프로시저와 유사하지만, 실행했을 때 값을 반환한다.
CREATE FUNCTION 저장함수이름(인수이름 자료형) RETURNS 반환값자료형
BEGIN
SQL문 ....
RETURN 반환값식
END
* DECLARE
저장 함수에서 변수를 사용하려면 DECLARE로 정의해야한다.
DECLARE 변수이름 자료형;
예시를 보면
CRETAE FUNCTION func() RETURNS DOUBLE => 함수의 반환형은 double
BEGIN
DECLARE r DOUBLE; => 변수 r 선언
SELECT AVG(sales) INTO r FROM tb; => AVG(sales)값을 r에 저장
RETURN r; => r을 반환
END
- 저장함수 삭제
DROP FUNCTION 저장함수이름;
- 저장함수 내용 표시
SHOW CREATE FUNCTION 저장함수이름;
저장 함수의 내용을 볼 수 있게된다.
- 트리거
테이블에 대해 어떤 처리를 실행하면 이에 반응하여 설정한 명령이 자동으로 실행되는 구조
INSERT, UPDATE, DELETE 등 명령이 실행될 때, 트리거로 설정한 명령이 자동으로 실행되게 할 수 있다.
EX) 테이블의 레코드 변경시, 변경한 내용을 다른 테이블에 기록하도록 트리거를 만들 수 있음
따라서 트리거는 처리를 기록하거나, 처리가 실패할 경우를 대비하여 만들어 놓으면 좋다.
트리거는 INSERT, UPDATE, DELETE 등 명령이 실행되기 직전(BEFORE) 또는 직후(AFTER)에 호출되어 실행된다.
즉, 어떤 데이터를 처리하기 전에 호출되거나 어떤 데이터를 처리한 후에 호출된다.
또한 테이블에서 어떤 데이터를 처리하기 전의 값은 OLD.칼럼이름.
처리한 후의 값은 NEW.칼럼이름으로 얻을 수 있다.(추출할 수 있다.)
명령에 따라서 칼럼 값을 추출할 수도 있고 없을 수도 있다.
명령
실행전(old.칼럼이름)
실행후(new.칼럼이름)
insert
old.칼럼이름 추출 불가
가능
delete
가능
new.칼럼이름 추출불가
update
가능
가능
- 트리거 생성
CREATE TRIGGER 트리거이름 BEFORE(또는 AFTER) DELETE(UPDATE,INSERT 등과 같은 명령)
ON 테이블 이름 FOR EACH ROW
BEGIN
변경전(OLD.칼럼이름)을 이용한 처리 ====> 또는 변경후(NEW.칼럼이름)
END
EX) tb1에서 삭제한 레코드를 tb1m에 삽입하는 트리거 작성
DELIMITER //
CREATE TRIGGER tr1 BEFORE DELETE ON tb1 FOR EACH ROW
===> delete에 반응, 삭제하기 직전의 값을 넣으므로 before, for each row 각 행에 대해 수행
BEGIN
INSERT INTO tb1m VALUES(OLD.number, OLD.name, OLD.age);
END
//
DELIMIER ;
tb1에서 레코드가 삭제될때, tb1m에 삭제된 레코드가 입력되게 된다.
DELETE FROM tb1;을 하여 모든 레코드를 삭제하더라도 tb1m에 삭제된 레코드들이 저장되게 된다.
따라서 INSERT INTO tb1 SELECT * FROM tb1m;과 같이 다시 복원을 할 수도 있다.
* de-obfuscator : 난독화된 악성코드를 분석시 사용, 난독화를 해제시켜주는 도구
분석 지연
난독화
클래스, 메소드, 변수명 등을 의미 없는 문자나 식별할 수 없는 문자로 치환, 제어흐름 난독화
암호화
문자열, 리소스 등 암호화
코드 분리
핵심 로직이 담긴 코드를 분리하고 실행 중에 동적으로 적재
환경 탐지
디버거 탐지
프로세스 ID 확인, 디버깅 탐지 API 결과 값 반환
에뮬레이터 탐지
단말 ID, 전화번호, 빌드 값, IP 조사
플랫폼 해킹 탐지
OS 해킹 여부 확인
앱 변조 탐지
앱 위변조 여부, 앱 서명 값 확인
코드 난독화 기법 분류
- 레이아웃 난독화
예시) 식별자 난독화 (identifier renaming)
package iAmDriving{
public class LetsNavigate{...}
}
pacakge iAmConnecting {
public class MyBluetoothHandle{...}
}
pacakge userIsActive{
public class MainActivity{...}
}
|
V
package a{
public class a{...}
}
pacakge b {
public class b{...}
}
pacakge c{
public class c{...}
}
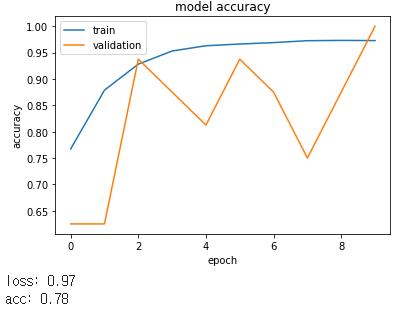
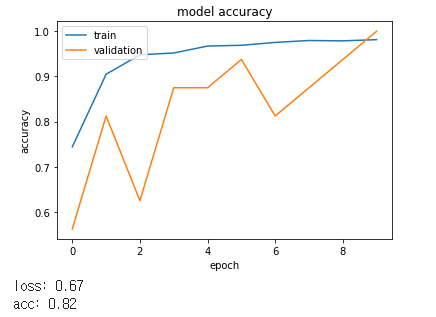
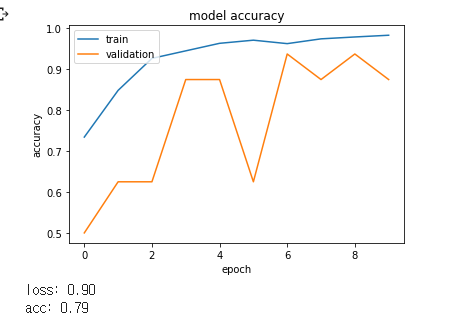
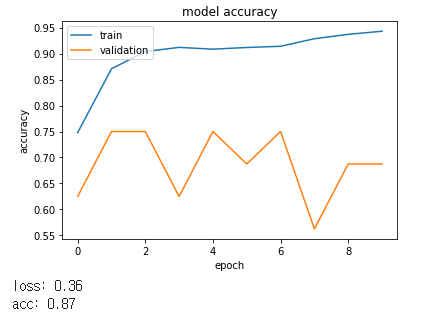
먼저 데이터를 X_train/y_train, X_test/y_test, X_val, y_val로 나누어 학습을 진행하였습니다.
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import Flatten
from keras.layers.convolutional import Convolution2D
from keras.layers.convolutional import MaxPooling2D
from keras.utils import np_utils
import numpy as np
import matplotlib.pyplot as plt
import os
import cv2
from tensorflow.python.keras.preprocessing.image import ImageDataGenerator
from tensorflow.python.keras.preprocessing.image import load_img, img_to_array
import numpy as np
from pathlib import Path
import glob
import pandas as pd
from skimage.io import imread # reading image as data
data_dir = Path('chest_xray')
train_dir = data_dir / 'train'
val_dir = data_dir / 'val'
test_dir = data_dir / 'test'
normal_cases_dir = train_dir / 'NORMAL'
pneumonia_cases_dir = train_dir / 'PNEUMONIA'
normal_cases_t = normal_cases_dir.glob('*.jpeg')
pneumonia_cases_t = pneumonia_cases_dir.glob('*.jpeg')
# Training data as a list
X_train = []
y_train = []
# Normal cases
for img in normal_cases_t:
img = cv2.imread(str(img))
img = cv2.resize(img, (224,224))
# Convert grayscale image
if img.shape[2] ==1:
img = np.dstack([img, img, img])
# CV2 uses BGR format, so we need to convert it to RGB
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# Normalizing the pixel values by dividing by its maximum
img = img.astype(np.float32)/255.
X_train.append(img)
y_train.append(0)
# Pneumonia cases
for img in pneumonia_cases_t:
img = cv2.imread(str(img))
img = cv2.resize(img, (224,224))
if img.shape[2] ==1:
img = np.dstack([img, img, img])
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = img.astype(np.float32)/255.
X_train.append(img)
y_train.append(1)
X_train = np.array(X_train)
y_train = np.array(y_train)
normal_cases_dir = val_dir / 'NORMAL'
pneumonia_cases_dir = val_dir / 'PNEUMONIA'
normal_cases_v = normal_cases_dir.glob('*.jpeg')
pneumonia_cases_v = pneumonia_cases_dir.glob('*.jpeg')
# Training data as a list
X_val = []
y_val = []
# Normal cases
for img in normal_cases_v:
img = cv2.imread(str(img))
img = cv2.resize(img, (224,224))
# Convert grayscale image
if img.shape[2] ==1:
img = np.dstack([img, img, img])
# CV2 uses BGR format, so we need to convert it to RGB
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# Normalizing the pixel values by dividing by its maximum
img = img.astype(np.float32)/255.
X_val.append(img)
y_val.append(0)
# Pneumonia cases
for img in pneumonia_cases_v:
img = cv2.imread(str(img))
img = cv2.resize(img, (224,224))
if img.shape[2] ==1:
img = np.dstack([img, img, img])
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = img.astype(np.float32)/255.
X_val.append(img)
y_val.append(1)
X_val = np.array(X_val)
y_val = np.array(y_val)
normal_cases_dir = test_dir / 'NORMAL'
pneumonia_cases_dir = test_dir / 'PNEUMONIA'
normal_cases_test = normal_cases_dir.glob('*.jpeg')
pneumonia_cases_test = pneumonia_cases_dir.glob('*.jpeg')
# Training data as a list
X_test = []
y_test = []
# Normal cases
for img in normal_cases_test:
img = cv2.imread(str(img))
img = cv2.resize(img, (224,224))
# Convert grayscale image
if img.shape[2] ==1:
img = np.dstack([img, img, img])
# CV2 uses BGR format, so we need to convert it to RGB
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# Normalizing the pixel values by dividing by its maximum
img = img.astype(np.float32)/255.
X_test.append(img)
y_test.append(0)
# Pneumonia cases
for img in pneumonia_cases_test:
img = cv2.imread(str(img))
img = cv2.resize(img, (224,224))
if img.shape[2] ==1:
img = np.dstack([img, img, img])
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = img.astype(np.float32)/255.
X_test.append(img)
y_test.append(1)
X_test = np.array(X_test)
y_test = np.array(y_test)
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import Flatten
from keras.layers.convolutional import Convolution2D
from keras.layers.convolutional import MaxPooling2D
seed = 100
np.random.seed(seed)
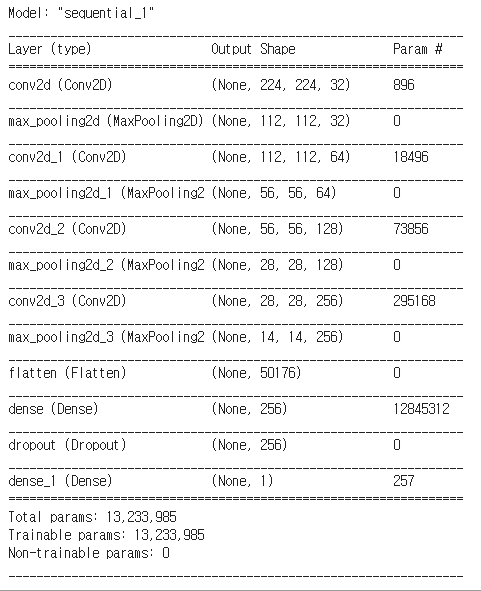
model=Sequential()
a=3
model.add(Convolution2D(32, kernel_size=(a, a), padding='same', strides=(1, 1), input_shape=(image_size, image_size, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Convolution2D(64, kernel_size=(a, a), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Convolution2D(128, kernel_size=(a, a), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Convolution2D(256, kernel_size=(a, a), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(256,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1,activation='sigmoid'))
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
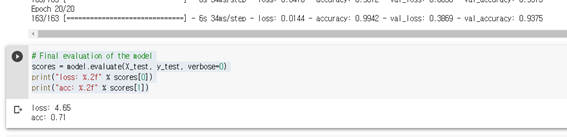
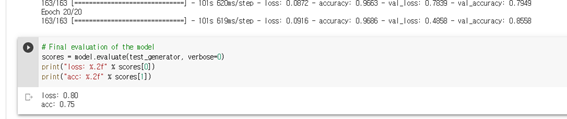
# Final evaluation of the model
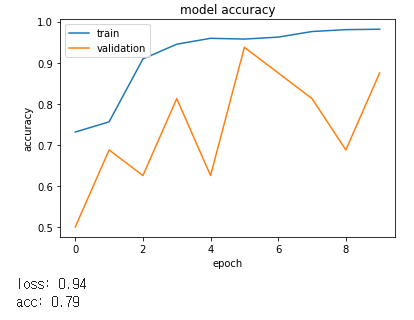
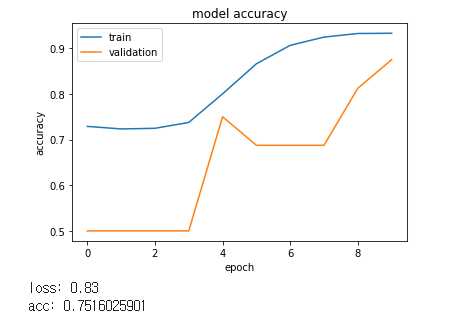
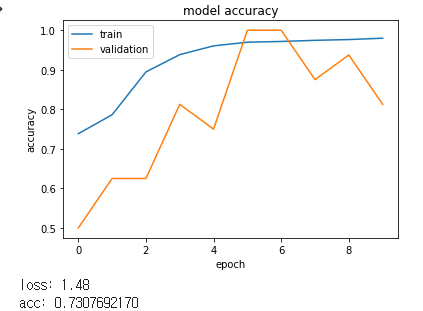
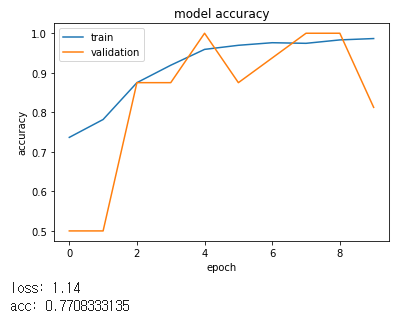
scores = model.evaluate(X_test, y_test, verbose=0)
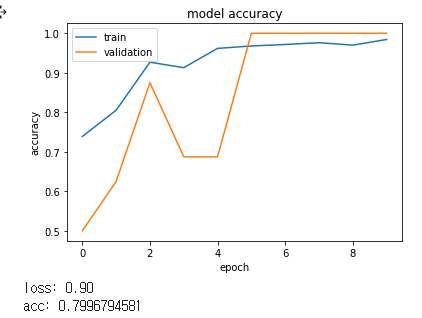
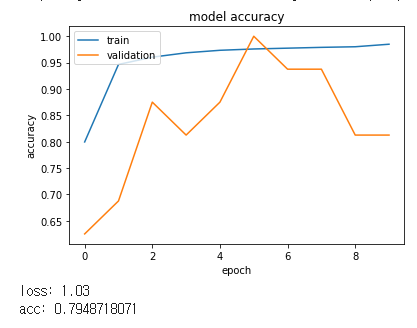
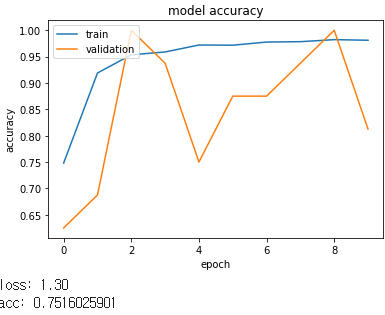
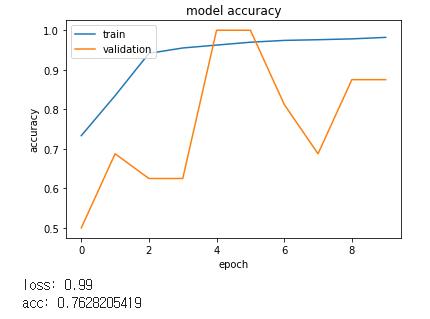
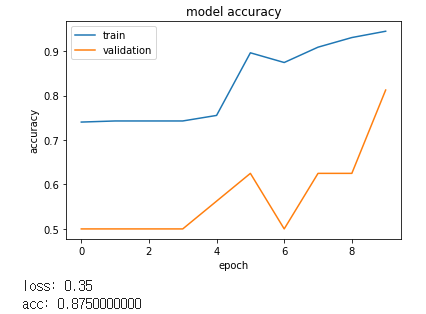
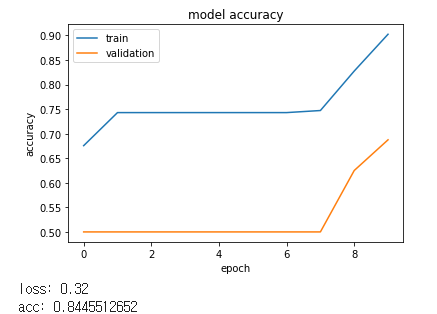
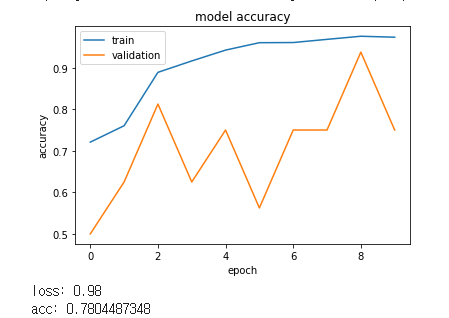
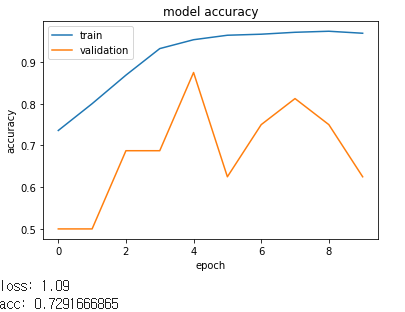
print("loss: %.2f" % scores[0])
print("acc: %.2f" % scores[1])
'''
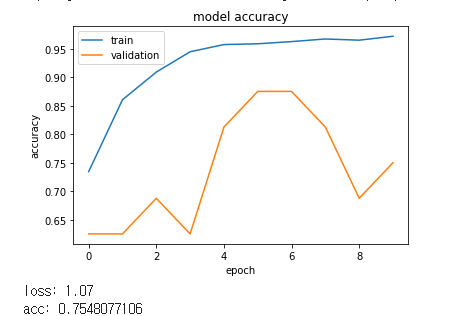
loss: 2.00
acc: 0.75
'''
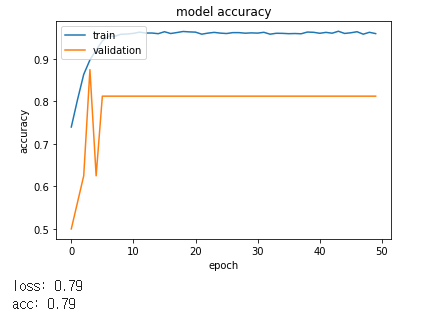
관련 자료를 찾던 중 ImageDataGenerator을 알게되었습니다.
CNN은 영상의 2차원 변환인 회전(Rotation), 크기(Scale), 밀림(Shearing), 반사(Reflection), 이동(Translation)와 같은 2차원 변환인 Affine Transform에 취약합니다.
즉, Affine Tranform으로 변환된 영상은 다른 영상으로 인식하므로, Data Generator를 사용하여 이미지에 변화를 주면서 컴퓨터의 학습자료로 이용하여 더욱 효과적이고 과적합을 방지하는 방식인, ImageDataGenerator으로 학습하도록 하였습니다.
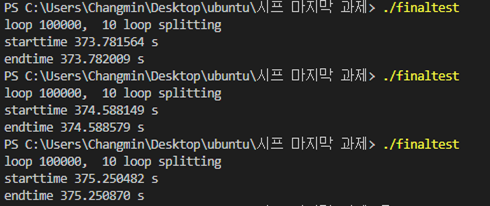
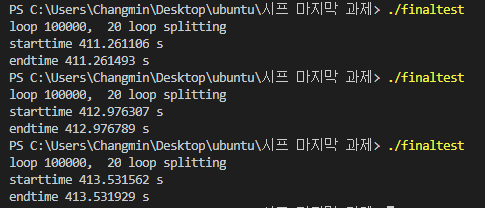
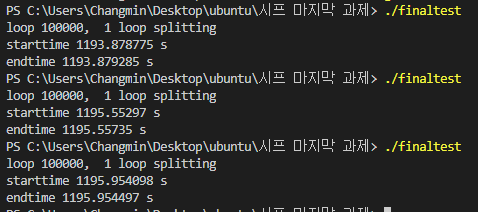
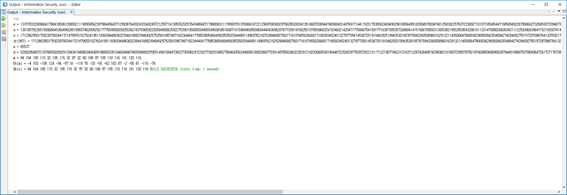
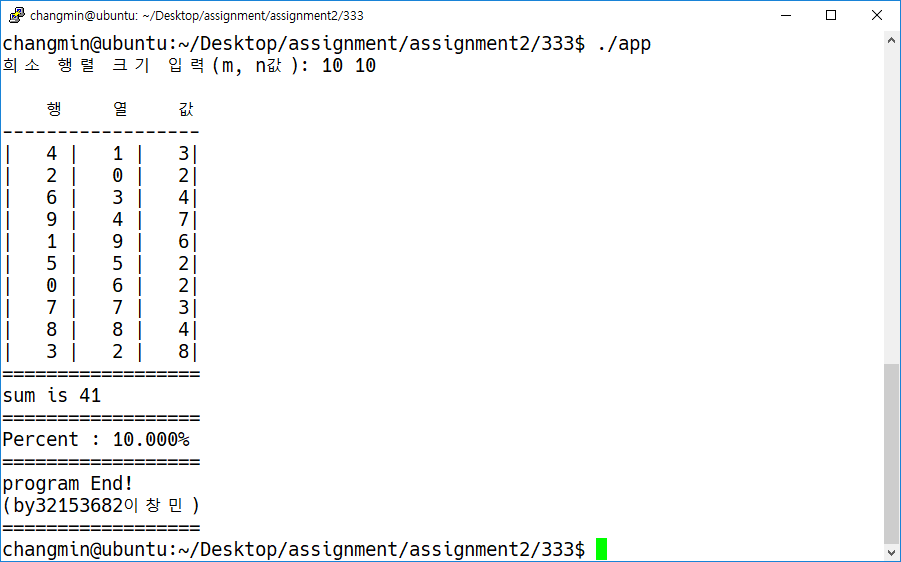
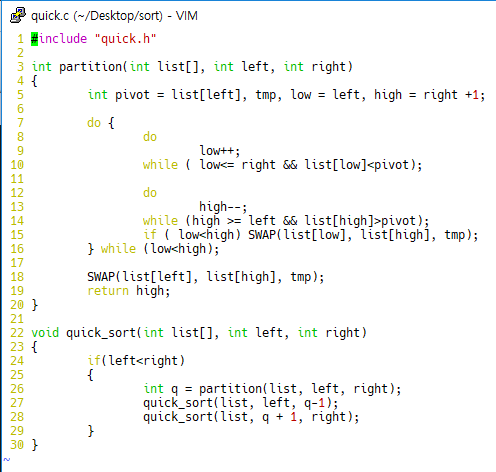
Problem 3: 주어진 희소행열을 표현하기 위한 적합한 자료구조를 기술하고 행열 내 모든 값의 합을 구하는 독립된 함수를 작성하시오.
1. 정수값을 입력 받아 희소행렬의 크기를 결정
2. 주어진 행렬내 원소의 약 10% 이하가 0이 아닌 값으로 임의 수를 생성 하여 대입
//h.h
int** insertRand(int** Matrix, int m);
int* NoDupRand(int* rand_num, int n);
int** createMatrix(int m, int n);
void printMatrix(int** Matrix, int m);
void showPercent(int** matrix, int m1);
void SumMatrix(int** matrix, int SparesMatrix_row);
//f.c
#include<stdio.h>
#include<stdlib.h>
#include<time.h>
#include<unistd.h>
#include"h.h"
void SumMatrix(int** matrix, int SparesMatrix_row) {
int m1, sum, size;
sum = 0;
size = SparesMatrix_row;
//matrix[] 갯수
for (m1 = 0; m1 < size; m1++) {
sum += matrix[m1][2];
}
printf("==================\n");
printf("sum is %d\n", sum);
printf("==================\n");
}
void showPercent(int** matrix, int matrix_size) {
int spares_size = matrix_size;
spares_size -= matrix[matrix_size - 1][3];
matrix_size /= 10;
float percent;
percent =((float)spares_size / (float)matrix_size);
//행렬안에 값이 0인 경우를 빼줌
printf("Percent : %0.3f%%\n", percent);
printf("==================\n");
}
void printMatrix(int** Matrix, int m) {
int m1, n1;
for (m1 = 0; m1 < m; m1++) {
for (n1 = 0; n1 < 3; n1++) {
if (n1 == 2) {
printf("|%4d|\n", Matrix[m1][n1]);
}
else
printf("|%4d ", Matrix[m1][n1]);
}
}
}
//중복되지 않는 랜덤값을 가져오기위해
int* NoDupRand(int* rand_num, int n) {
int index1, index2, i, temp;
srand(time(NULL));
//n번
for (i = 0; i < n; i++) {
rand_num[i] = i;
}
//섞기 n/2번
for (i = 0; i < (n / 2); i++) {
index1 = rand() % n;
index2 = i;
temp = rand_num[index1];
rand_num[index1] = rand_num[index2];
rand_num[index2] = temp;
}
return rand_num;
}
//(m x n) matrix
int** insertRand(int** Matrix, int m) {
int m1, n1;
int count;
int* NoDupRand_m;
int* NoDupRand_n;
NoDupRand_m = (int*)malloc(sizeof(int) * m);
NoDupRand_n = (int*)malloc(sizeof(int) * m);
NoDupRand_m = NoDupRand(NoDupRand_m, m);
sleep(1);
NoDupRand_n = NoDupRand(NoDupRand_n, m);
//원소를 넣을 (행,열)위치 생성
for (m1 = 0; m1 < m; m1++) {
//행(0~m-1) 열(0~n-1) 위치 저장
//랜덤값 중복체크를 하면 시간, 공간복잡도가 늘어남으로
//행과 열이 겹치는 경우
// 행 열 값 행 열값
//ex) [1][1][] [1][1][]
Matrix[m1][0] = NoDupRand_m[m1];
Matrix[m1][1] = NoDupRand_n[m1];
}
/* 0 1 3
0 [1][1][값1]
1 [1][1][값2]
.
.
n [n][m][ ]
위와 같은 경우 발생가능
*/
//배열에 n까지 값을 저장하고 섞음으로 랜덤값 중복체크보다 시간 줄임
//0이 아닌 원소가 10%라고 가정하고 만든행렬이므로
count = 0;
for (m1 = 0; m1 < m; m1++) {
Matrix[m1][2] = rand() % 10;
//printf("[%d][3] = %d\n", m1, Matrix[m1][2]);
if (Matrix[m1][2] == 0) {
count++;
}
}
//행열값
//[][][0]
//0값이 들어간 경우가 발생하는경우를 만들어줫으므로
//값이 0인 (행,열)의 갯수를 셈
Matrix[m-1][3] = count;
return Matrix;
}
int** createMatrix(int m, int n){
int** matrix;
int m1;
//10%이하여야하므로
m1 = (m * n) / 10;
matrix = (int**)malloc(sizeof(int*) * m1);
for (int m2 = 0; m2 < (m1 - 1); m2++) {
//행, 열, 값 3개
matrix[m2] = (int*)malloc(sizeof(int) * 3);
}
//0갯수 저장
matrix[(m1-1)] = (int*)malloc(sizeof(int) * 4);
return matrix;
}
//m.c
#include<stdio.h>
#include<stdlib.h>
#include<time.h>
#include<unistd.h>
#include"h.h"
void main() {
//mxn 행렬
int m, n;
int Msize;
int** spares_matrix;
float percent;
printf("희소 행렬 크기 입력(m, n값): ");
scanf("%d %d", &m, &n);
printf("\n");
Msize = (m * n / 10);
//희소행렬의 0이 아닌값만 저장할 행렬
//10%이하 여야함
spares_matrix = createMatrix(m, n);
spares_matrix = insertRand(spares_matrix, Msize);
printf(" 행 열 값\n");
printf("------------------\n");
printMatrix(spares_matrix, Msize);
//희소 행열의 덧셈 결과 비교 출력, 0이 아닌 비율 출력
SumMatrix(spares_matrix, Msize);
showPercent(spares_matrix, Msize);
printf("program End!\n(by32153682이창민)\n");
printf("==================\n");
}